Lecture 10

一个小复习,执行一个写操作在cache层面会发生什么
我们要考虑该地址不在cache中,以及cache满时要evicit一个cache line,并且如果该cache line是dirty的,我们还需要将该cache line写回

单核系统上也会有cache coherence问题
发生在CPU和其他设备通讯的过程中
这也就是为什么有的设备IO空间是不可缓存的
或者需要让操作系统显式的flush这些page,或者这些cache line

所谓的sufficiently separated time应该和cache coherence protocol有关
就是指一致性协议同步cache所需要的时间
这就是弱缓存一致性


MSI protocol
三个状态,失效,共享,修改
在量化研究方法中有,这里就不细说了
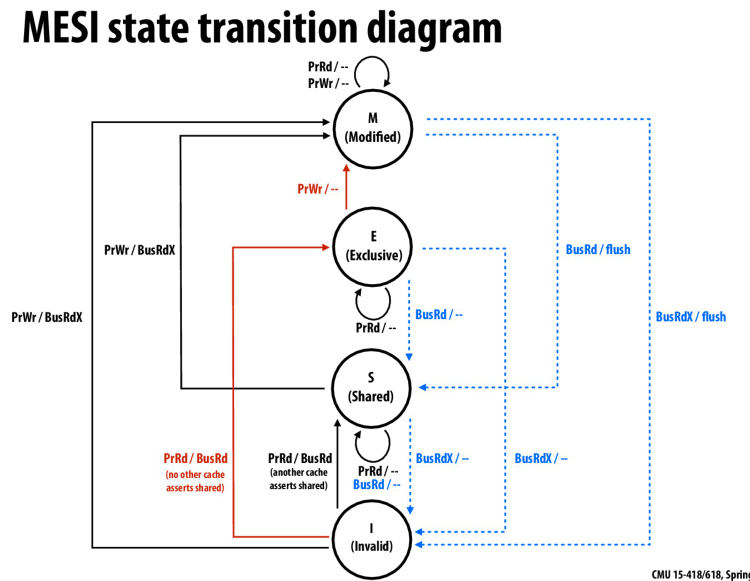
MESI,对MSI的一个优化
减少转化到M状态下的总线带宽
比如正常状态下,在没有share的情况下,我们读一次写一次,从I到S,再到M,会有两次总线的事务
但是有了E状态,我们就是从I到E,再到M,只有一次总线事务
优化了无共享状态的总线带宽
但是I到E他是怎么知道其他人没有这个副本的我不太清楚,应该需要其他人回应
注意这里我们是一个cache line对应一个状态
并且读写的单位都是cache line

优化,比如F代表forward,表示哪个processor负责将cache line转发给请求的processor
AMD中的owned表示持有这个cache line,而不会写回给内存
这样可以减少总线带宽,但是owned的processor负责处理其他processor的cache miss

基于更新的一致性协议
就是谁写谁就负责把其他的processor都更新
导致的问题


多级缓存中的应用
L1是L2的子集,我们要保证在L1中的写也会在L2中体现出来,这样就不会出现不一致的情况
用L2去处理总线事务即可
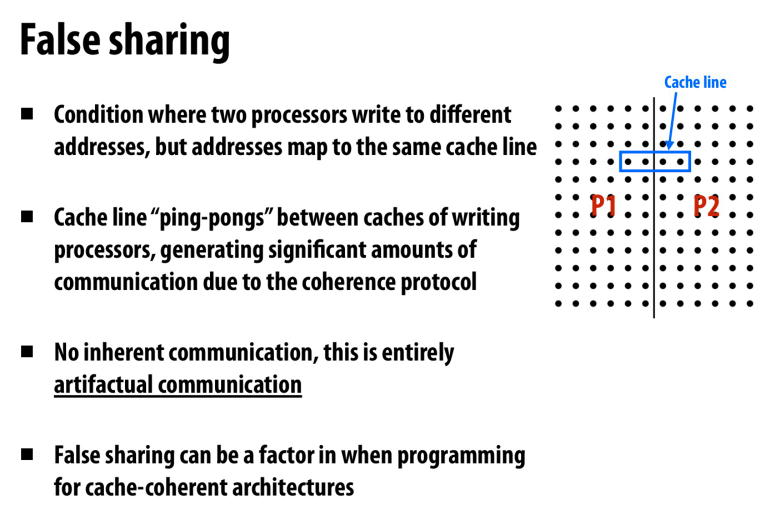
还有一个很有意思的一点是失效协议的false sharing

比如若干个独立的线程,每个线程会更新自己的值
但是这几个线程的值存储到了同一行cache中
失效协议就会导致cache line在不断的切换
下面的实现就为每个线程都用了自己独立的cache line,速度会提高很多

监听协议的总结
主要就是基于广播来将有可能影响到其他人的操作广播
但是会有scalability的问题,因为我们会受到广播带宽的限制
Lecture 11

分布式的目录
每个节点的目录上存储自己内存中的副本都在谁那里
通过维护那个节点持有这个副本来保证数据的一致性
感觉可以适用于memory level的一致性,也就是多个节点之间的共享地址的一致性
局部性友好,本地的数据不需要广播
但是一个节点内部在不受总线带宽影响下,还是用监听协议好一些?

主要还是防止在总线上广播,而是进行点对点的
因为拓扑结构不一定是全都相连的,所以广播是需要占用大量带宽的
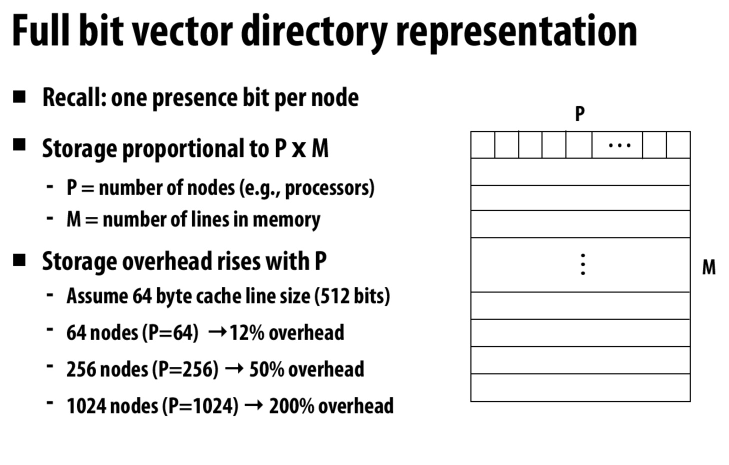
目录协议很大的一个缺点就是目录需要大量的空间
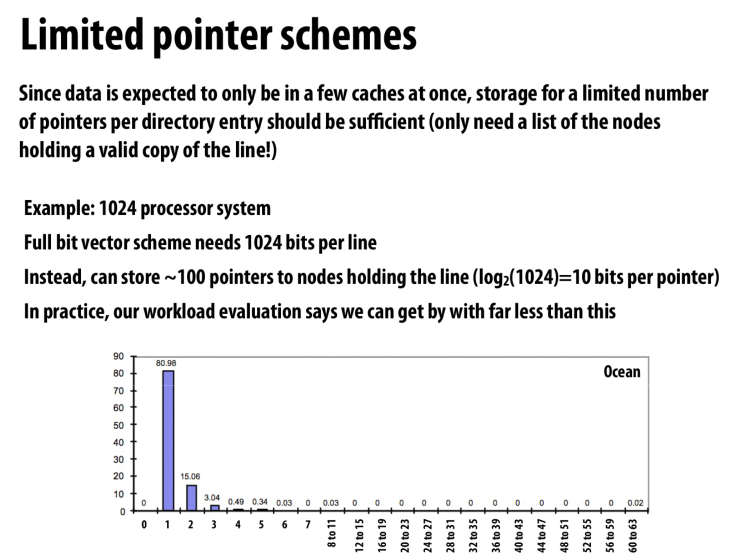
不存储全部的位,而是限制一下副本的数量
因为根据数据可以看到,需要很多副本的数据的情况是非常少的

point to point需要复杂的走线,而且不容易拓展
Ring-based容易拓展,并且更加简单
Lecture 12

cache的包含关系,之前有提到过

由于LRU的算法,可能导致L1和L2中被evicit的cache line不同
导致了L2无法再包含L1,所以我们需要额外的手段来保证包含的特性

处理invalidation的信号,当l1存在这个cache line的时候,也把l1中的copy设置为无效

处理l1的写命中
当l1写命中的时候,设置l2的modify-but-stale位
当需要l2去flush data的时候,检查对应的stale位,并从l1中请求对应的数据

有关活锁,就是不断的abort and retry
一个很经典的例子就是计算机网络中的载波监听
当我们检测到冲突的时候,就回退,并等待一个随机的时间
当冲突次数增多的时候,随机时间的范围也会加大,来保证减少再次冲突的可能性
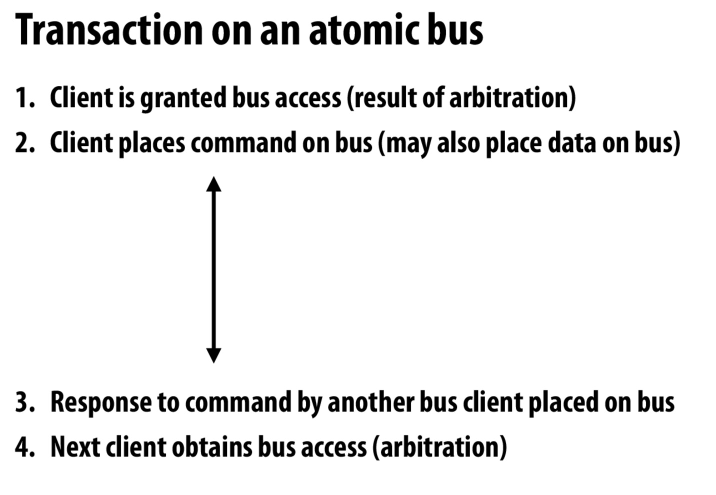
原子总线上的事务
首先要获取总线的权限,再去发送command,然后接收数据(可能带有回复)
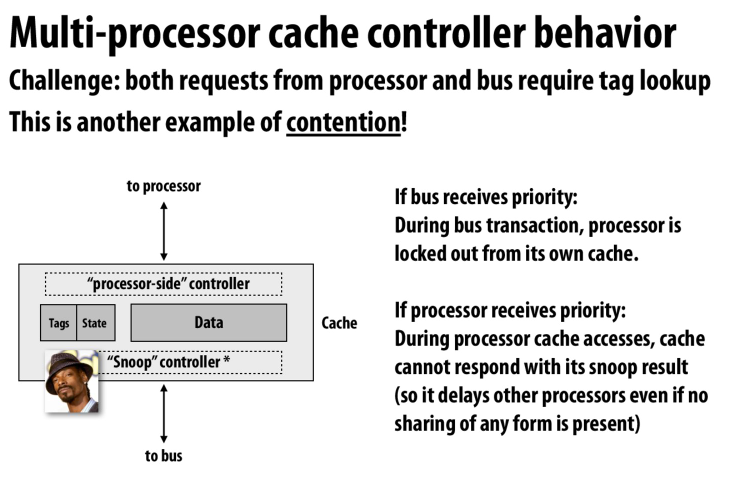
处理器读缓存和snoop controller读缓存出现了冲突
如果总线优先,那么处理器就会被阻塞在读缓存这一步上
如果处理器有限,那么snoop controller就会被阻塞,这样就会导致监听协议被阻塞,从而阻塞其他的处理器

解决方法,把有冲突的地方复制一下,这里我们会在tag上有冲突,所以复制tag
或者是多端口的tag-memory,允许同时的读写
但是注意对于复制的情况,我们仍然需要保证同步,也就是说我们仍然需要阻塞
有点类似MVCC的那种情况,利用副本解决读,但是对于写还是需要阻塞

通过写回缓冲来进行异步的读写,从而防止写回内存的操作阻塞接下来的操作
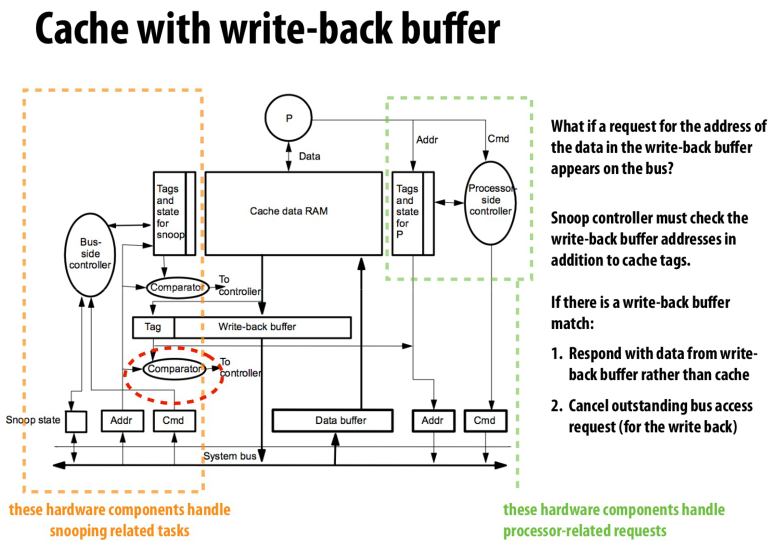
可以看到,总线上监听的地址以及操作会被controller接收
addr会与cache中的tag进行比较,同时他也会与写回缓冲区的地址进行比较
然后将结果送到controller中,controller再根据结果和总线上的指令进行对应的操作
右边则是processor的cache controller,只会进行总线的读写事务
这里还可以看到,写回缓冲的tag也有一条线在addr那里,表示要进行flush写回缓冲时要处理的数据项地址
所以processor side controller应该是具有总线读,以及写回缓冲写的操作

总线上的deadlock

总线上的livelock,两个processor都想写一个数据,然后开始互相invalidate其他人
我们需要保证在离开M state之前完成我们的写操作
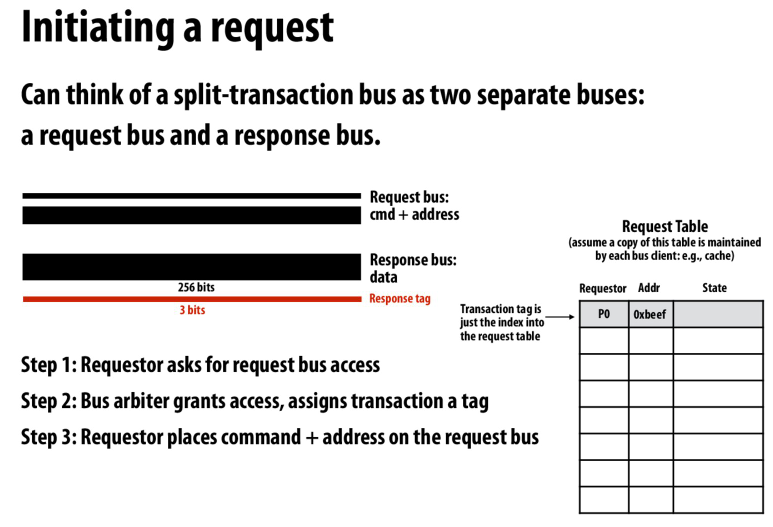
request table,用来match request和response
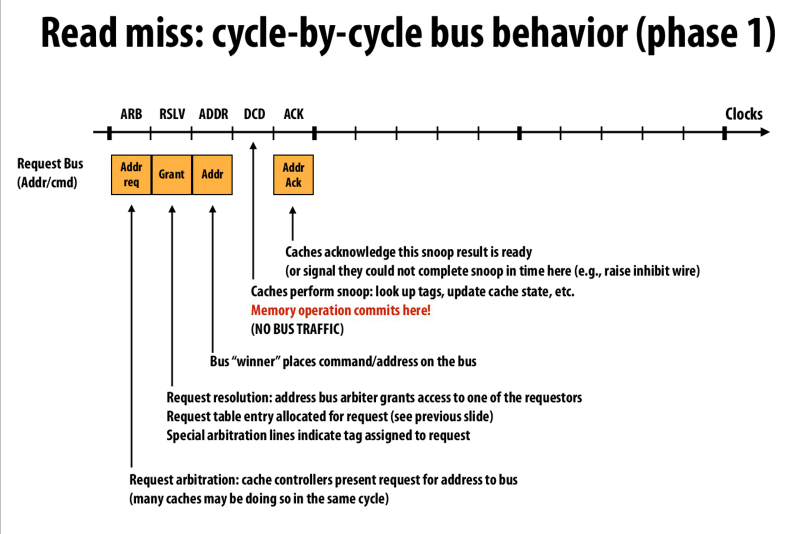
拆解后的总线事务
首先在request bus上申请,然后arbiter会选择一个processor并grant
得到grant的processor在总线上放地址和操作
然后等待其他processor进行监听
最后得到其他processor的确认(snoop-pending位)
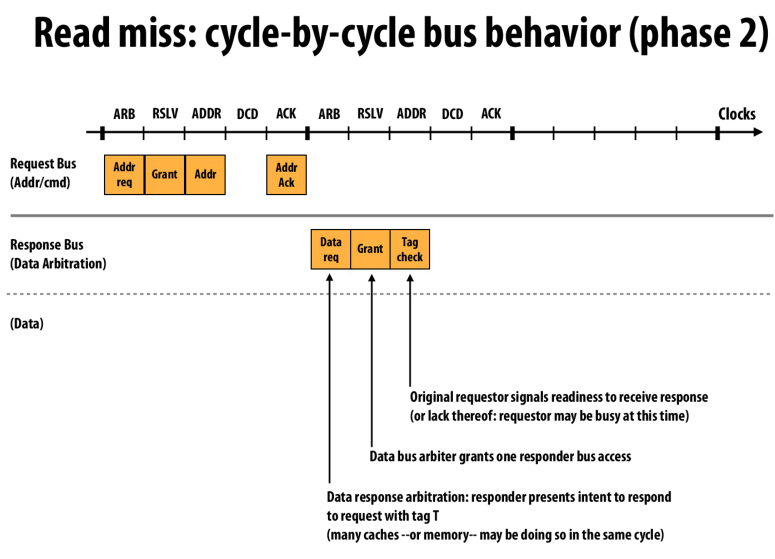
在response bus上,对应的部件(cache,memory)申请回复数据
arbiter选择一个请求并grant access
请求的发送者检查并发送信号表示准备接收(因为有可能请求者正在处理其他的数据)
(个人猜测这里,由于最后的检查这里有可能请求者正在忙,所以返回有可能是拒绝。所以responder可能释放总线并重启事务,或者发送到缓冲区中来防止阻塞总线和自己)
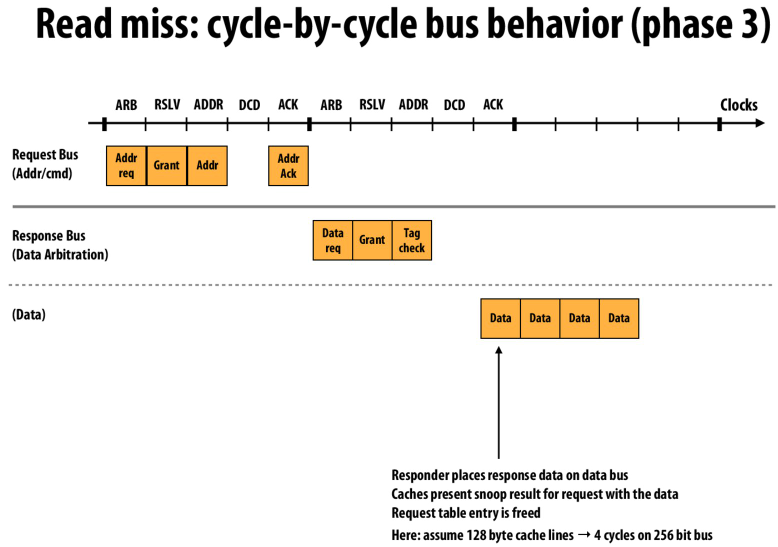
最后就是在数据总线中传输数据,然后释放request table entry
通过使用上面的方法,我们可以流水线化这个过程,从而增大吞吐量

和上面的猜测一样,都有缓冲区来接收数据
如果缓冲区满了就发送NACK,然后过一会儿再重试这个请求
出现冲突时,比如第一个cache请求一个内存中的读,当等待内存返回数据时,第二个cache可能请求一个在相同地址上的写,就出现了冲突
处理方法就是忽略冲突操作
当当前操作与request table中的事务冲突时,就不去申请当前操作(放入队列或阻塞)
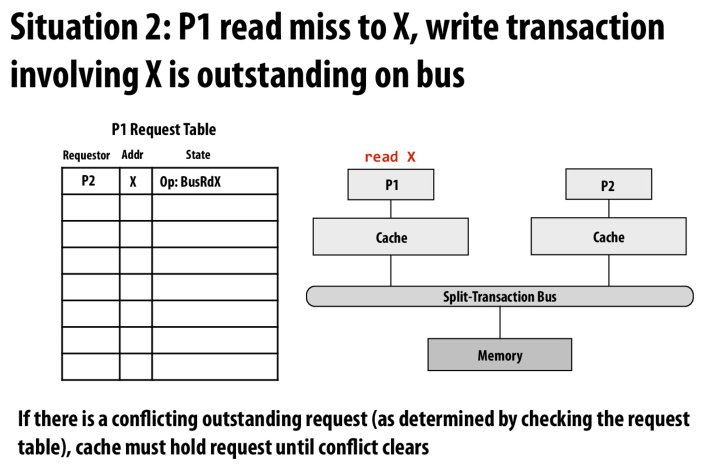
这里就是举的例子
这节课的最后,queue的重要性
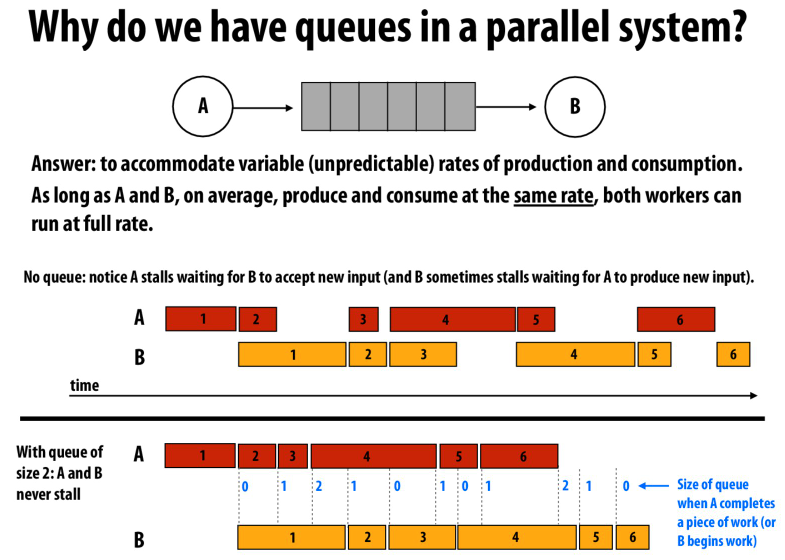
或者说是buffer的重要性

文章评论