Lecture 7

异步的send和recv,我们需要返回一个handle来检查数据是否已经被正确的发送/接收了,这样我们才能安全的继续操作数据

即便我们用了pipelined的方法来传递消息,只要缓冲区不是无限大的,我们还是会得到一个没有流水化的执行过程

计算强度,computation / commnunication,越高越好
说明算法的限制在计算,而非通讯

inherent communication,取决于我们的算法,通过优化算法来优化通讯成本
artifactual communication,取决于算法映射到的系统,比如每次访存,我们不是只取到一个元素,而是取一行cache

新的一种cache miss,由于多核之间的缓存一致性导致的cache miss
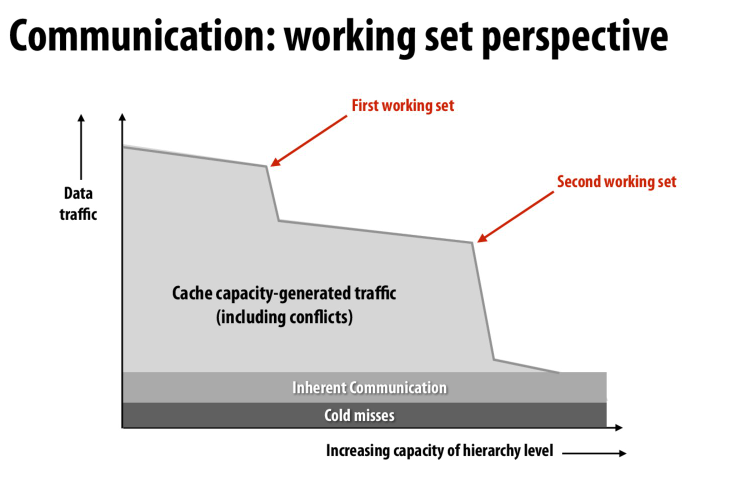
随着容量增大,cache miss在减少

通过改变遍历的顺序来提高局部性,就是分块遍历

通过融合计算来提高局部性,其实是减少了去访存的次数,将多次访存重叠到一起

communication的粒度就会影响我们之前提到的artifactual communication
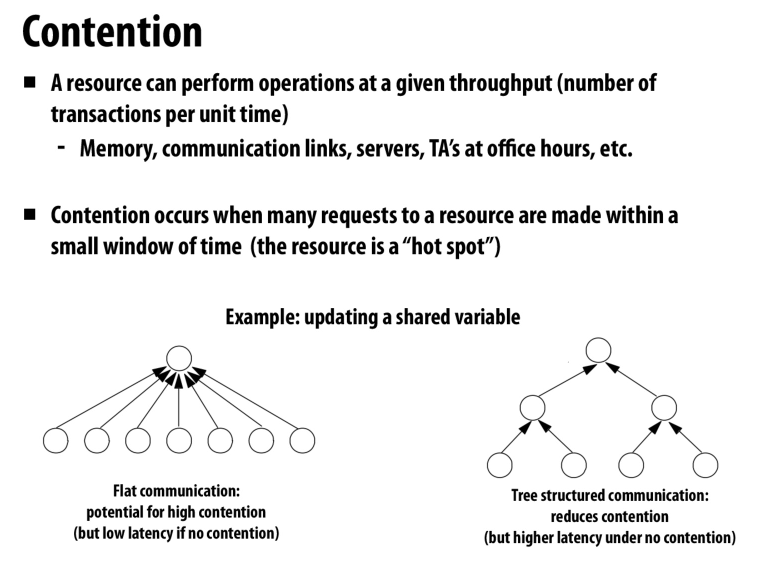
冲突
由于对某一个器件的突发使用导致的
中心化的一些结构的通病
之前提到的分布式的工作队列就可以很好的缓解这个问题,因为我们可以找空闲的队列来偷取任务,而不需要一个中心化的调度器

cuda中的contention
所以在cuda编程的时候,一个很好的做法是让一个核内可以有多个block
这样我们可以通过其他block中的线程来隐藏访存延迟
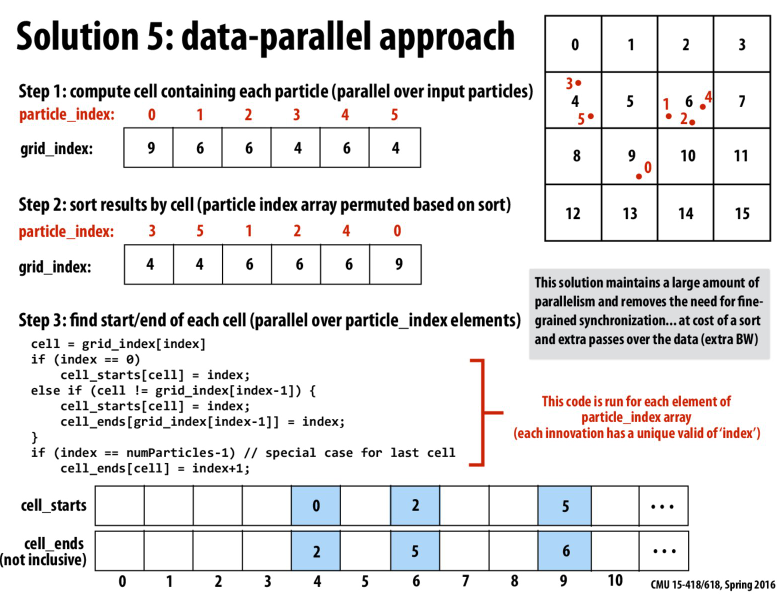
一个优化,首先计算出每个particle的cell,然后对他们排序,然后再对每一个particle,更新他对应cell的起始index和末尾index
这样第一步和第三步都可以并行,并且不需要锁,没有争用
但是需要第二部sort的额外开销
这里的第三步,其实就是检查每一个下标,如果他的前一个元素的cell和当前的cell不同,说明当前这个是当前cell的第一个,前面那个元素是上一个cell的最后一个(因为我们对cell排序了),根据这个更新start和ends就行

通过合并消息来减少通讯的开销
通过提高局部性来减少延迟
通过复制,交错访问冲突资源,或用细粒度锁来减少冲突
提高overlap,比如pipeline,多线程隐藏访存,预取

Lecture 8
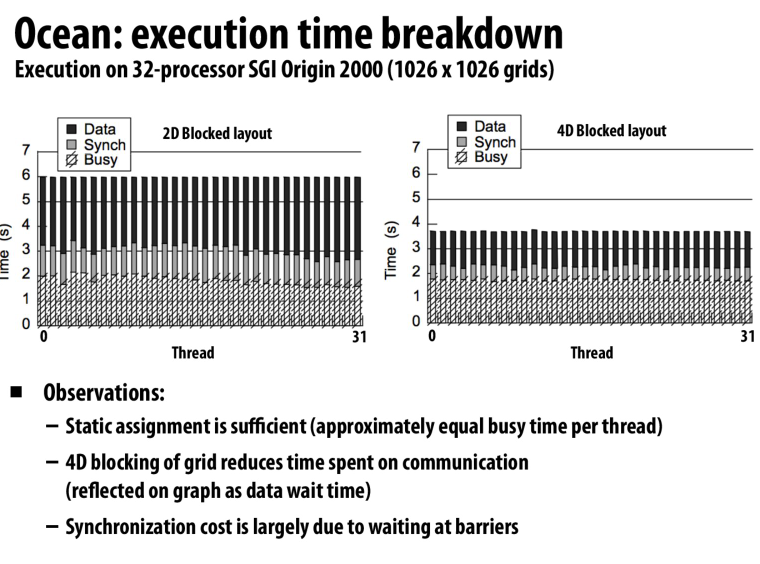
改变数据布局,从row-major到block-major
可以发现我们有了更少的cache miss,从而减少了同步时间
同时worker的busy time分布也更加均匀
课上老师推测是因为访存时间减少,使得每个处理器的步调更加一致,从而减少了同步开销
所以这些开销都是相互关联的,分析的时候要综合起来分析
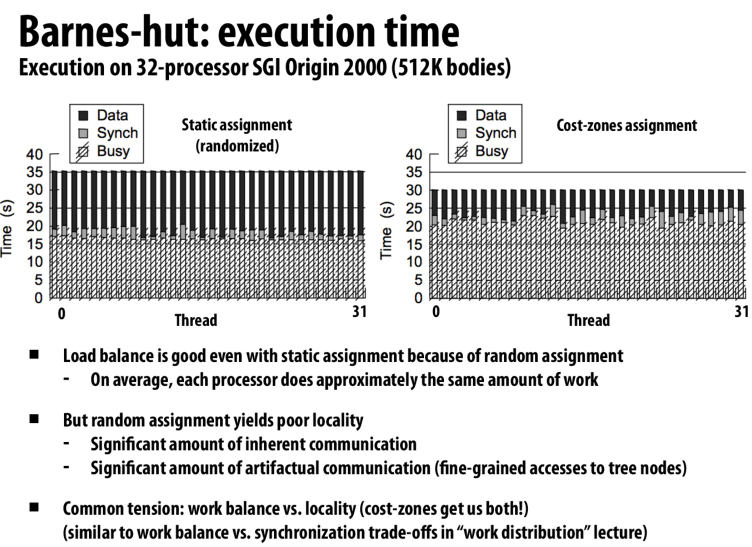
work balance和locality的trade off
右边虽然有更多的冗余计算,但是很好的利用了局部性,所以访存时间减少了很多

并行的计算前缀和

cuda中的实现
可以用很少的几个周期就计算出前缀和,主要是用于适用SIMD指令
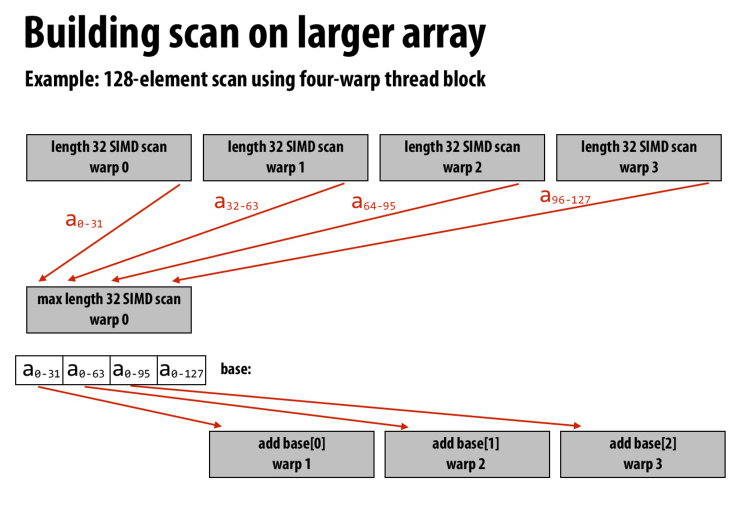
所以我们可以根据SIMD长度分块,块内使用更加快速的SIMD来计算前缀和
块间用一个线程计算块间的前缀和,再把前缀和分发到每一个块

代码就是这样的
用scan_warp计算块内的前缀和,线程0计算块间前缀和,最后每个元素再和块间前缀和累加
还可以继续扩大粒度
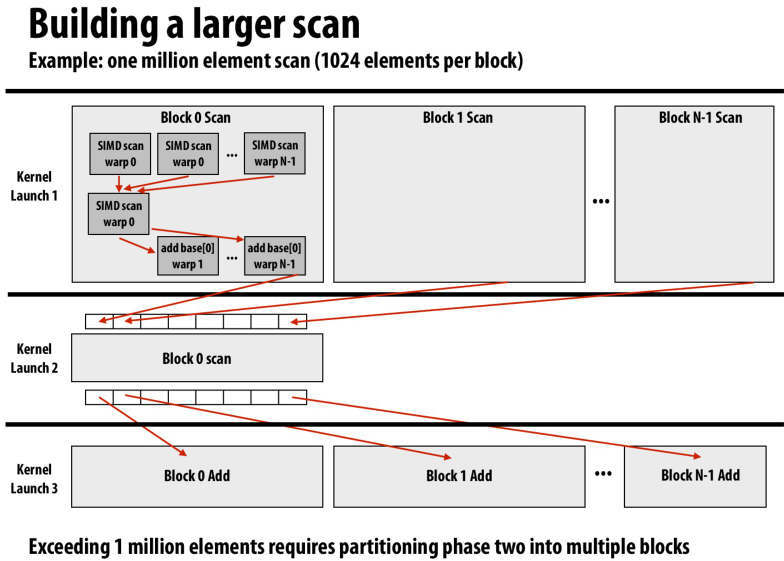
因为一个块内相互通讯代价少,所以先计算块内,然后再计算块间

segmented scan,我们有一个sequence of sequence,计算每一个sequence的partial sum
和前面不同的是,这里的sequence的长度是变化的
通过head-flag的表示法来划分每一个sequence,然后对前面的算法进行一些修改。我们根据head-flag来判断是否应该将前一块的和加到当前这一块
应用就是可以做稀疏矩阵的乘法

首先对x用cols中的元素gather一下(gather就是一个primitive,就是根据下标进行load,与之对应的还有scatter,就是根据下标进行store)
然后我们再根据row_starts创建head-flag数组
然后用上面提到的segment-scan来计算每个sequence的前缀和
最终就得到了最后的y
这里之所以不用SIMD加,是因为sequence是变长的
Lecture 9
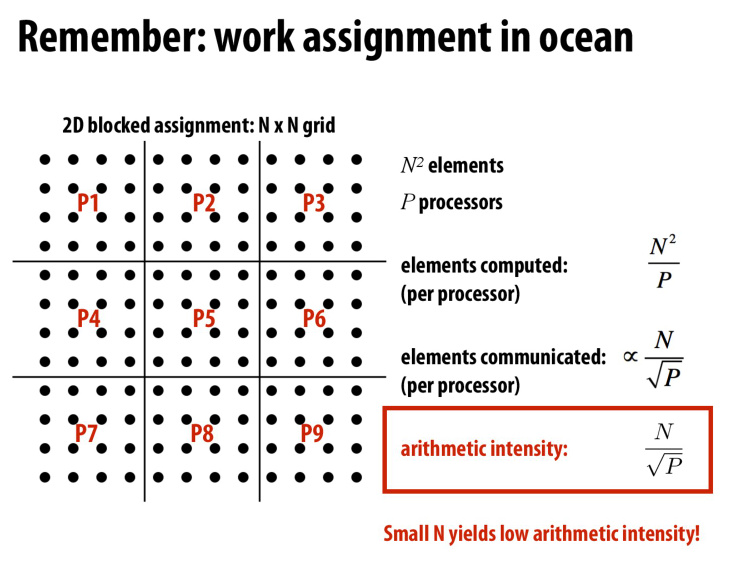
注意到,当我们提高处理器的数量的时候,我们会降低计算强度
这样就有可能导致communication bound
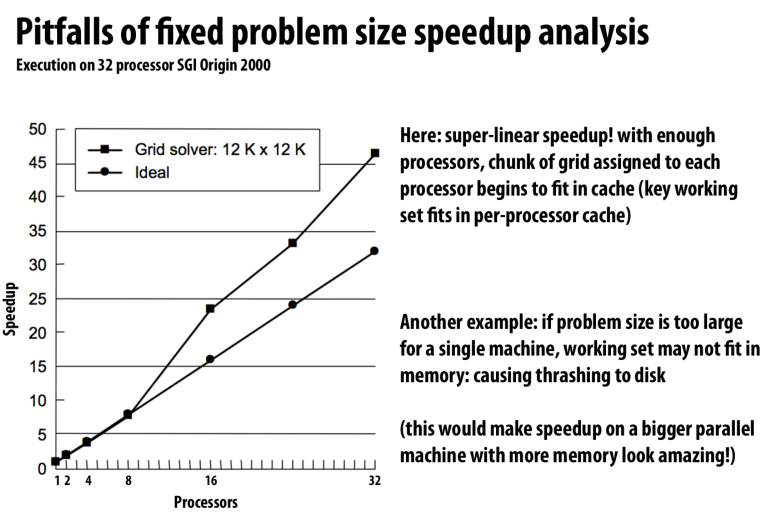
超线性的加速比
这是因为当我们提高处理器的数量的时候,会在某一时刻让这个处理器所处理的所有数据都存到cache中
这样可以大大提高我们的访存效率,以导致在这样的情况下工作的速度是大于之前相同规模下单核处理器的
因为单核处理器要处理cache miss等问题
所以在曲线的前半段,多核处理器也需要处理cache miss问题,而到某一个点的时候,cache能够装下整个workload,所以我们有了超线性的加速比

量化研究方法中提到的,强拓展性和弱拓展性
评估一个机器/算法的时候,在我们拓展核的数量的同时,也要考虑问题的规模是不是也要拓展

相同的问题,希望做的更快,用并行计算机来计算
也就是强拓展

在一定的时间内做出尽量多的工作
比如实时渲染,在一秒内渲染足够多的帧

对于大的问题,希望能把整个workload放入主存
所以需要大型的计算机来进行计算
又叫弱拓展,问题规模的增大和机器规模的增大是同步的
比如计算大规模的N体问题,就需要大规模的计算设备来把workload放到主存中,同时计算并不受时间限制
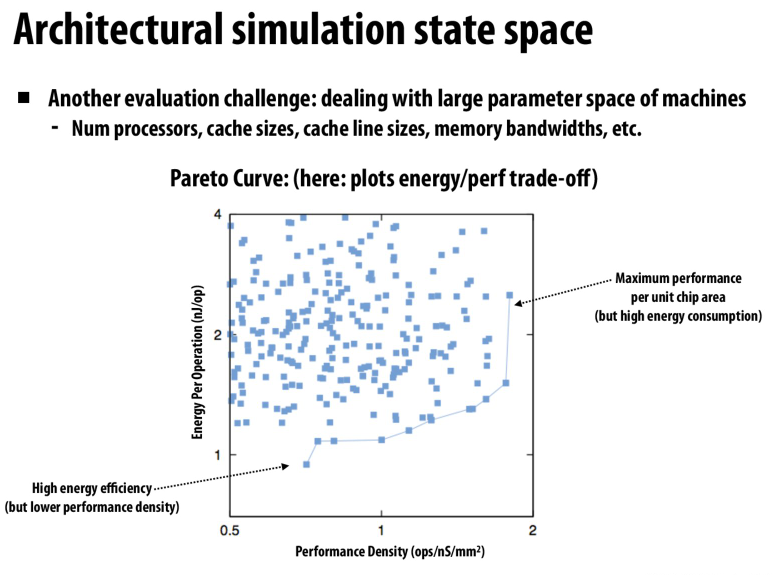
energy-efficiency和performance的图像
选择在pareto曲线上的配置来达到最佳的效果

检测性能瓶颈的一些技巧
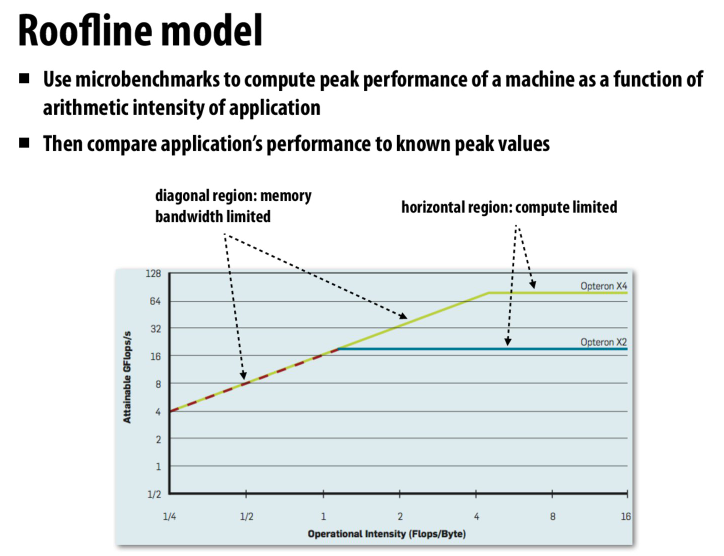
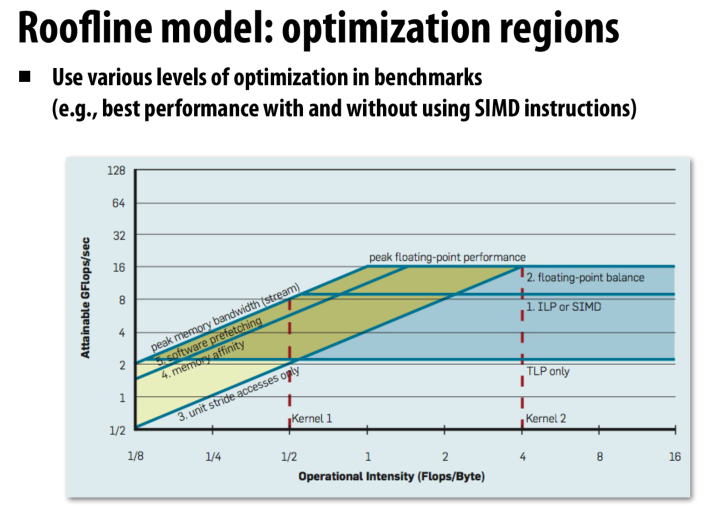
roofline模型中,之所以不同访存带宽的斜率是相同的,是因为我们用的是对数的坐标系
所以不同的访存贷款被取log后会转化成偏移量

文章评论