Abstraction
论文中说这个percolator是用来进行增量处理的一个系统,用来替换MapReduce在google indexing system中的作用
但是没有提到transaction相关的东西
Introduction
考虑我们为网页构建索引的任务。索引系统首先会把每个网页都爬下来,如果有多个URL都指向了相同的内容,那么拥有最高的PageRank的URL会被保留下来放到索引中。我们还会把每一个链接对应的anchor text附在他指向的页面中。同时要保证对于链接指向的重复的内容,我们也会把它转发到PageRank最高的副本中
这个任务可以通过一系列的MapReduce来完成,一个用来聚合重复的页面,一个用来做链接反转。在MapReduce中,一个任务结束后才能开始另一个任务,所以在做链接反转的时候我们不需要考虑PageRank的变化
现在考虑这样的情况,我们重新爬取了一部分小的网页。要想计算新的PageRank,我们必须对整个集合做MapReduce,而不是新的这一部分增量。从而导致任务的规模是与整个仓库而非新增加的网页成比例的
我们可以通过把仓库存储在DBMS中,然后通过事务来帮助我们维护不变量(即多个副本指向PageRank最高的内容等)。虽然Bigtable有了可以处理这么多数据的能力,但是bigtable不能保证对于并发的操作去维护invariants
所以我们需要一个可以用来做增量处理的系统,我们可以每次爬取小部分的数据,然后可以并发的去更新他们
Percolator提供了SI的隔离级别。同时提供了observers。当系统发现一些用户指定的列变更的时候,他就会调用observer,每一个observer会完成他对应的任务,并且得到的结果会通过写入table从而导致下游的observer继续执行任务
Design
Percolator提供了两种抽象,一个是为分布式系统提供了ACID保证的事务,一个是observer,用来做增量计算
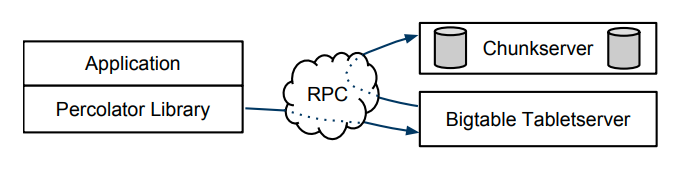
Percolator由三个东西组成,Percolator worker,Bigtable tablet server以及GFS chunk server
observer会通过RPC来在Bigtable上读写,然后Bigtable从而通过RPC来将数据存储在GFS上
这个系统还依赖两个小的设施,timestamp oracle以及lightweight lock service
timestamp oracle用来保证实现严格递增的timestamp,从而在实现SI中使用到
worker通过使用lightweight lock来使搜索dirty notifications更加高效(这块不明白,后面再看看)
Percolator的设计点在于在大规模机器上的执行,以及没有对latency的严格要求。从而让我们可以使用一个lazy的方法来清理transaction带来的锁。这种方式让transaction的提交时间延迟了数十秒,但是在indexing system中是可以忍受的。percolator没有一个中心化的事务管理位置,并且没有一个全局的死锁检测器。这会导致延迟的进一步增加,但是同时也允许我们在大规模数据上进行扩展。
Transactions

一个通过hash进行聚集重复的例子
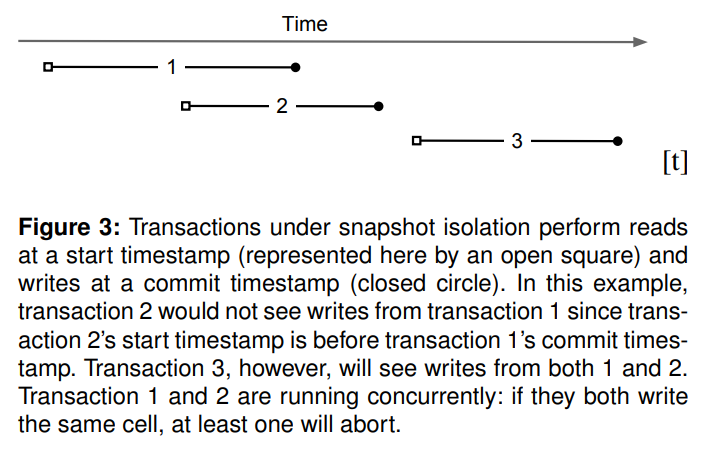
SI的一个例子,读取是看start timestamp,而写入则是在commit timestamp上
Percolator中的节点会直接更改bigtable中的状态,而且没有一个地方可以让我们很方便的维护锁。所以Percolator会显式的维护锁,并且保证锁不会受到机器故障的影响




transaction的构造函数会获得一个通过oracle获得一个timestamp作为start timestamp。用来决定Get的可见性。对于Set的操作会被缓存到write集合中,在commit的时候再去应用
对于commit写操作实际上是一个两阶段提交的操作,client用来做coordinater
在第一个阶段(prewrite)中,我们会锁定所有的元组,同时为了防止client的失效,我们会指定任意一个键作为primary。事务会首先读取每个要写的元组上的元数据,用来检测冲突。
如果有人在当前事务开始之后成功写入了该元组,或者有人已经锁上了这个元组,那么就会出现写写冲突,我们会中止当前事务。
如果没有冲突的话,我们就会在start timestamp上写入lock
如果没有元组产生了冲突,我们就会进入第二阶段,即提交阶段。首先我们会从oracle中获得一个timestamp作为commit timestamp。然后对于每一个写操作,我们会释放对应的锁,并写入一个指针指向真正数据的位置(是在prewrite阶段写入的数据)。一旦primary完成了写操作,那么这个事务就必须被提交
对于Get操作,他首先会检查[0, timestamp]中的lock,如果有lock说明有人在写入,那么我们就要等待直到他写入完成(因为我们要保证看到的是一致的快照,其实还是因为分布式情况下我们没法获得当前的活跃事务),大于timestamp的lock,无论如何我们都看不到,所以无所谓
如果client在提交的时候失效了,那么锁就会一直放在那,我们需要让Percolator去有方法清除这些锁。Percolator使用了一种lazy的方法,如果A发现了B的一个锁,他就可能认为B失效了,并且清除他对应的锁
然而A很难去很好的判断B是否失效了。所以我们必须防止只是A认为B失效了,而B实际没有失效这种情况。所以Percolator指定了primary,执行清除或者提交都需要我们在primary上进行操作。所以同时只会有一个操作成功。因此我们不会出现竞争的问题。
如果client在写入primary后失效了,我们就必须执行向前滚动。后来的事务可以通过检查对应的primary上的数据来决定是否向前滚动。对于向前滚动的操作,就是写入对应的write record
Percolator通过chubby判断worker是否活跃来确定事务是否被worker执行。同时他会在lock中写入wall time,如果一个锁的wall time很老,他也会被清理掉。而对于long-running commit的情况,他们会周期性的更新wall time。
Timestamps
oracle server必须要可以scale,因为我们整个系统都依赖oracle server分配时间戳
oracle server每过一段时间会从磁盘中分配一个范围的timestamp,这样后续的处理就可以直接在内存中进行。
并且每个worker会将timestamp的请求进行批处理,这样一次可以请求多个timestamp,并且不会受到RPC开销的影响
Percolator是怎么保证我们每次读都是读到的一致性快照呢?可以这样考虑:
如果我们能够读到一个事务的写操作,那么就有Tw < Tr,即读操作的start timestamp要大于写操作的commit timestamp。而Tw只有在所有的锁都写入成功后才会请求到,所以我们可以在分配Tr的时候,Tw对应的锁都已经写入了,所以后续的读取就一定可以读到所有Tw的写入。
后面的这个Notifications用处不大,就不在这里说了。主要目的是做增量计算用,而不是去维护数据的完整性

文章评论