就把这篇论文当作图计算的入门论文了
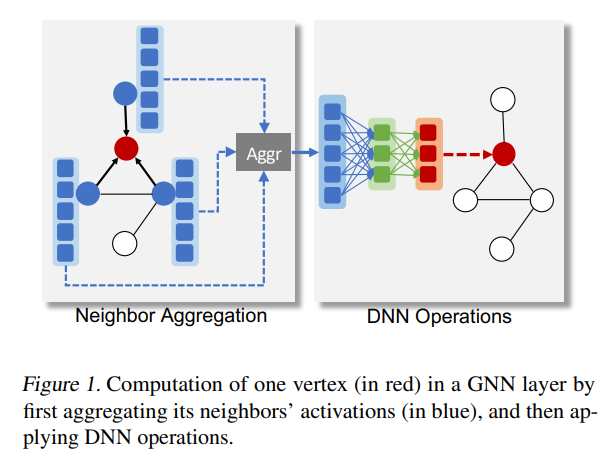
GNN中一个顶点的计算过程
要收集他的邻居的信息,然后aggregation,再传入到传统的DNN中做分类/回归
Roc用了一个linear regression model做partition
通过dp来最小化数据传输的代价
GNN对于每一个vertex学习一个vector representation,并可以用这个representation给下游任务。比如做vertex classification, graph classification, link prediction等

公式是这样的
h就是在第k层的激活(就是值),第0层的值就是输入的原始数据
N就是所有v的邻居。a表示的就是这一层的聚合
可以看到对于第k层的聚合,是收集了所有邻居节点在k-1层的值得到的
然后计算节点在第k层的值就是用k-1层的值加上当前这一层得到的聚合
所以可以发现,第k层的activation就会汇聚最多K跳的邻居的信息。然后就可以用来做下游任务的输入了
related work
DNN computation可以在sample,operator,attribute,parameter这几个维度上进行划分,从而实现并行执行
比如sample上划分则是data parallelism
在operator上划分就是model parallelism
对于GNN的一个特点是在attribute上进行划分,比如在一个大型的单个样本上进行分区
由于highly connected natrue of real-world graphs。计算h的时候需要我们去获得相当多的邻居的数据。所以提出了down-sampling neighbors of each vertex
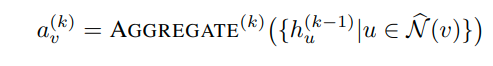
其中的N表示的是采样邻居节点所生成的子集,具有有限的大小
采样的方法会导致model accuracy loss
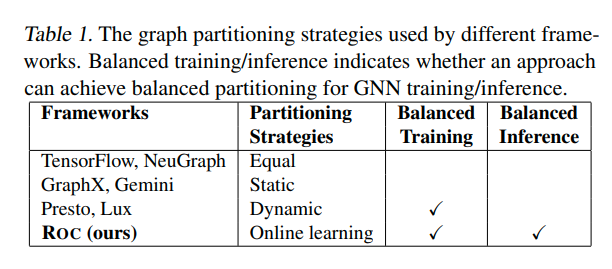
图中列举的划分图的方法
equally就是相等的划分图
GraphX和Gemini则是通过最小化启发函数得到的静态分区方法,比如最小化跨越分区的边的数量
这些划分方法在数据密集型的处理中具有良好的性能,但是由于逐顶点计算负载的变化,他们在计算密集型的GNN中无法很好的工作。
动态分区方法利用了图计算中迭代的特性。他们通过测量前一次iteration的performance来进行workload rebanlance
这种方法对于GNN training会收敛到一个平衡的工作负载,但是对于GNN inference来说就不太行,因为inference对于每一个新的graph只计算一次
Roc overview
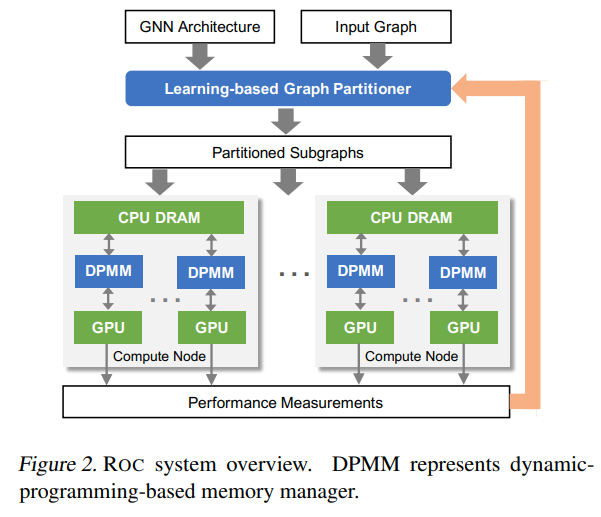
输入GNN architecture和图,通过partitioner划分子图
然后每个节点内部有一个DPMM(dynamic-programming-based memory manager)用来减少在CPU和GPU之间的data transfer
graph partitioner是和GNN一起训练的,并且也可以在新图的inference时候用来partition
partition以后,每个子图都发给对应的节点。使用更大的DRAM来保存全部的数据,并将GPU memory看做cache。但是在GPU和DRAM之间传输tensor还是对runtime performance有很大影响。所以Roc用DP来最小化data transfer
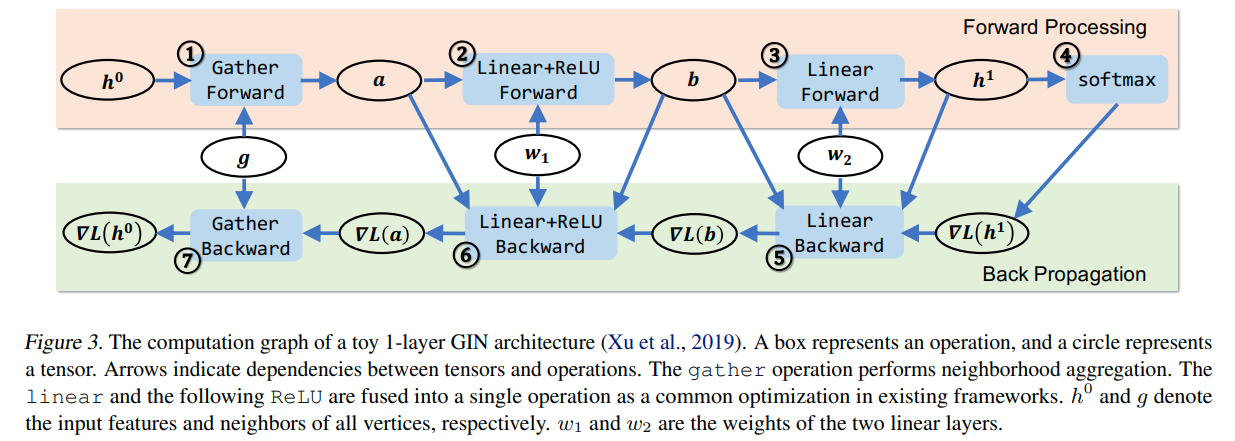
gather就是neighborhood aggregation,后面的就是正常的DNN
For each state S, we define its active tensors A(S) to be the set of tensors that were produced by the operations in S and will be consumed as inputs by the operations outside of S. Intuitively, A(S) captures all the tensors we can cache in the GPU to eliminatefuture data transfers at the stage S.

用dp来求最优传输

文章评论