Lecture 4

截图比较诡异
这里老师问的是这段代码里那个for loop是parallel的
答案是没有,这整个函数都是按顺序执行的,真正的并发,或者说叫逻辑上的并发发生在调用函数的时候
这里是SPMD模型,相同的程序对应的是不同的数据。在abstraction层级,我们认为在调用函数的时候,ISPC会生成若干个program instance,每个instance有自己的progranIndex,他们都执行这段代码,只不过是每个instance负责不同的数据。
要注意的是这里是abstraction,ISPC最终还是会将这段代码翻译成SIMD指令,但是在abstraction上,我们认为是若干个instance在处理数据的不同子集

数据并行
以前是向量操作,现在是map reduce这样的,利用function或者算子来对数据进行独立的操作
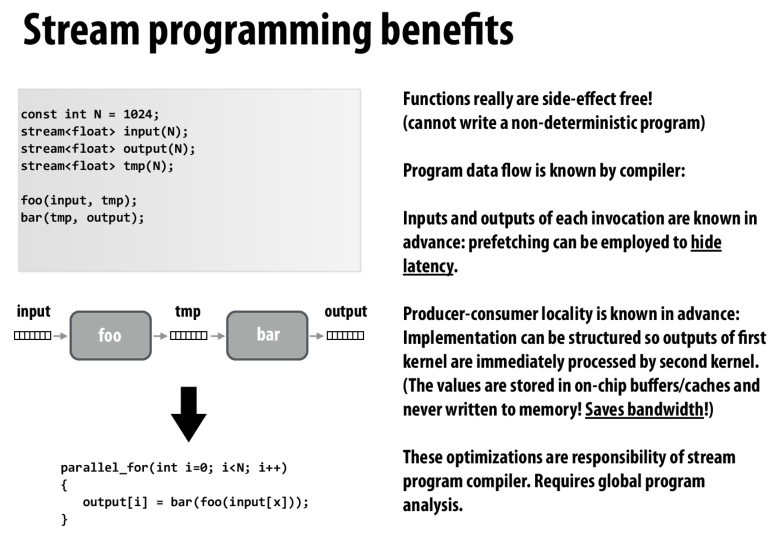
流式处理的好处:数据是提前准备好的,可以预取。第一个kernel的输出可以立刻应用于第二个kernel,利用了空间局部性,并且这些数据是暂存在cache中的,可以节省带宽。
缺点:operator不够用,需要库来提供更强大的operator,以及依赖编译器能够给出合适的代码

gather和scatter,通过给定的下标对数据进行读写

利用一些特定的程序结构来进行优化,比如functional programming
实际中,很多语言不强制要求这种模型,而是选择了灵活性以及程序员们更熟悉的命令式编程
functional thinking很棒,但是这些语言,这些框架应该利用这些结构来得到高性能的实现,而不是去妨碍他们。
个人理解就是如果我们强制使用了functional的形式,就会方案程序员编写更好的代码,也不容易得到更高效的实现,所以相当于是将一些编写高性能代码的责任从编译器转移到了程序员身上
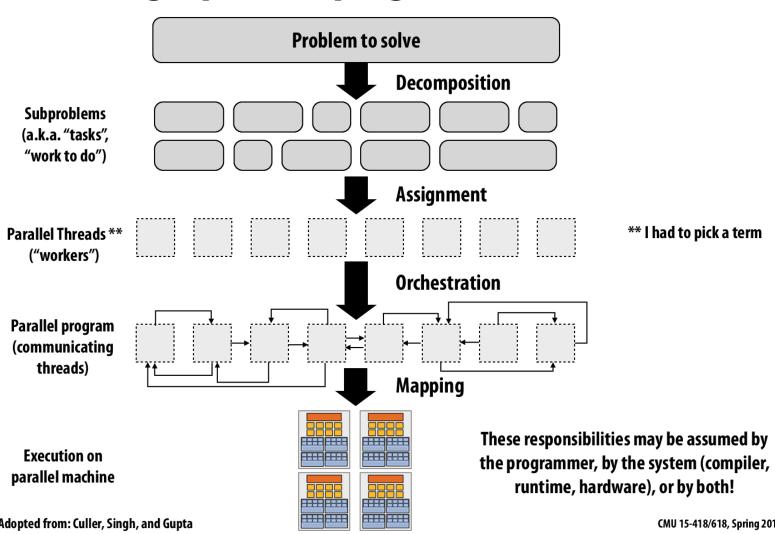
这里有一个很好的解释
- Decomposition: Most of the time programmer is responsible (does not have a sophisticated compiler to achieve this yet).
- Assignment: Many language/runtimes are able to take the responsibility. It could be done statically by programmer (Pthread workload assignment by programmer), statically by compiler (ISPC foreach) and also can be done dynamically (ISPC tasks).
- Orchestration: Most happens at runtime, but need to be declared or defined by programmer.
- Mapping: maybe OS (mapping pthread to CPU cores); maybe Compiler (ISPC assigns program instances to data lanes); maybe hardware (mapping CUDA thread blocks to GPU cores).

很经典的东西了,加速比被程序中可并行的部分所限制
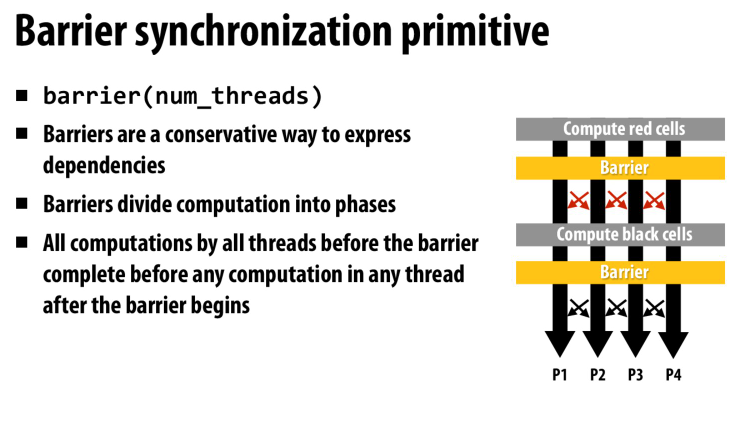
barrier,所有线程都执行到这里的时候才能继续
可以用一个原子加的计数器来实现
类似这样,就可以阻塞直到所有线程都执行到这里
atomic_ocunter++;
while (atomic_counter < num_threads) {
// do nothing
}

slide下面的comment
The first Barrier is to prevent the case that after some thread calculates diff, diff gets overwritten by other threads when executing diff = 0.f.
The second Barrier is to make sure that all threads has calculated their own diff, so the final diff is the sum we want before checking convergence.
The third Barrier is to prevent the case that some thread already on next iteration writes diff to 0, which will make the if statement true for other slower threads, leading to a wrong result.
Lecture 5
解释一个系统


渲染流水线,和之前提到的结构化的程序类似。这里是在流数据上去应用这些kernel

CUDA中,一个grid上有若干个block,每个block有若干个thread
thread可以通过一个最高为3维的多维向量threadID表示
代码中可以看到,threadPerBlock是(4, 3, 1),对应到图中就是一个block里,第一维是4个thread,第二维是3个thread
假设A,B,C是长度为(Nx, Ny)的矩阵
然后定义了numBlocks的第一维为(Nx / threadsPerBlock.x),第二维是(Ny / threadsPerBlock.y)
也就是说,每一个cuda线程负责了数组中的一个数据
具体的位置可以由cuda线程的threadID和blockID来标识
个人猜测cuda线程可能对应的是SIMD中的一个lane
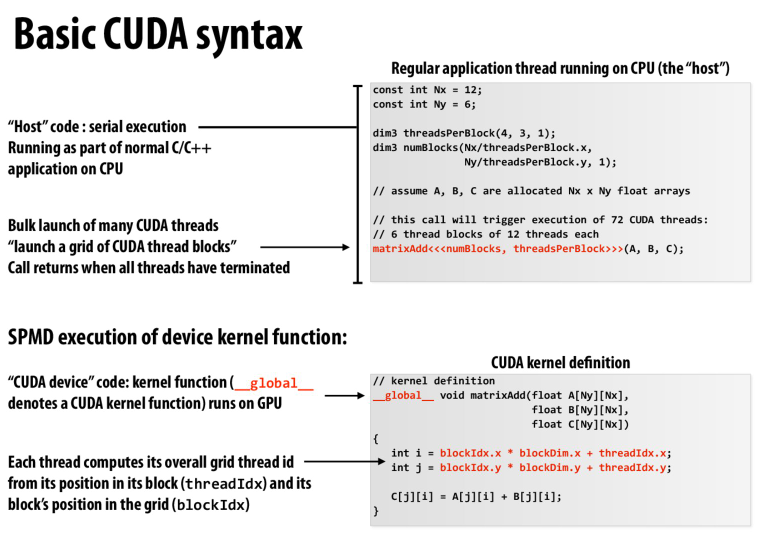
核函数具体的实现,可以看到数据的位置是由blockID和threadID共同确认的
调用核函数会启动一堆cuda线程,并在所有线程都完成后返回调用点
十分类似ISPC
根据课堂上将的,cuda和ISPC的不同在于,ISPC会创建一系列的instance然后映射到程序中,具体数量不确定?
但是cuda的线程数是确定的,在这个例子中,每个数据都是一个线程,一共就是72个线程
当然了这里都是abstraction,并不是硬件内部具体的实现

这里提到了. number of SPMD threads is explicit in program
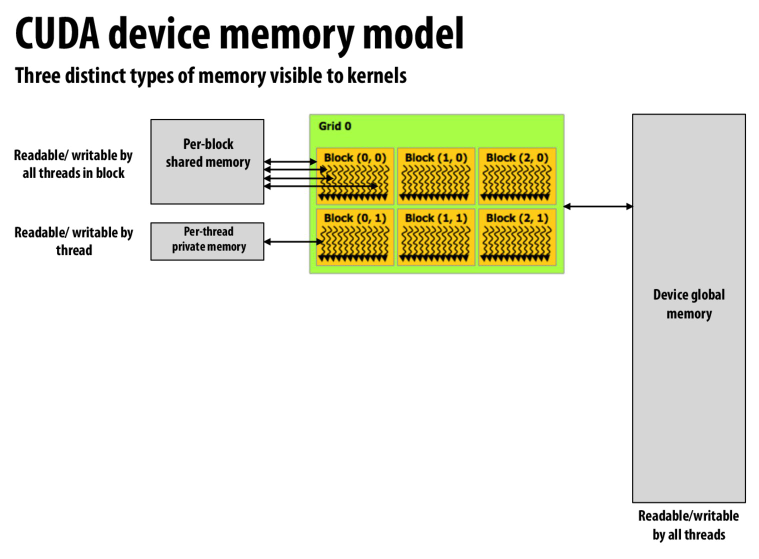
memory分为线程私有的memory,block内共享的memory以及全局共享的global memory

一个对cuda的总结
这里要注意的一点是这个

barrier是对block中的thread同步,跨block的thread不能通过这条指令同步

GPU的设计,block作为task,GPU core作为worker。通过代码可以提前得知每个block需要的资源,动态调度器就可以根据这些需求来将block分发到core上执行
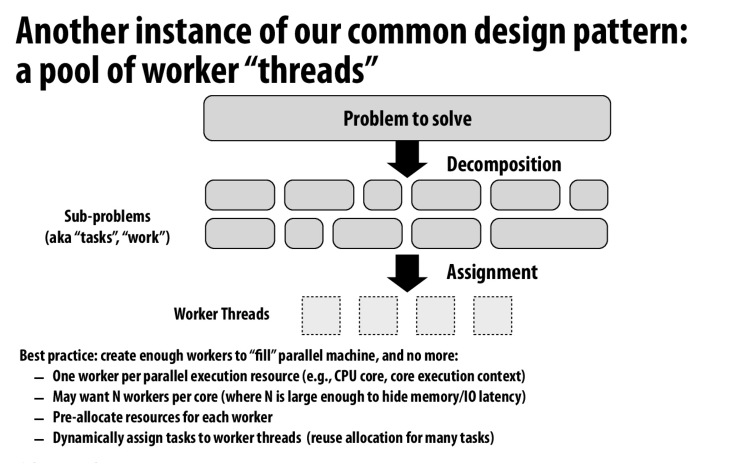
一个worker就是一个GPU core,或则一个execution context
每个核可能需要多个worker来隐藏访存延迟(多线程处理器)
不是遇到一个task就创建一个thread,而是提前分配好worker资源,然后再动态的调度task给worker

64个execution context。每一个核可以同时执行4个warp,每一个warp可以同时发射两条指令,并且有32个ALU单元
也就是说每一个clock,我们可以执行4*32=128次运算。
在刚才的例子中,4个warp就可以运行一个block,一个核就可以运行16个block。
所以一个cuda thread就相当于一个lane,一个warp就相当于一个thread
指令级并行:一个warp发射两条指令
线程级并行:一个clock可以运行4个warp
数据级并行:每个warp有32个ALU,也就是32个lane
看起来并没有hyper threading,因为貌似一次只能选4个warp

一个block上的所有warp都要在同一个core上运行

发射固定数量的block,task由程序员来调度
这里每个block就相当于一个worker,他们通过原子加的方式,以block为粒度来执行这些task。 i.e. 每个block每次都会申请threadPerBlock这么大的工作量执行,内部就由cuda thread执行(SIMD + 多线程)
也就是说,发射block的数量不取决于工作负载,而取决于硬件资源

abstraction中,每一个block对应的就是SPMD中的一个program instance。而cuda thread则是对应不同的数据,或者叫不同的lane
implementation中,block被分割为同一个GPU core上的若干个warp。分布于同一个core中允许不同的cuda thread之间执行高效的通信以及同步。warp则是一个execution context,他们执行的是SIMD指令
这样看的话,一个block中线程的数量最小就是warp中lane的大小,最大则是整个core中lane的大小
量化研究方法中,说GPU是多线程多SIMD处理器
按照上面的例子
第一个多就是多线程,也就是一个core中可以存储64个execution context,并最多有4个execution context执行
第二个多就是多核,一个GPU上有很多的GPU core
SIMD便表示每个warp执行的指令都是SIMD指令,多个lane,同时操作多条数据
还有一个隐含的点就是指令级并行,每个warp同时发射两条指令,图中只画了执行单元,可能另一条指令做标量运算,或者进行访存
有关上面说的hyperThreading,或者叫SMT。因为SMT是用来发现指令之间的独立性,以利用execution unit的。GPU中我们已经在cuda上表达了代码的独立性,因此GPU有足够的线程和指令来利用这些资源。所以GPU不需要SMT
说白了就是GPU线程已经很多了,不需要再自己去想方设法提高并行度了。
还有一种理解的方法,就是GPU已经支持了SMT了,因为我们本身一个clock就可以执行4个warp,也就相当于4个线程了
Lecture 6

implement simplest solution first
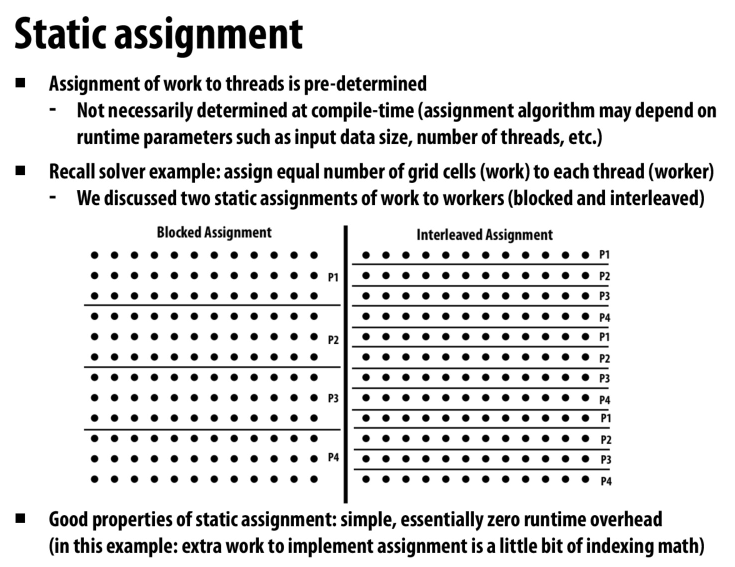
用指定数量的worker去完成任务,实现简单,开销少,但是需要我们提前对工作负载有一定的了解
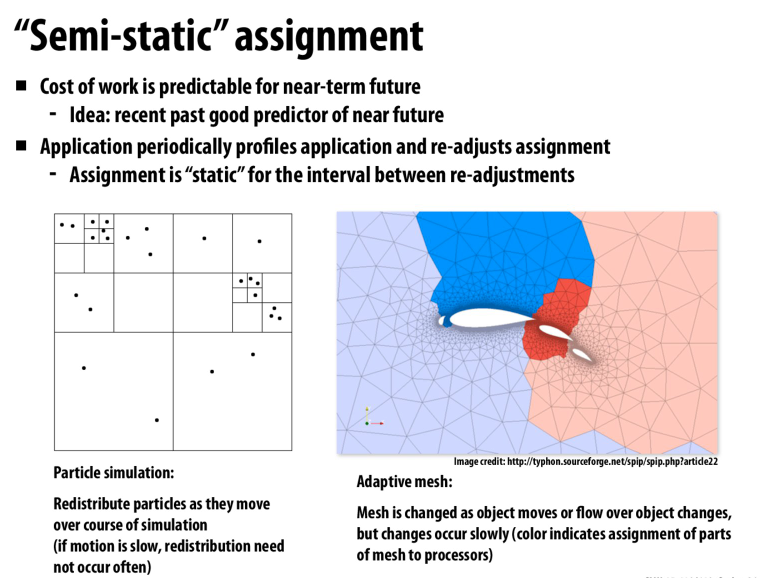
半静态的分配,每过一段时间就重新分配负载
因为这些问题的负载是相对可以预测的,我们不会突然在下一时刻跳到一个很差的schedule中,如果当前的schedule是比较好的,那么接下来一段时间也会是相对较好的

为了平衡通讯开销,我们需要调整任务的粒度,比如更大的粒度可能会减少通讯的开销,但是也可能导致负载不均衡的问题
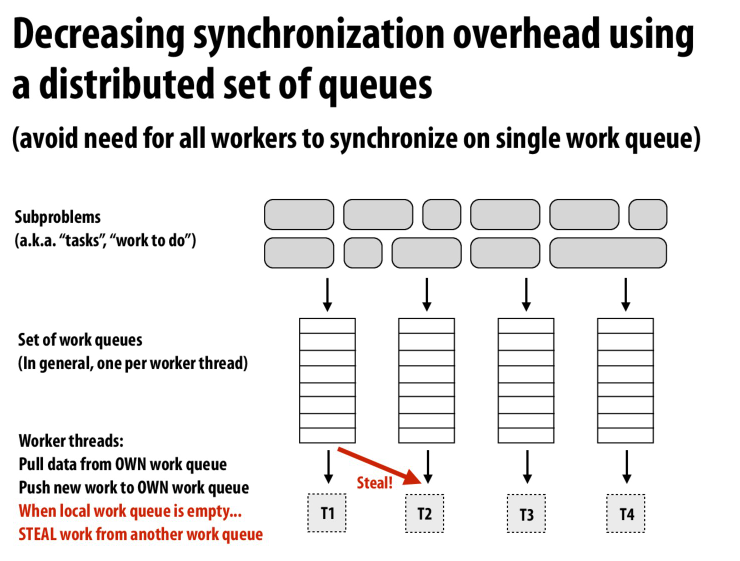
每个worker一个工作队列,当本地的worker工作结束,他可以去别人那里偷任务
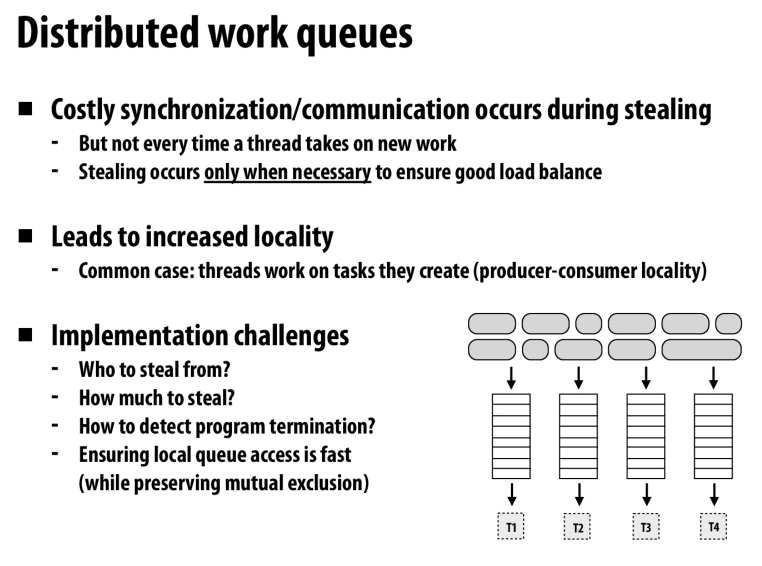
一些分布式的work queue的优缺点
适用于分布式系统的计算中,这时从其他节点去偷任务的开销就会比较大
但是在本地的计算会有很好的局部性,这个概念同样适用于单个节点(在cache中的任务和在memory中的任务),NUMA架构等
queue还有一个很好的性质就是他是按序的,只有前面的任务完成了才会执行后面的任务
也就是说队列中的任务不必是独立的,他们可以是有依赖的。按照拓扑序完成任务就行

最终目的都是以尽可能小的开销去平衡各个worker的工作负载
对于用户来说,就是根据application去trade off。

天然的适合去并行化一些用分治思想解决问题的程序
fork相当于创建一个异步执行的函数
而join则是用于同步这些异步的函数
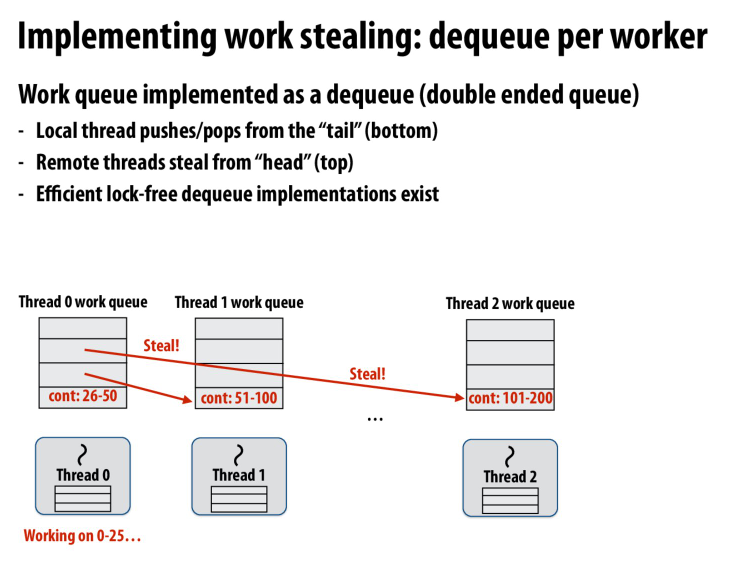
最下面的任务对于当前的核来说有更好的局部性
所以让其他的核去偷队列上面的任务
同时队列上面的任务在分治问题上的规模较大,这样我们就可以不用总是去偷别人的任务
这里还提到了一点就是lock-free dequeue

优先去执行child,并将后续的部分留给其他的worker来steal
好处就是如果没有spawn的话,执行顺序和串行的执行顺序是一样的
并且还有个好处就是不会由于生成大量的任务导致空间的浪费
因为后续生成其他任务的逻辑可能会被其他worker偷走

run child和从上面偷取任务的结合来提高局部性

实现sync,记录一下目前完成的task数,所有都完成时就达成了sync
spawn child的线程不一定是sync之后继续执行的线程。可能是执行sync的线程来执行后面的逻辑,前面的ppt貌似表示,是最后一个完成task的worker执行后面的东西,包括同步以及后面的逻辑
其实准确的说,就是因为后续的部分被偷走了,谁偷走了后续的部分谁就负责去执行后续的逻辑
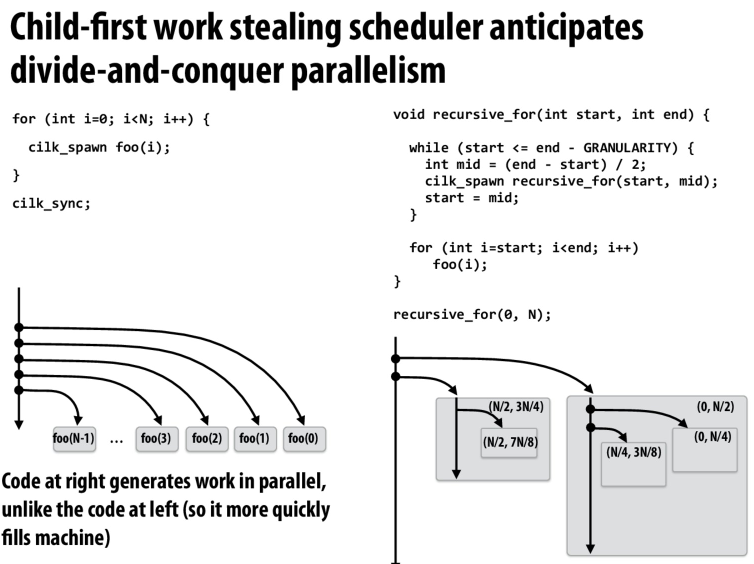
偏向于右边的代码,因为他不仅可以以并行的方法生成代码,而且会减少steal的时间
其他的worker会去偷规模较大的问题,以减少偷窃任务的次数,从而减少偷窃的开销

可以这样想,我们每次将问题分成一半,那么问题就会被划分成一个二叉树
run-child表示我们优先去遍历子节点,那么剩下的一半就留给其他的线程
当其他的线程来要任务的时候,他们总是会找队列最上面的任务,也就是偏向根节点,深度浅的任务。
那么每个线程所执行的任务就相当于是问题树上的一个枝,这样就提高了局部性
这样可以自然的拓展到多叉树,每次挑选问题的一个分支去解决,剩下的就留给其他的分支去解决。不仅有较平衡的工作负载,同时还达成单个线程的局部性,以及减少通讯开销
妙
想到一个比喻,比如任务是几个人一起吃葡萄
第一个人拿到这一把葡萄,摘掉其中的一枝(上面可能有多个葡萄),然后开始吃,然后把剩下的放到自己面前
剩下的人重复同样的操作,他们从有葡萄的人那里拿葡萄过来,摘掉一枝,然后剩下的放到自己面前
这样自己的葡萄吃完的时候,就可以找自己面前还有没有葡萄(局部性)。当自己面前的葡萄也吃完的时候,就可以去拿其他人面前的葡萄吃(平衡负载)
他们由于比较懒,想少去别人那里拿葡萄,所以每次都挑最多的那串葡萄拿(减少通讯开销)
这就是Cilk的implementation

文章评论