NeuGraph Programming Abstraction
GCN:
初始情况下,每个vertex都有一个feature vector
每一个顶点都收集他邻居的特征向量,然后根据边上的权重进行加和。
然后一个全连接的NN来计算新一层的特征向量
比如在推荐系统中,如果用户对某一个item进行评分,就可以在用户顶点和item顶点之间连边,评分即作为边值。然后GCN可以从graph以及用户和item的特征中学习用户和item的embeddings。最后通过这些embedding来预测缺失的user-item评分
GAT和GCD主要的不同点就是GAT对于每个边都计算一个attention value,用来在通过边传输features的时候使用
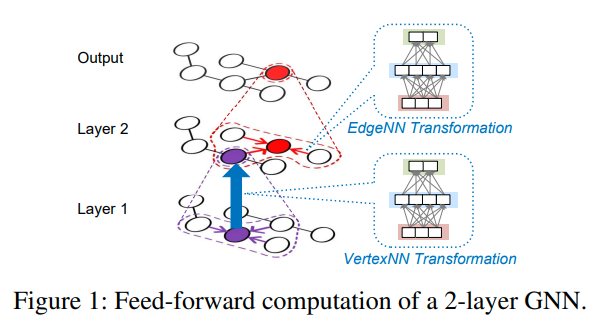
Running Example
G-GCN的例子

等式2代表了EdgeNN,通过两个点的feature来计算边权
等式1代表了VertexNN,他从邻居中聚合信息,并在外层做NN操作
SAGA-NN Model
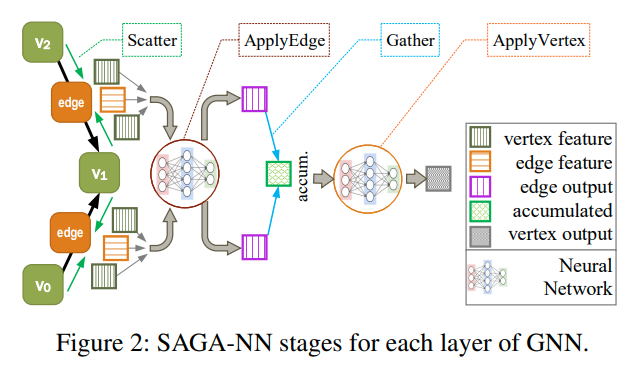
SAGA-NN模型有两个user-defined functions。ApplyEdge和ApplyVertex。用来让用户去定义在edge和vertex上的NN计算操作
ApplyEdge定义了在edge上的计算,输入为edge和p,其中p是可学习的参数。edge是一个tensor的三元组[src, dest, data]。这个函数可以用来在边上应用NN模型,输出的就是中间结果。对应图中的edge output
ApplyVertex函数定义了在vertex上的计算,输入是vertex data,聚合后的数据accum,以及可学习参数p。返回的则是应用完NN之后的新的vertex data
另外两个state,Scatter和Gather,则是用来做数据传输,并将数据准备好提供给ApplyEdge和ApplyVertex的。
同时,NeuGraph也避免将聚合操作暴露给user,而是提供了一些默认的操作。我们通过设置Gather.accumulator来改变聚合的方式
- Scatter将顶点数据传输给他的出边,从而构建edge
- 然后ApplyEdge阶段会根据user-defined function会开始并行的计算,并为每条边生成结果
- Gather阶段会将这些结果沿着边在目标点处进行聚合
- 最后ApplyVertex会执行user-defined function,根据我们聚合的结果,这个点原始的数据最后得到下一层的数据

这个则是G-GCN在SAGA-NN模型上的实现
数据流抽象使我们表达神经网络结构以及自动微分更加容易。通过well-defined stages来建模GNN,可以让我们在graph computation以及dataflow scheduling进行优化
NeuGraph System
NeuGraph包含了
- 翻译引擎,用来将SAGA-NN表示的GNN翻译成chunk-granularity的dataflow graph
- streaming scheduler来减少在GPU以及主机之间的data movement,并且最大化communication和computation之间的overlap
- graph propagation engine来提供各种算子
- dataflow execution runtime(这是用来干啥的)
Graph-Aware Dataflow Translation
由于图数据无法放入到GPU中,所以目前的DL framework不能在GPU上直接使用
2D graph partitioning
将顶点数据划分成p等份。然后将邻接矩阵放到P×P的矩阵中
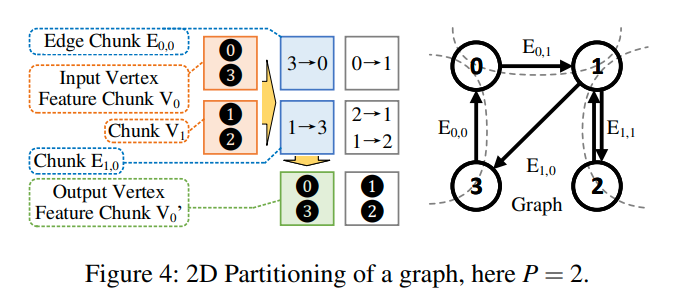
其中Eij中包含了Vi到Vj的边
这样划分的时候,我们可以对每个chunk单独进行处理,同时只会涉及到原点和目标点。这样就可以放到GPU中进行计算。
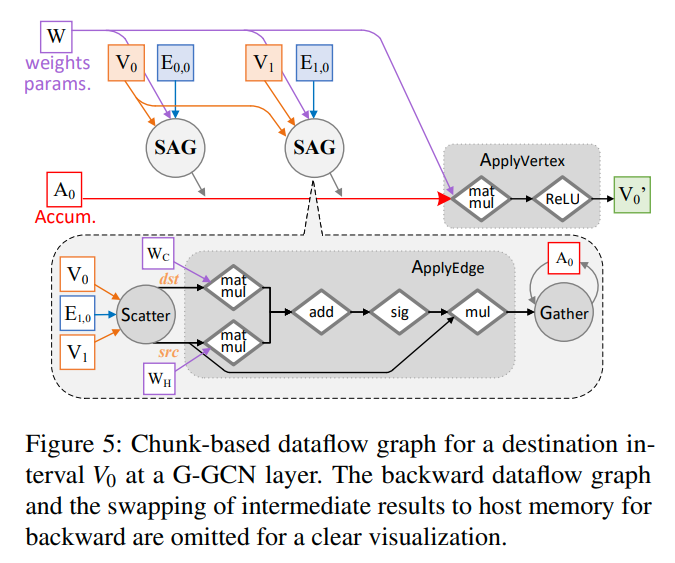
figure5是计算v0的过程,前向传播
对于反向传播来说,由于ApplyEdge和ApplyVertex都是由tensor组成的dataflow computations。所以我们可以通过自动微分来的到反向传播的梯度。同时还提供了backward-Scatter和backward-Gather,一个用来收集梯度,一个用来分发梯度
计算的过程不需要全局的barrier,根据依赖关系不断的调度即可
在计算的时候,我们可以使用row-oriented或者column-oriented。对于前向传播来说,如果使用row-oriented的方法,那么要存储accum的结果的节点就会很多,导致我们不能很好的复用accum(虽然我们可以复用当前的节点),而对于column-oriented的情况下,我们可以直接计算出某一个chunk的accum的值,而且好处是这个accum的值还可以继续复用,在下面的ApplyVertex stage中我们可以用这个值来更新对应的节点。所以对于前向传播来说,column-oriented的方法更好一些
而对于反向传播的情况,梯度会从终点传向起点。所以在row-oriented的情况下,我们可以复用一个chunk下起点的梯度,并且后续可以直接更新他
决定vertex chunk的数量P也是比较关键的。比如在前向传播的时候,我们使用column-oriented,那么就需要进行P次IO来加载源点的chunk。所以希望有一个更小的P。在NeuGraph中,他们选择的就是能保证每个chunk存到GPU中最小的P。论文中这里的观点是通过次数来计算,但是如果看数量的话,总共加载的数据数量都是一样的。
Streaming Processing out of GPU Core
Selective Scheduling
由于有的时候一个edge chunk不会用到对应的vertex chunk中所有的点,比如上面figure5中的左下角chunk,就没有用到2这个点。所以为了减少CPU到GPU的数据传输,每次在CPU的数据中应用一个filter,把用不到的顶点过滤掉
但是这种做法对于random partition的情况下效果不好,比如我们比较希望的是比较密集的边块用到了所有的顶点,稀疏的边块只用到很少一部分。但是对于随机分区的情况下边块的分布也是均匀的。所以通过locality-aware graph partition的方法,让连在同一个点的边尽量都压缩到一起。这样就可以构成较为密集的边块。这样在访问顶点的时候就会有更强的局部性
当大多数顶点都是有用的时候,这时候不去应用filter是更快的,因为filter也会引入一次额外的CPU中的内存复制。所以通过有效顶点的比例以及GPU和CPU的速度来综合考虑
Pipeline Scheduling
通过pipeline来重叠通信和计算的开销。比如当我们计算当前的edge chunk的时候,就可以将下一个edge chunk传入
在这种情况下,更小的chunk size会有更好的overlap的能力。类比CPU中的超流水
但是之前又说过希望通过扩大chunk size来减少IO。所以为了解决这种问题引入了sub-chunk。把每个edge chunk和对应的source vertex分割成若干个sub-chunk,这样我们就可以去并行的处理这些sub-chunk。
???我怎么感觉有点奇怪,这分割成了sub-chunk不是和分割为更小的p是一样的吗?
对于不同的sub-chunk我们可能有不同的数据传输量以及计算开销。所以为了更好的pipeline,NeuGraph在开始的时候首先生成一个随机的处理顺序,然后他会不断的交换sub-chunk的处理顺序,直到处理的时间收敛。(只交换sub-chunk,可能是为了防止破坏局部性)
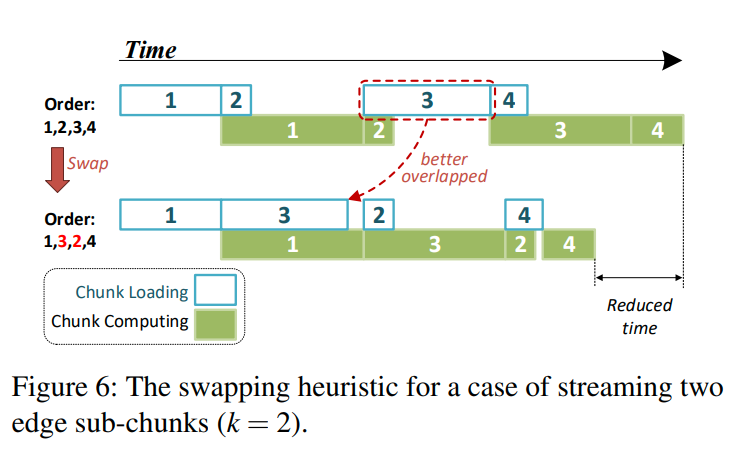
NeuGraph在前几次iteration收集每个sub-chunk的计算以及传输时间。然后在后面的iteration中,他会模拟当前schedule order的执行时间。看figure6,系统会找到传输时间远大于计算时间的sub-chunk,以及计算时间远大于传输时间的sub-chunk,并尝试交换他们,从而找到更好的执行顺序。
这里还是感觉怪怪的。
Parallel Multi-GPU Processing
感觉可以很直观的想到,forward的时候,一个GPU处理若干个dst vertex,他们之间不会有相互的关联
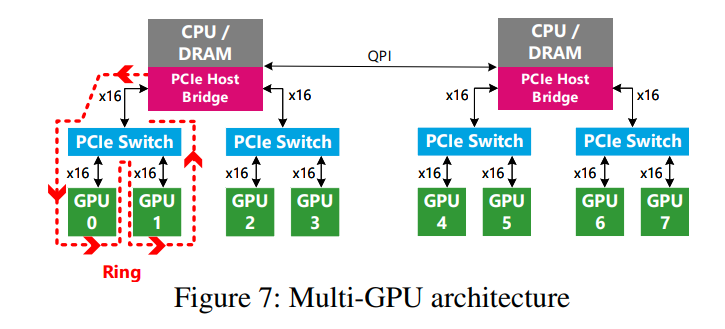
通过figure7可以看到,GPU之间的连接有的也是要通过CPU的。并且他们共享着PCIe总线。当GPU0和GPU1同时搬运数据到DRAM的时候,他们的带宽是跑不满的。我们会受到上层链路的限制
为了解决这个问题,NeuGraph使用一种chain-based streaming scheduling模式。因为每一个vertex chunk都会所有的GPU使用,所以我们可以通过GPU之间的PCIe switch来转发这些vertex chunk,而不是走DRAM这条线
NeuGraph认为在相同PCIe switch下的GPU是一个大的virtual GPU
传递数据的顺序就是figure7中的红线
对于每个GPU来说,他们有两种操作,一种是从DRAM中加载edge chunk,或者从DRAM或者他的上一个GPU中加载vertex chunk,第二种就是执行计算
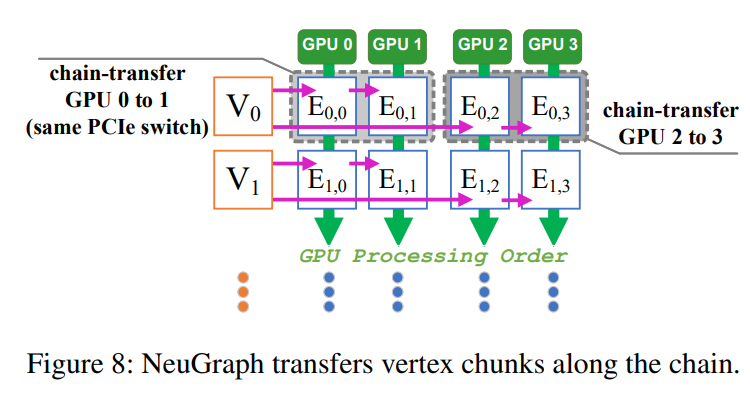
在figure8中演示的。最开始GPU0和2加载V0,并开始计算,与此同时他们可以从DRAM中开始传输V1的数据。而对于GPU1和3来说,他们会开始从GPU0和2那里获取V0的数据。之后系统就可以这样一直pipeline下去
Graph Propagation Engine
在ApplyEdge阶段,每一个顶点都有若干个出边,每次我们都会让顶点数据去与参数矩阵做矩阵乘法,从而导致很多的冗余计算。所以把这些独立的计算放到上一层中来消除冗余
在大多数的GNN计算中,ApplyEdge只会去做一些element-wise的操作,在这种情况下我们可以去融合这些算子,让他们可以直接在GPU寄存器中存储数据,而不需要涉及到数据的复制以及中间数据的暂存。NeuGraph将SAG融合成一个操作叫做Fused-Gather。他会首先加载Scatter的输入,比如源点数据或者边,然后用GPU线程来执行in-place的更新,最后生成每个点的acc。(我的理解就是将前面的GNN处理阶段的操作fuse一下)
Implementation
在tensorflow的基础上额外提供了
- 将vertex-centric symbolic program转化成dataflow
- streaming scheduler
- graph propagation engine以及优化的kernel,用来实现Gather/Scatter operator
Dataflow Translation
NeuGraph提供了和传统operator类似的GNNlayer。他会将点和边划分成chunk,并根据user program来将GNNlayer和Gather/Scatter组合起来,生成基于chunk的dataflow graph
Streaming Scheduler
scheduler会尝试优化dataflow graph。然后根据有效顶点的数量决定是否使用filter。以及profile执行时的数据,并优化plan
Multi-GPU Execution
在NeuGraph中,不同的GPU会并发的执行(我理解是用于通信用的)算子,在每个算子中他会申请空间并与其他的设备交换这些地址,从而实现D2D的数据传输。在不同的GPU中我们还需要去在每个iteration之间同步参数,这个是通过all-reduce来实现的。(?为什么不传输到CPU中然后用PS呢)
Graph Propagation Engine
NeuGraph实现了gather,scatter,fused-gather。
scatter是一个map operator,将vertex data转化成edge data
gather则是一个reduce operator,用来累加edge上的数据
fused-gather则是当edge计算都是element-wise的时候,对应的one-pass computation

文章评论