Chubby lock service
chubby的目的就是为一些低耦合的分布式系统提供粗粒度的锁服务,以及可靠(但是低容量)的存储。
chubby提供的接口则类似于一个带有锁的分布式文件系统。但是chubby的设计重点在于可用性以及可靠性。而非高性能。
Introduction
lock service的目的是让客户去同步他们的活动,并且对一些信息达成一致。
我们希望chubby为一些系统提供粗粒度的锁服务,特别的是处理选主的问题。比如GFS通过chubby来指定一个master。bigtable也通过chubby选主,并且允许master
chubby的也用于存储一些小数据量的meta-data。他通常被用作一些分布式系统的根数据结构。比如bigtable的root table
chubby的核心不是提出创新点,而是engineering。论文主要在说他们的决策以及理由
Design
Rationale
google实现了一个paxos库,但是为什么要选择锁服务而不是直接用paxos来做共识呢?
某些情况下,开发者最开始去prototype一个东西的时候,他们的负载比较小。并且不需要高可用性。并且代码没有经过去为了共识协议调整他们的结构。当服务成熟的时候,这时候可用性比较重要了,他们需要进行为现有的系统加上replication以及选主。虽然这个目的可以通过共识协议库来解决,一个lock server可以让我们可以更加容易的维持现有代码的结构。
比如我们要去选择一个master。我们可以通过添加简单的语句来实现这个操作。首先一个server会尝试获得锁,从而变成master,并且传递一个额外的整数(lock acquisition count),以及一个if语句用来判断acquisition count是不是比当前值小,从而防止延迟的包影响当前的服务。
相当于是一定程度上解偶了consensus模块和逻辑模块。
第二点是通过name service来提供给用户读写文件的接口。但是他这块理由我有点看不懂...
第三点是程序员更熟悉基于锁的接口。因为大多数人都遇到过锁。
最后,如果我们直接使用consensus服务的话,需要副本来达成高可用性。比如一个用户系统用的是lock service,他们只需要一个副本就可以获得锁。但是如果用共识库的话则需要多个副本。举个例子就是比如我们有100个客户端,如果在这里面嵌入共识我们就要有100个对等点参与共识,并对维护的状态进行复制。而使用lock service的话,则数量与客户端的数量无关。从而减少了副本的数量。
所以感觉核心点还是解偶,把共识模块独立出来处理元信息。然后用锁服务来提供接口,并且提供读写元信息的能力。
客户期待知道什么时候主副本变化了,所以我们需要实现一种通知机制来防止用户不断的轮询。但是用户仍然可能需要不断的去访问chubby中的数据,并且chubby中的数据变化的很少。所以我们提供了对文件的缓存。(我猜测应该是去监视这个文件,然后当文件内容变化的时候去通知用户,从而保证缓存的一致性)
chubby使用coarse-grained lock。从而减少lock server的负载。同时可以减少lock server failure对于lock的影响。相对来说,细粒度的锁就更容易受到lock server failure的影响。
通过locking service,客户负责提供支持他们负载的服务器,而不是lock service,同时也从实现共识协议的复杂性中解脱出来。
System structure
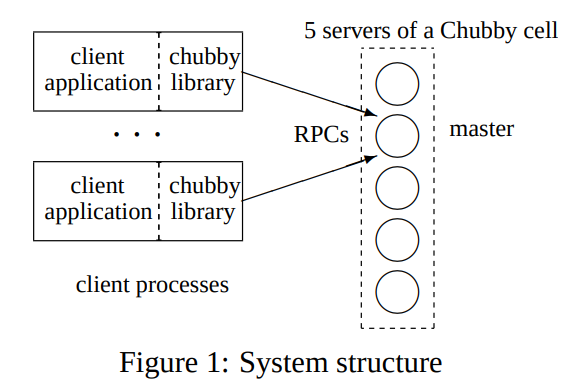
这里其实说的就是共识协议的一些实现,就不在这里多列了。
Files, directories, and handles
提供了UNIX类似的文件系统。文件和目录都是Node,Node可以是permanent或者是ephemeral的。对于ephermal的节点,如果没有客户端打开他们的时候他们就会被自动删除。ephermal的节点通常被用作临时文件,或者是用来标识他们对应的client还存活。
note的元数据有4个64位的整数:
1. instance number: 是一个比以前相同名字的node的instance number都大的数(用来去重)
2. content generation number: 看名字也可以看出来,用来标识文件内容改变的
3. lock generation number: 每次获得锁的时候就增加这个数
4. ACL generation number: 标识控制权限的更改
chubby还提供了一个chucksum,从而保证文件的内容不会改变
client打开文件的时候会获得handle,对应了UNIX中的file descriptor,一个handle中包含了:
1. check digits,用来防止用户猜测handle
2. sequence number,从而让master知道这个handle是当前master创建的还是之前的master创建的
3. mode information,从而可以让新的master遇到旧的handle的时候去重建他的状态
Locks and sequencers
chubby的node可以作为一个读写锁使用
还有就是分布式场景下的锁,我们需要保证接受到的请求需要和锁的持有者是对应的。否则由于出现message延迟的情况,可能一个没有持有锁的人去使用了服务。
我们通过sequencer来解决这个问题,锁持有者可以在任何时间获得锁的状态,当他需要被锁保护的服务的时候,他就会把sequencer附带上,那么服务器就可以去检查这个sequencer的状态。
server可以通过chubby的cache,或者服务器最近发现的sequencer来检查请求的有效性。
有些server还不支持sequencer,所以通过lock-delay的方法来解决。通过延迟去将这个锁分配给其他的人,我们希望让那些延迟的消息都被处理或丢失后再分配新的lock holder,从而防止delayed message导致的问题。
Events
chubby客户端可以在创建handle的时候订阅一系列的事件。包括:
- 文件内容更改
- 子节点的增加删除或者修改
- master失效
- handle失效
- 锁的获取(用来确定primary的选取)
- 冲突的锁请求(用来允许锁缓存,论文里说没人用)
Caching
为了减少read traffic,chubby的客户端会用一种write-through的方法缓存数据。通过租约的机制来保证缓存的有效性,同时通过master发送的消息来使缓存无效。
master维护了一个列表,存储了客户端都会缓存什么东西。
当文件数据改变的时候,这个操作会被阻塞住,此时master会把数据无效的信息发送给所有具有这个缓存的客户端中。
当服务器知道所有的客户端都消除了缓存以后,他才会继续进行更改(相当于2PC)
Chubby的这个论文感觉有点乱。后面我记一些比较重要的点,就不每一节都写了。
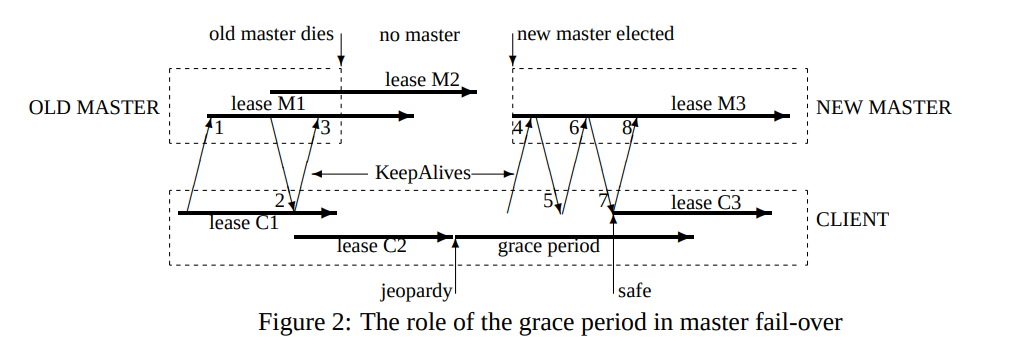
grace period来保证切换master的时候我们还可以继续提供服务

文章评论