Introduction
pregel的program model类似BSP。每一个iteration叫做一个superstep。每一个superstep,系统会在读取上一个superstep传给顶点的数据,并应用user-defined function,然后他会沿边将数据传输出去,从而让他的邻居在下一个superstep使用这些数据
这种做法和MapReduce非常像,用户给出处理每个顶点的逻辑,然后系统会将这个操作应用到大规模的数据集上,并且不会暴露出执行顺序以及superstep之间的通信细节。
Model Of Computation
pregel的输入就是一个有向图,其中边和点都可以有权值。
pregel的计算过程:输入图数据,然后初始化图,然后进行由global synchronizatio point分割的superstep,直到收敛
算法什么时候终止取决于vertex是否选择去halt。每个vertex最开始都是active的,当他们不再参与计算了(比如最短路里距离收敛了),他们就会vote to halt,进入inactive的状态
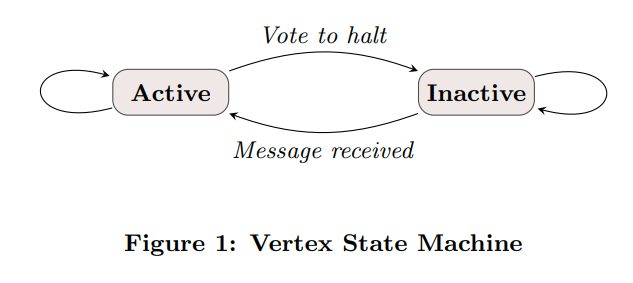
每个vertex的状态机表示。当其他的节点发送信息的时候,他们就会再次被激活(比如spfa中更新了节点距离,那我们就要让这个节点入队)
一个传播最值的例子
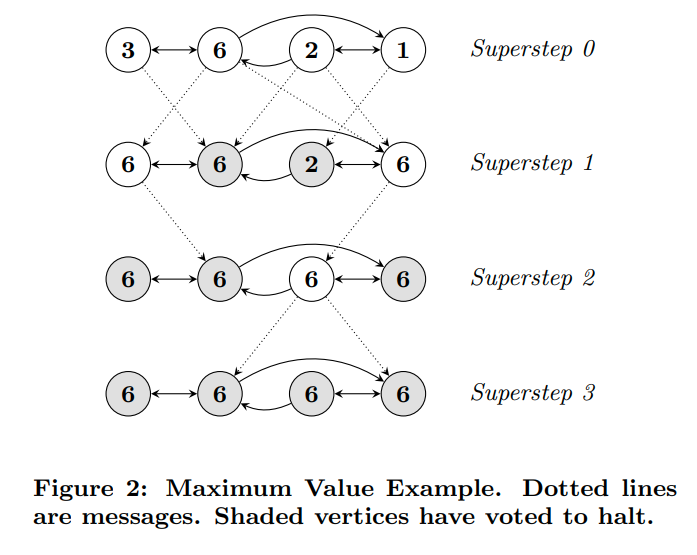
图上的算法可以被表示为一系列的MapReduce操作。但是MapReduce是函数式的,对于多个链接起来的MapReduce操作来说,我们需要去传输整个状态。而对于pregel用的这种模型,我们只需要传输messages(顶点的数据之类的东西)。从而减少网络的负担
API
pregel提供了一个aggregator,每次superstep每个顶点都可以向aggregator发送一些消息。aggregator就可以聚合并统计这些信息。比如计算当前图的边数等
同时aggregator也可以用做global coordination的方法。因为每个顶点都可以访问到aggregator中的数据,所以我们可以在aggregator中通过一些谓词来判断是否满足条件。
还可以通过aggregator来实现一些高级的操作,比如分布式的优先队列。在当前superstep中,每个节点发送他们的index以及distance。然后在aggregator中统计出最小距离的顶点们,让他们在下一个superstep中继续更新。
某些算法需要去更改图的拓扑结构,比如聚类算法可能将一个cluster替换成一个vertex。或者MST(最小生成树)可能会移除很多边。这时候我们就可能出现竞争,比如两个顶点同时要求添加一个idx相同但是初始值不同的顶点。
通过partial ordering和handler来解决这个问题。在一个superstep中,我们首先删边,然后删点,然后添加点,再添加边,最后根据Compute执行mutation。这种偏序关系让我们可以解决掉很多的冲突
剩余的竞争则是通过用户指定的hanlder来处理。比如添加或者删除相同的vertex或者edge。否则的话系统可能挑选任意一个操作来执行
pregel的coordination mechanism是lazy的。对于这些global mutations(我理解就是图的拓扑结构变化),直到他们真的被应用的时候才会去协调冲突,从而有助于stream processing。比如对于一个点V的修改的冲突会在V上体现出来的时候再去让V自己来协调。而不是说让一个global coordinator去协调所有的操作。
Implementation
Basic Architecture
pregel将图划分为若干个分区,每个分区是一组顶点,以及他们的出边。一个顶点具体的分区位置取决于顶点的ID,所以只通过顶点ID就可以知道其他顶点存储的位置。默认情况下分区就是hash(ID) mod N
不考虑fault的情况下,pregel的执行由若干个stages组成:
1. user program会被分发到集群并执行。其中的一份拷贝会作为master,master不会获得graph的任何部分,而是负责协调worker。worker使用集群管理系统的name service来找到master的位置,并向master发送注册信息
2. master负责决定graph有多少个分区。然后将这些分区分发给每个worker。master可以向同一个worker发送多个partition,从而可以达到load balancing,以及更好的利用并发。每一个worker都负责维护自己的那部分图,执行Compute以及管理消息的传入和传出。
3. master会把用户的输入划分并分配给user。这里输入的划分和图的划分是正交的,并且输入的划分一般是根据文件的边界划分(GFS的文件)。如果worker加载的数据属于他自己,他就会更新对应的数据结构。否则的话他就会把这些数据发送给负责这块数据的worker
4. master负责指示每个worker来执行superstep。worker会遍历他的active vertices,每一个分区用一个线程来执行Compute,并且接受到上一个superstep中的消息。为了实现communication和computation的overlap,消息的传输是异步的(我猜测就是处理一个batch的节点,然后发送这个batch节点对应的消息,与此同时处理下一个batch的节点。同时batch内部还可以用上面的combiner进行合并)。当worker完成,他就会向master发送还有多少个活跃的顶点。master会不断重复这个操作直到不再有活跃的顶点。
5. 当计算终止了以后,master可以告诉worker去保存他的那部分数据
Fault tolerance
pregel通过进行checkpointing来实现fault tolerance
worker与master通过交换心跳来确保对方存活。如果worker发现收不到master的心跳,他就会终止程序。如果master收不到worker的心跳,他就会认为这个worker失效了。
当一个或者多个worker失效的时候,master就会对现有的worker进行重新分区。然后这些worker会从最近的检查点重新加载数据(因为checkpoint应该是在GFS内)
worker会在superstep中log他们发送的message。当我们知道了那些partition被丢失的时候,我们就可以只从checkpoint恢复这些丢失的分区,然后对于丢失的分区根据那些被log的消息来进行重新计算。
这种方法节省了恢复时的计算资源。因为这时我们只需要重新计算和传输和丢失分区有关的数据。但是logging增加了开销。目前的机器中不会收到这些logging的overhead的影响。
但是这种方法要求用户的算法是确定性的,否则恢复的分区就会接受到来自之前的消息以及recovery的消息。这样的话可以fall back到基本的recovery方法来进行恢复
Worker implementation
worker负责维护他自己这部分的图的状态。可以被认为是vertexID到每一个vertex状态的一个映射。vertex的状态由vertex value,他的出边的链表,incoming messages的队列,以及一个flag表示active-deactive的状态
worker在执行superstep的时候,他会循环每一个vertex,然后执行Compute,传入他当前的值,以及incoming message的迭代器,还有出边的迭代器
当一个worker处理他的顶点的时候,在另一个线程会同时接受来自其他worker的消息。
当Compute希望发送给其他vertex消息的时候,worker首先确认目标点是不是在远端。如果是在远端他就会把消息buffer起来等待传输。当buffer的大小到达一个阈值的时候,buffer就会被异步的刷新并发送消息。对于本地的传输,我们可以直接把message放到对应顶点的queue里
这里注意,对于当前的superstep,每个vertex有一份顶点数据和他对应出边的数据的拷贝。但是有两个vertex flag和incoming message queue的拷贝。因为两个flag标识他当前的状态,以及下一个superstep的状态。而queue一个存储当前用的消息,一个用来接受下一个superstep的消息(异步传输)
如果user提供了combiner,在消息放到传输队列的时候以及在输入队列接受到的时候,他们就会被应用。前一个减少了网络负担,后一个减少了用来存储message的空间。
Master implementation
master维护了每个worker的信息,包括worker的标识符,地址,负责的partition等
大多数master的操作,包括输入,输出,计算,保存checkpoint和恢复checkpoint都会在barrier中结束。master会给所有的worker发送相同的request,然后等待回复。如果有worker失效了,master就会进入恢复模式。如果barrier synchronizatio成功了,master就会进入到下一个阶段。
Aggregator
每个worker都会维护一个aggregator实例的集合。在每一个superstep中,worker就会将提供给aggregator的值进行部分的聚合。在每个superstep的最后,worker会以树形来聚合不同worker的部分聚合值,从而形成全局的聚合,并在最后发送给master。master会在每一次superstep开始的时候将这些值发送给每个worker

文章评论