Lecture 13
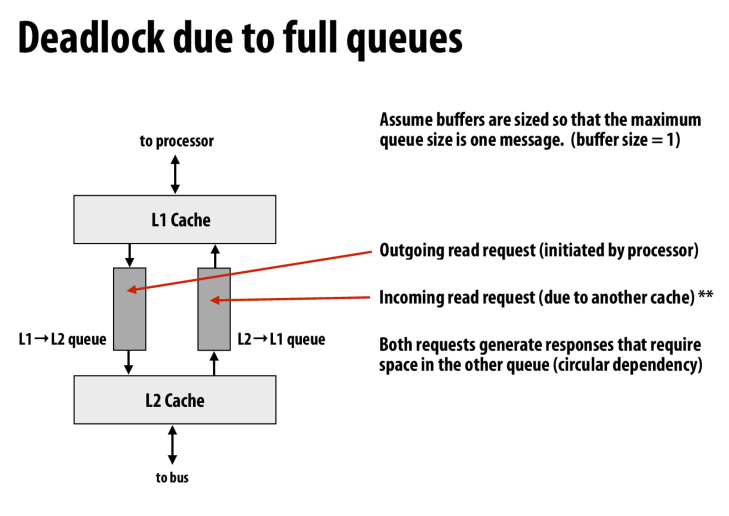
cache之间用队列,可能当队列满的时候导致死锁
因为一个队列中的request会需要在另一个队列中进行response,也就是一个队列中的work的完成需要另一个队列的resource
当队列满的时候,两个queue都需要对方queue的resource,导致了死锁
一个解决办法是可以扩大queue的容量,到系统最大事务数量
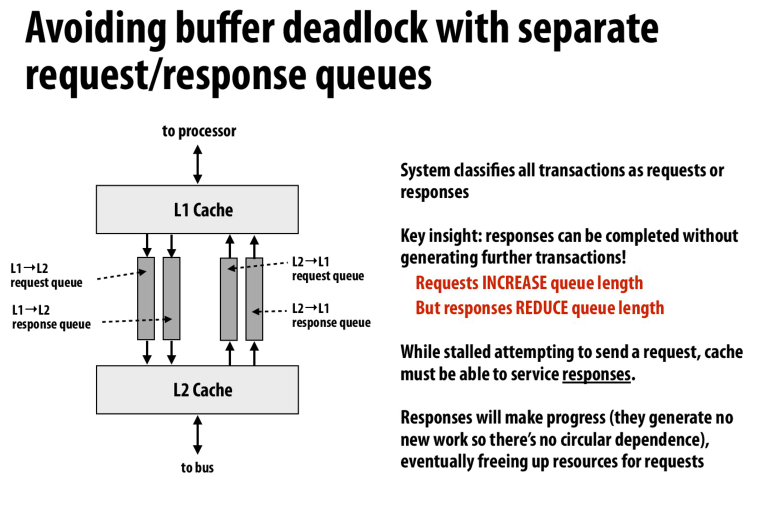
第二种方法是消除依赖
一个队列依赖另一个队列的空间,实际上是一个队列中的request依赖另一个队列的response
所以我们将request和response拆开,这样队列资源就没有循环依赖,也就不会出现死锁

一个小总结

之前自己一直对这个地方搞不清楚
coherence和consistency是不一样的
coherence让缓存变得透明,在单核中,我们感受不到缓存。在多核中,由于coherence protocol的存在,我们也感受不到缓存
但是对于consistency,保证的是我们读写的值是正确的。在不违反语义的情况下,为了优化性能而对WR操作进行重排序

串行一致性,保证了这四个顺序,也就保证了我们在程序执行过程中,内存的状态始终是符合我们预期的

弱一致性模型,允许违反部分ordering,从而带来更高效的操作
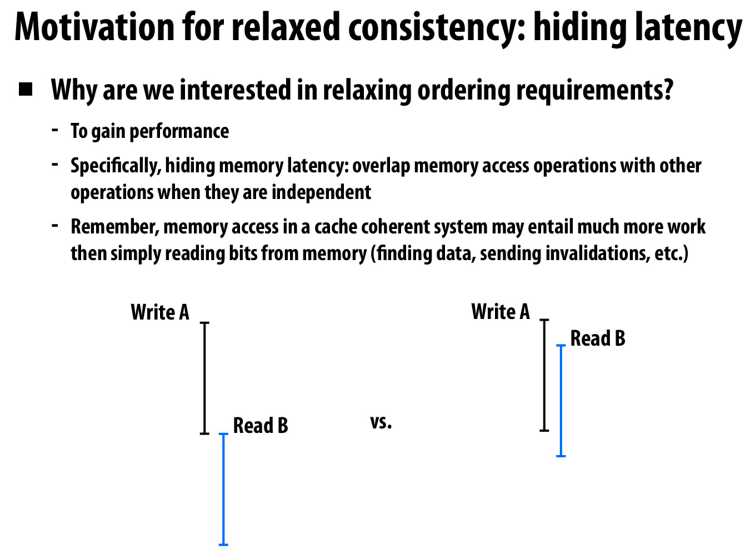
motivation,隐藏延迟
我们不必等一个写操作完全结束后再开启一个新的操作,而是重叠部分操作
多体存储器,重叠访存周期从而提高效率
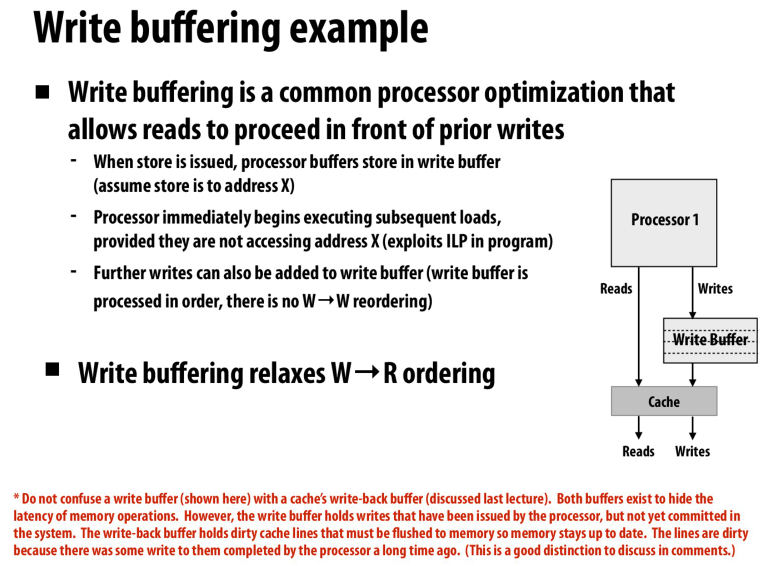
现代CPU中的一个优化,写缓冲区
通过写缓冲区来延迟写操作,从而允许后续的操作继续进行,这个优化让我们不再保证W-R ordering
和写回缓冲不同,写回缓冲表示去延迟flush cache line的操作,而写本身已经结束了
但是写缓冲则是延迟了写操作本身


acquire和release,相当于一个单向的屏障,防止跨越屏障的reordering发生,以此来保证consistency


主存上的同步,在同步手段的保证下,我们可以实现线程与线程之间的同步,i.e. 读到的内容是相同的,一个的写能被另一个线程读到
当没有使用同步手段的时候,我们不能保证内存的一致性,也就不能保证线程之间的通信是正常的

所以在多线程中保证程序的同步就是程序员和编译器的责任了
关于consistency,就是保证程序执行的顺序和处理器处理内存中数据的顺序是相同的,这是单个指令流的概念
一旦我们会乱序这些指令,就会导致我们操作的内存是不一致的状态
从而导致其他线程看到的也是不一致的状态,也就导致了同步失效
所以consistency,就是访存的一致性,他发生于一个处理器中,但是影响的是其他的处理器
因为无关指令不会对单个processor造成影响,但会影响其他processor的状态
Lecture 14
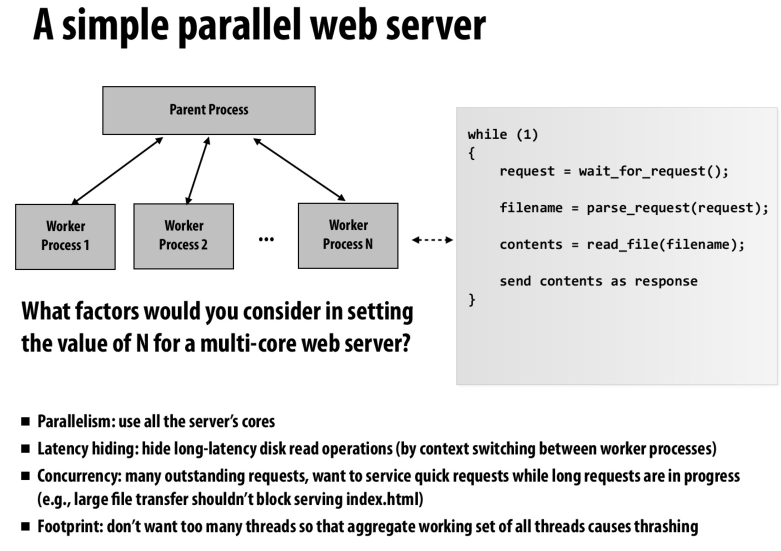
决定worker的数量
我们要考虑的因素有:
充分利用机器资源
对于IO heavy的task来说,利用其他的线程来隐藏IO延迟。
提高并发度,我们不希望让长时间的工作去阻塞轻量的工作
但是我们也不希望去创建太多的线程,这可能导致thrashing(频繁切换线程导致的资源浪费),同时创建线程也会成为关键路径上的瓶颈
在web server中,用进程来替换线程的好处就是我们不需要太多的worker之间的通信,但是进程可以提供很好的隔离性
还有一个点就是有些库可能是不可重入的,多线程的时候只能有一个线程去使用这个库
但是多进程情况下,每个进程都有自己的空间,就不会出现瓶颈
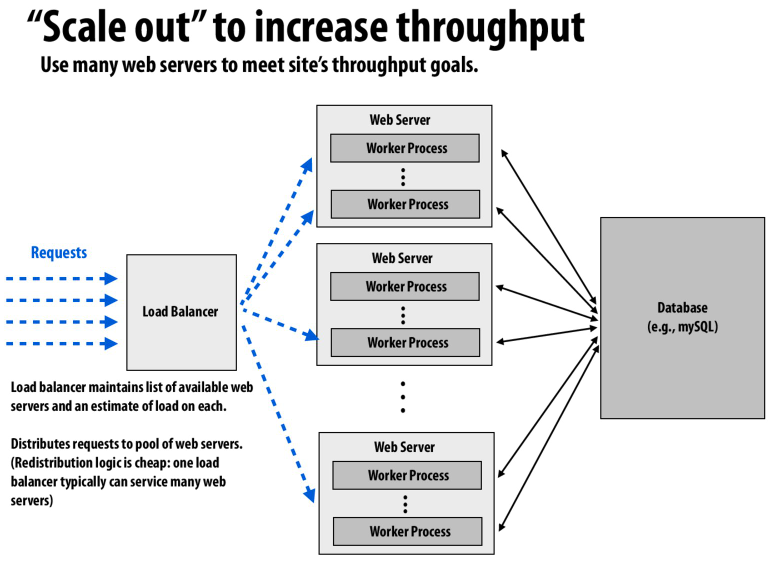
利用负载均衡器来分配负载,通过提高机器的数量来提高吞吐量

网站的访问是突发的,而网站的负载决定了我们要使用的服务器的数量
通过检测服务器的负载,并动态的添加或删除服务器节点,来实现弹性的负载
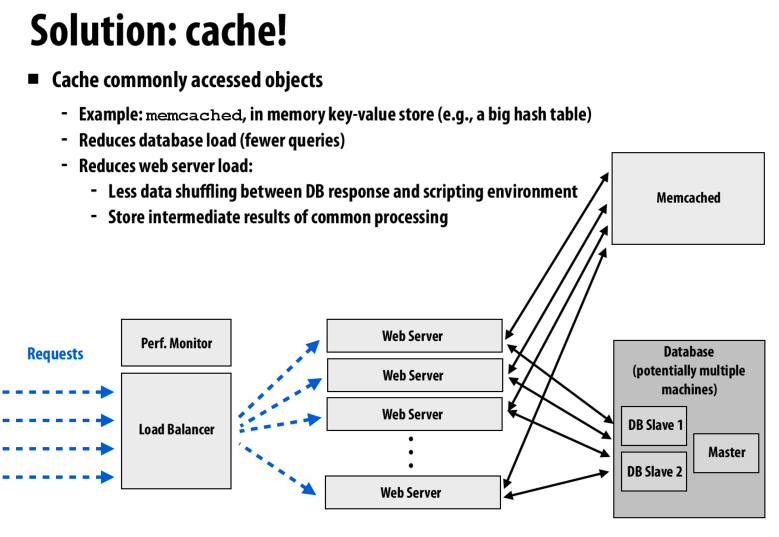
通过cache来缓存访问,从而减轻数据库的压力
也可以在前端加上cache
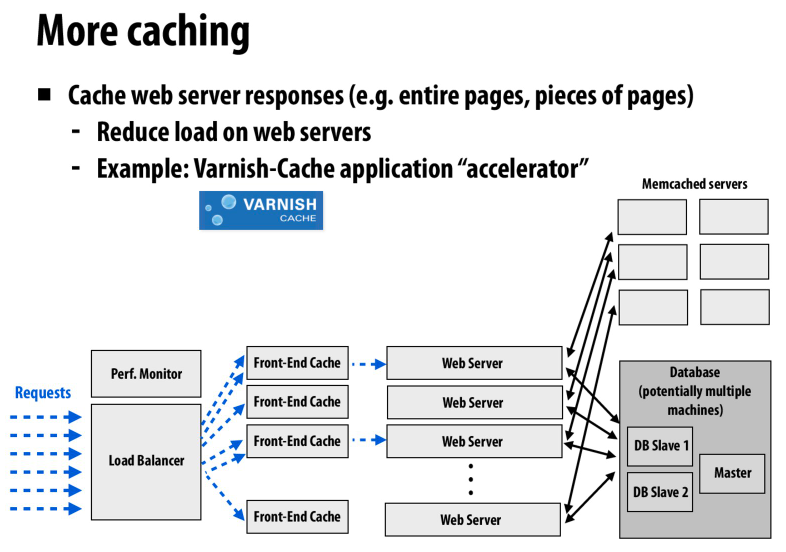
比如缓存相同的请求,上面是缓存数据库的请求,这里是缓存web server的请求
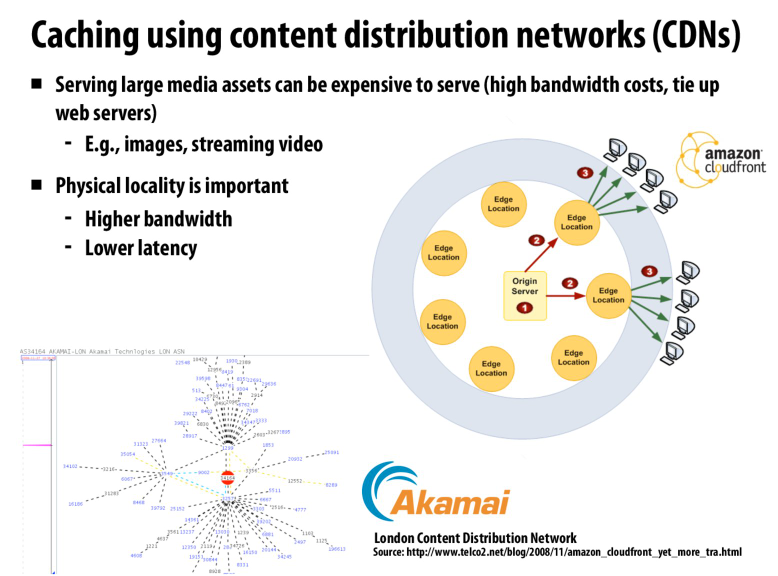
还有一种很常见的方法就是通过CDN来进行缓存

对于上面的一个总结
Lecture 15
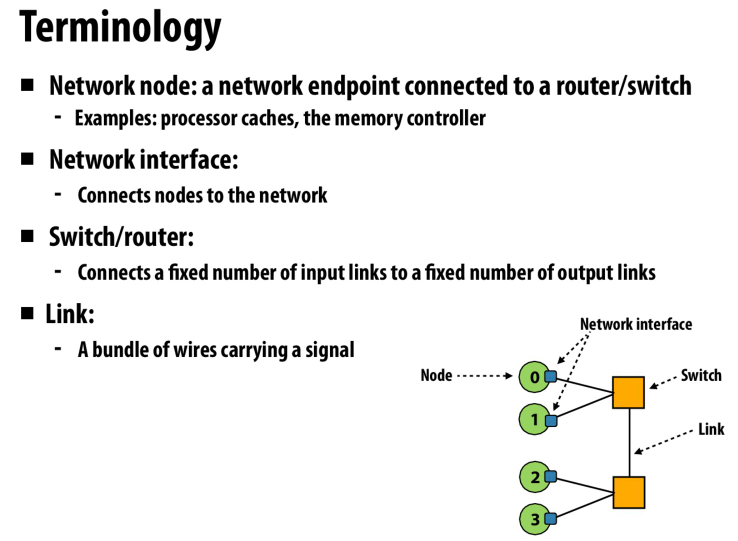
一些基础的术语

设计中的问题
节点之间的拓扑关系,他们是怎么相连的
一个节点的消息是怎么到达另一个节点的
节点/router上的缓冲,数据的存储形式等

bisection bandwidth,二分开这个网络,然后看他这两块中的link所构成的bandwidth
当两条消息需要使用相同的硬件资源的时候,就会导致blocking(硬件资源的争用)
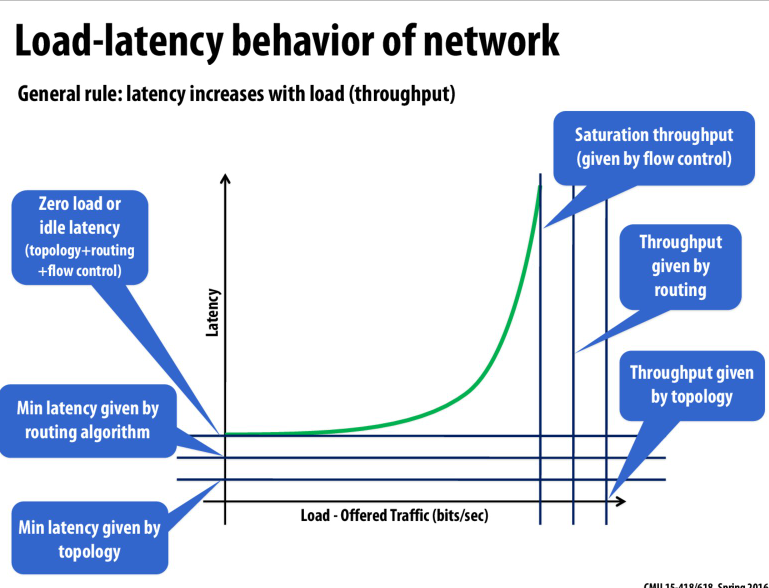
随着吞吐量的增加,latency也会增加
三个因素共同确定了这个图表,分别是topology, routing, flow control
latency则是他们影响的因素的和,而对于throughput,则是他们的最小值
然后是不同的topology
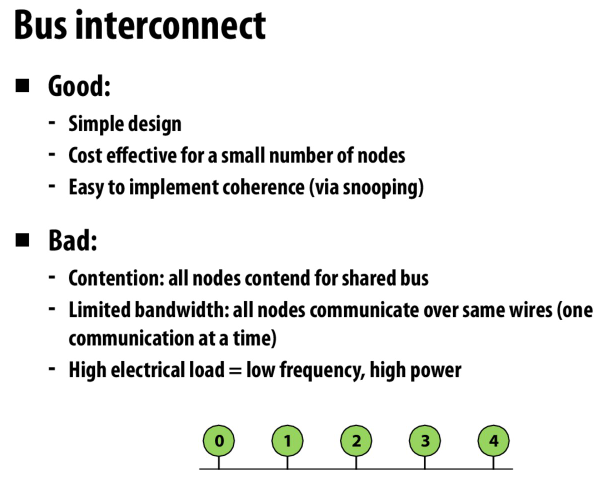
总线结构,简单,易于实现coherence protocol
争用高,耗电,带宽低
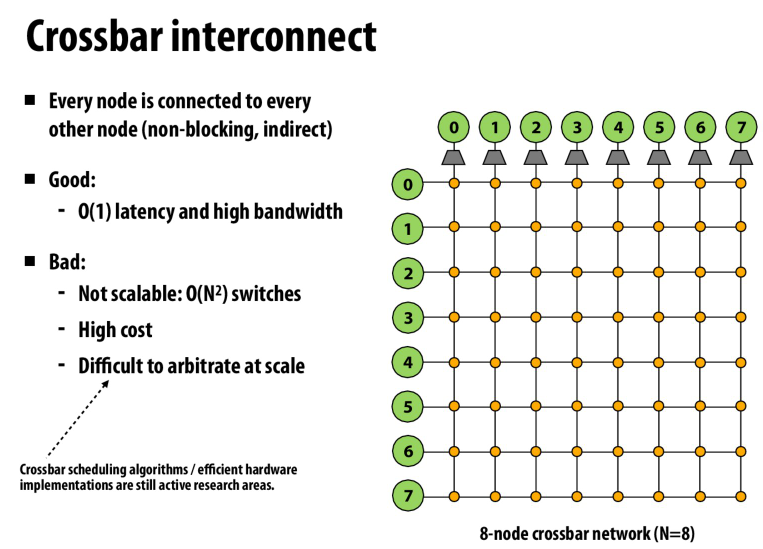
每一个node都相连,不需要通过node间接发送数据
难以拓展
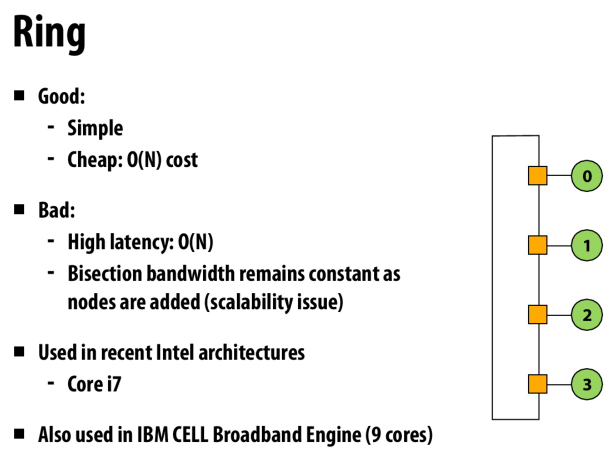
环状
简单,花费不高
但是有高延迟,并且二分带宽低(无论怎么拓展,都是1)
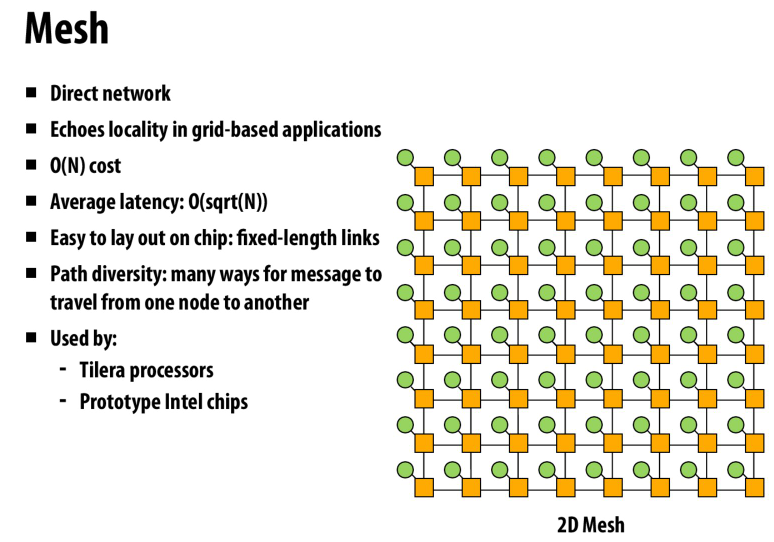
mesh
局部性好
latency低
路径多
link长度相同
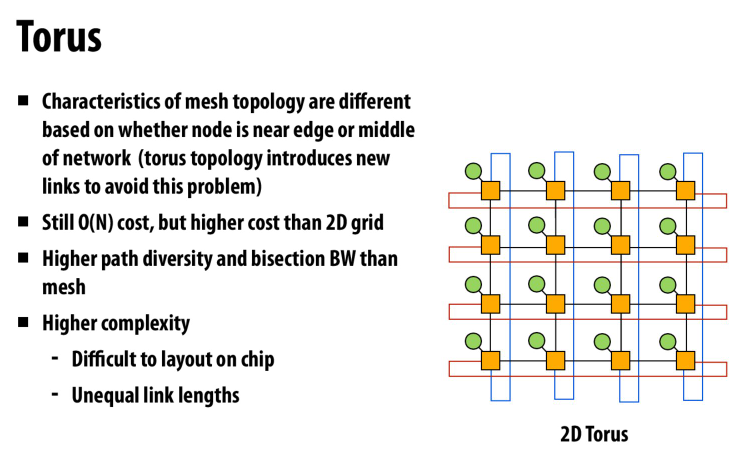
特性更好
但是复杂度更高,不容易放到芯片上
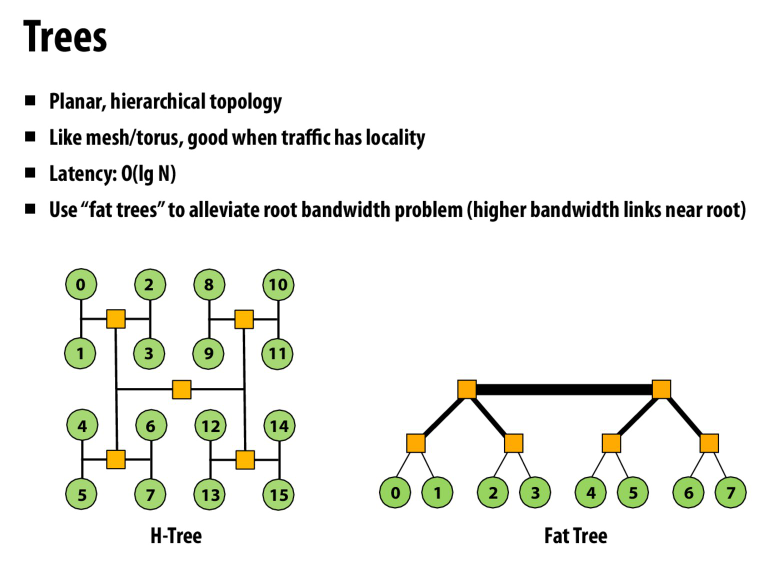
树型
局部性好
通过fat tree来避免根节点处的带宽限制
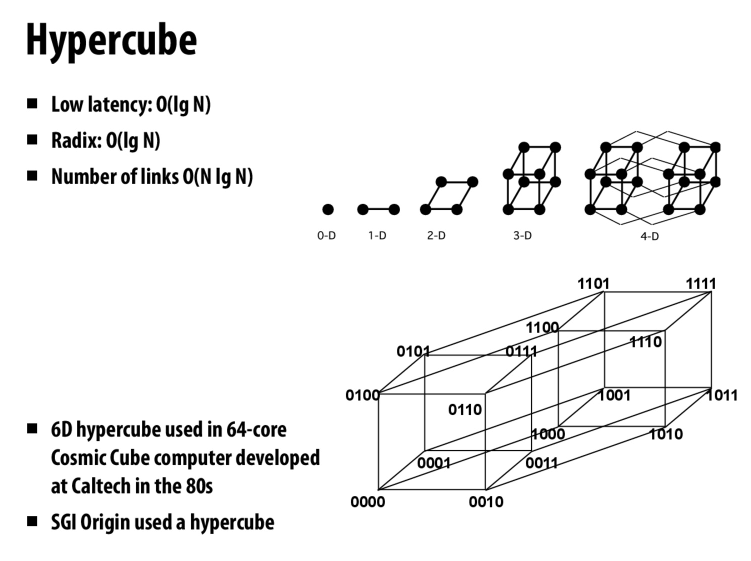
hypercube
低延迟
需要一定数量的link
不好布线
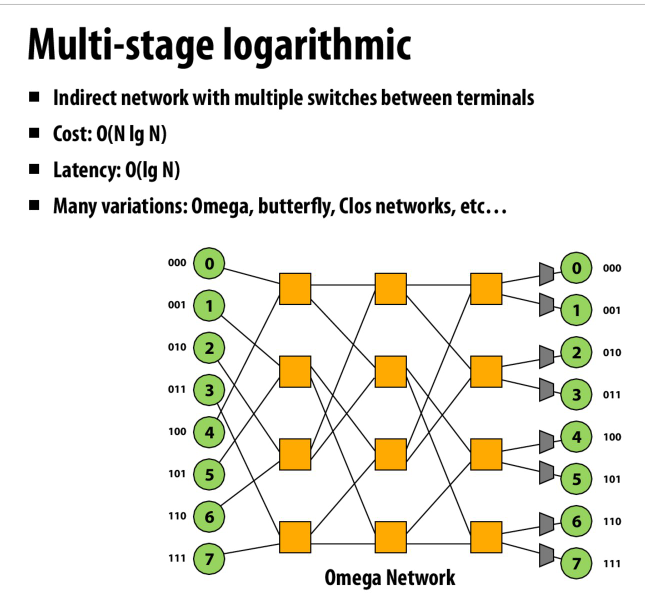
omega
划分的方式类似树状数组
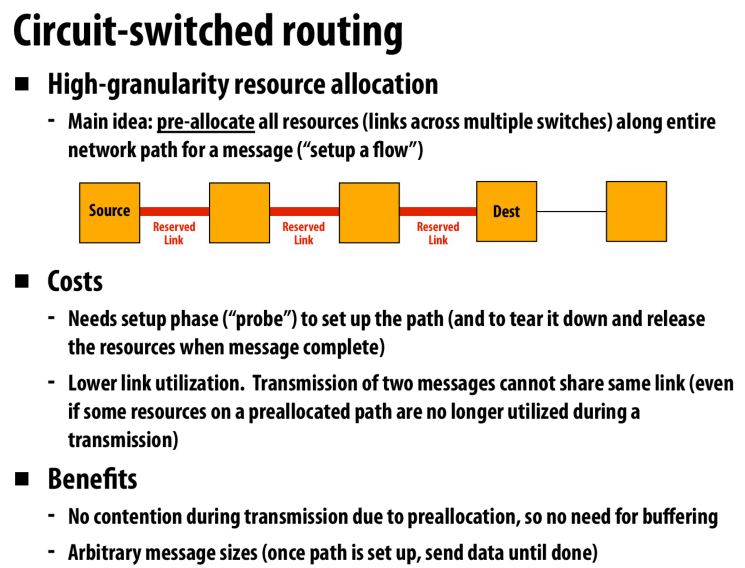
提前预订好link
但是利用率会很低
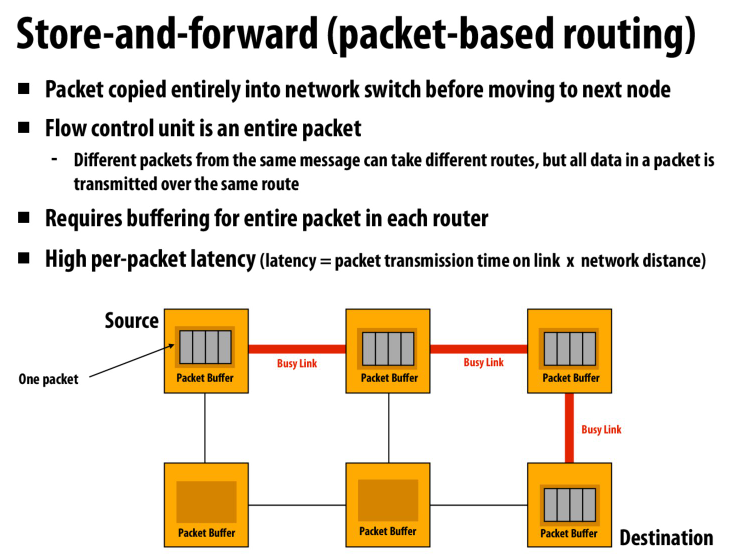
常用的packet based routing
遇到冲突了就把packet存到buffer中
但是latency会变高
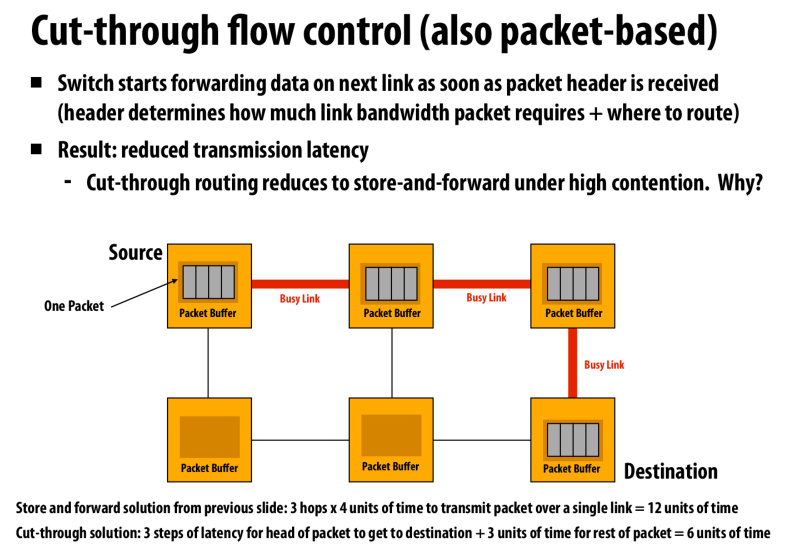
我们可以pipeline这个操作,在不明显减少latency的情况下提高吞吐量
核心思路就是将操作划分成细粒度的,从而提高硬件资源的利用率
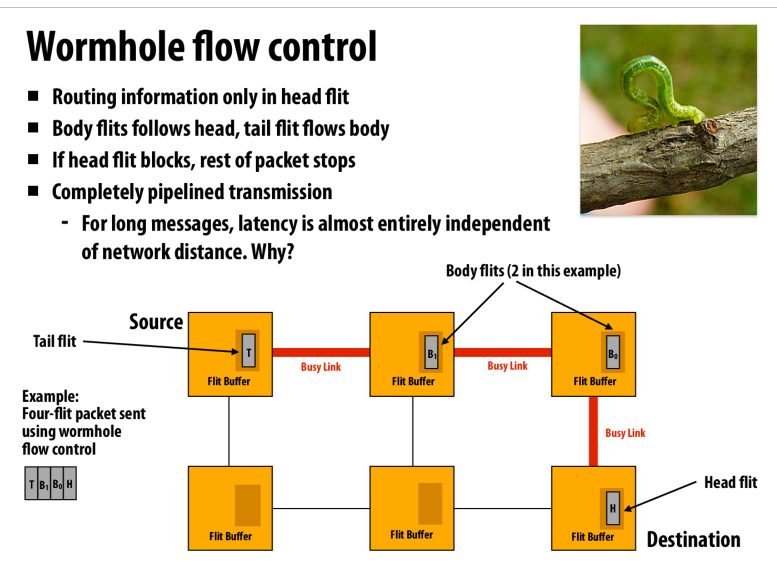
通过更细粒度的划分来减少延迟
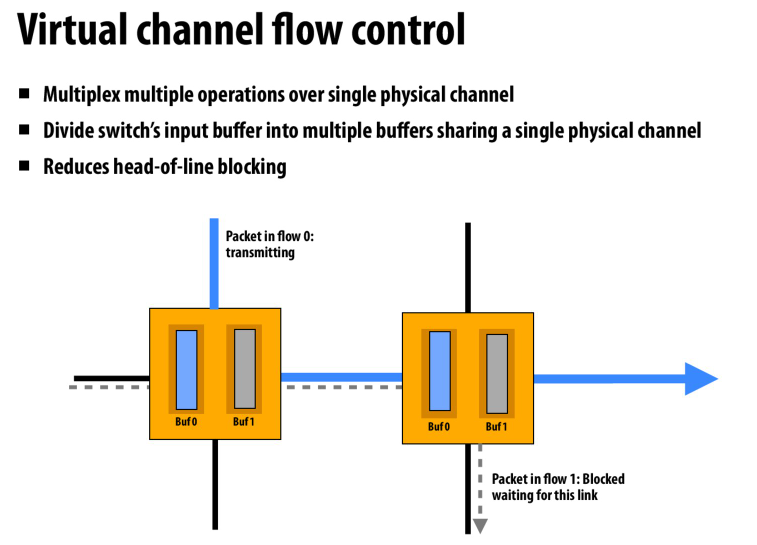
复用物理通道来构成逻辑上的虚通道
防止packet之间相互阻塞

文章评论