Lecture 16

run一个thread都涉及到了什么
比较常规的知识点,选择一个execution context,设置状态(pc, stack等),然后开始执行
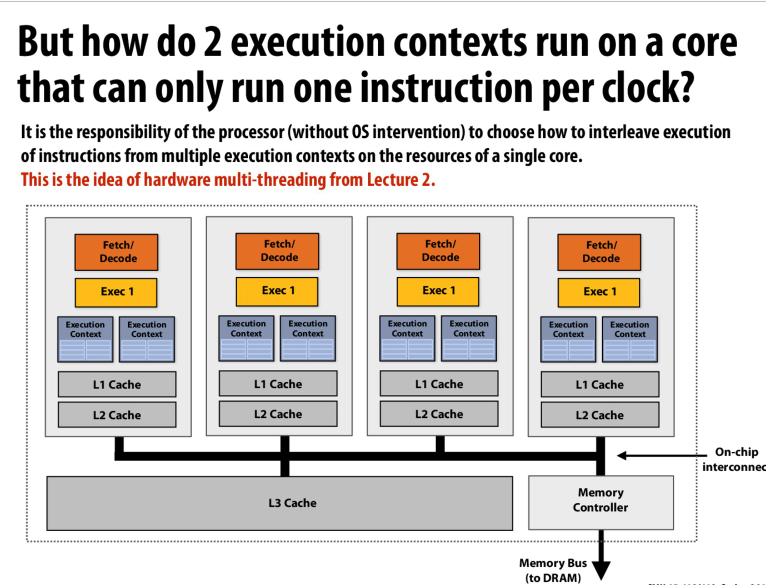
对于同一个core上的multithread来说,os并不负责
os只负责粗粒度的调度,保证每个进程都能分享硬件资源
但是在硬件中利用多线程隐藏访存延迟的角度来说,用os调度代价太高了。所以在一个核上的若干个execution context,是由硬件来调度的

比如数据库中的latch,利用自旋锁实现就更好一些。因为这些都是轻量级的短时锁,不会等待太长时间。但是如果用blocking的锁,切换execution context,利用系统调度会需要更长的时间
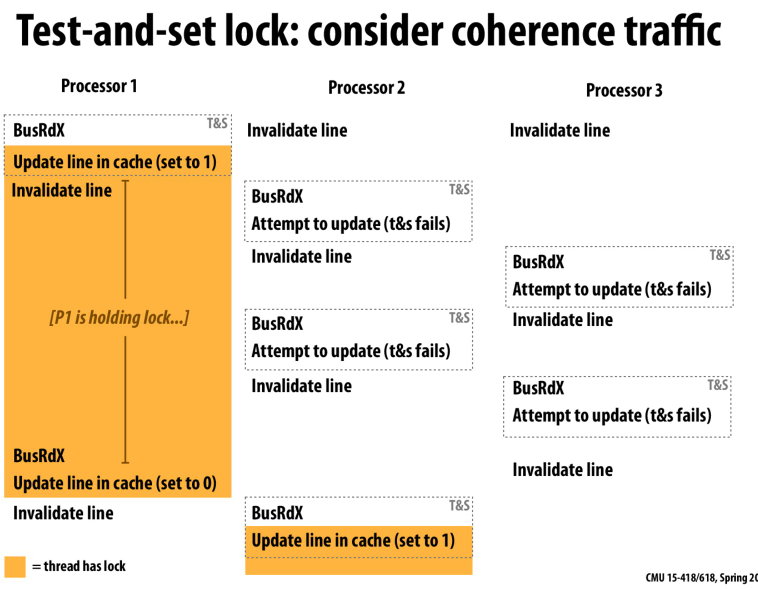
最简单的test-and-set的实现情况下,由于缓存一致性协议,其他的processor会不断的请求独占状态进行更新,从而导致占用大量的总线带宽

减缓traffic的优化,不是每次通过tas来发出read-exclusive的指令,而是先读。当有机会获得锁的时候再进行tas

Ethernet的解决方法,没有成功获得锁的时候就回退
但是不保证公平性,可能会有starvation
但是基于TAS的方式在一个锁释放以后,我们会有P个写操作来自P个处理器,也会出现大量总线带宽

队列的方式,保证公平性
并且不会出现大量总线带宽,因为我们只会进行一次写,而不是P次写

上面的解决方法中,每次释放锁会invalidate P个processor,因为所有processor都在等l->now_serving
但是这里,释放锁的时候只会修改下一个要获得锁的处理器,所以只会出现一次invalidate
从而优化了总线带宽

利用CAS来实现一些原子操作
完成操作后然后利用CAS来写入结果
但是CAS会遇到ABA问题,在这个过程中有可能已经有人该了原本的值又改了回来,但是CAS检测不到

相当于在LL和SC指令之间创建临界区
当有人修改过LL指向的地址的时候,SC将会失败
(不太清楚的一点是老师上课说这个在不支持cache coherence的处理器常用,但是我认为在支持 cache coherence的处理器中这个更加善用,因为我们可以简单的在过程期间检测总线事务,如果有写ll对应地址的事物,则让sc失效即可)

最简单的方法实现barrier
但是在相同barrier上进行多次等待的时候会出现问题

在到达第二个barrier之前,保证所有的processor都离开了第一个barrier

还有一种方法就是设置相反的flag位
比如第一次的barrier,所有processor都在等待flag变成1
第二次的barrier,processor就会等待flag变成0。并且由于当我们可以到达第二个barrier的时候,flag一定变成了1,所以在第一个barrier等待的processor都可以继续,并且都会被第二个barrier阻塞
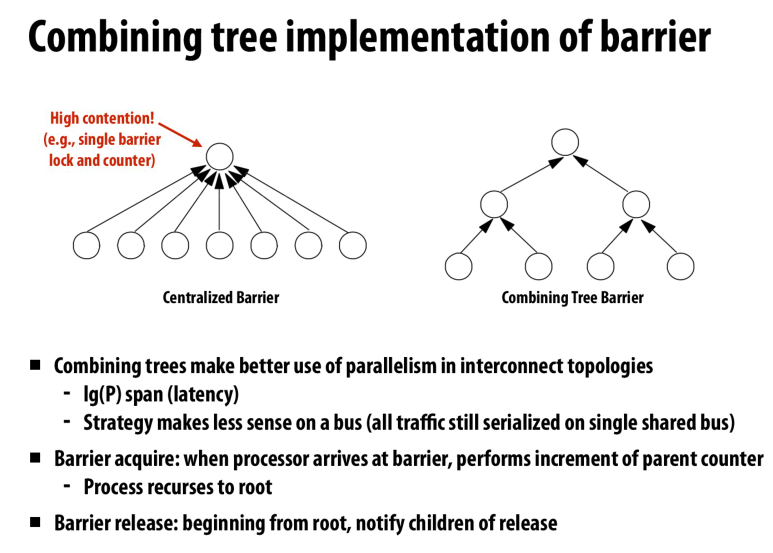
但是无论怎么优化,我们都需要写操作来获取锁并增加barrier counter,所以复杂度仍然是O(p)
因为我们用的是中心化的barrier
利用combining tree来让barrier去中心化
每次操作就只需要在logP上的barrier进行操作
感觉counter只会有一次写,只有最后的txn才需要读
所以主要的消耗还是在barrier共享的锁上面
用原子加和TAS来解决这个问题?原子加负责counter,TAS负责flag
但是原子加也需要总线带宽
这里也提到了,用合并树并不会改善总线带宽的情况
但是会减少latency
所以这种做法可能是在其他的interconnect结构中使用,比如在树形结构中,我们的效率就会高很多
Lecture 17

一个最简单的sorted linked list上的插入和删除
但是不适用于多线程,不可重入的
添加多线程支持的最简单的方法就是为这个数据结构加一个锁
同时只允许一个线程进入到代码中
但是粒度过大,并发度不高

细粒度的实现
思路和数据库中的并发B树的latch crabbing protocol一样
我们在遍历的过程中,要先拿到前一个节点的锁,才能走到下一个节点并获得下一个节点的锁。然后才能释放前一个节点的锁
就像是monkey bar一样,一个手抓住,第二个手也抓住了以后才能释放第一个手
这样可以保证我们操作的值都是有效的
具体的在实现中,可以看到代码里对list也有一个锁,这是因为在最开始的时候我们要获得表头,但是要注意的是我们相当于直接抓住了表头的这个节点,但是我们并没有一个手抓住之前的节点。
这里的list的锁就是相当与head之前的一个虚拟节点让我们抓住,也可以理解成是为了保护表头而设置的单独的一个lock
同时,由于链表的特性,我们也要保证在修改一个节点的时候,要拿到这个节点和他的前一个节点的锁
代码中有个有问题的点是,我们需要拿到当前点的锁才能读下一个节点的地址,但是这一点在表头处没有处理好
考虑这样一种情景,第一个线程要删除第二个节点,所以拿到了第一个锁和第二个锁
第二个线程读到了prev和cur,然后第一个线程释放了cur的内存。这时第一个线程的cur就会是指向一个被释放的内存处
有一个优化是如果我们有当前节点的锁,那么我们可以保证接下来的节点是不会被删除的,虽然指针可能变化。
但是我们可以确定值是不会变的,所以我们可以延迟锁的时机,当要修改节点的时候再锁,读值不需要
还有一个优化是用读写锁,而非互斥锁

blocking的算法就是允许一个线程阻塞其他所有的线程,当一个获得锁的线程被OS暂停时,其他的线程也就不能继续往下走

而与之对应的则是lock-free的算法,他能够保证正在运行的线程可以make progress,而不会被休眠的线程阻塞

最基础的实现,在添加节点的时候,用CAS原子指令来检测过程中是不是有其他的线程修改了我们需要的数据
其实相当与之前课上说的用CAS实现一些操作,这里就是修改新节点的值和指针,然后用CAS判断原节点是不是没变,然后利用CAS将结果写回
但是这会遇到ABA问题,因为我们只是简单的比较了指针的值,有可能在这个过程中其他的线程复用了这个指针的值,但是指针指向的节点已经改变了

通过记录pop的数量来防止ABA问题的发生,这需要机器支持额外的指令。比如双字的CAS,才能保证我们同时对原指针和pop-count进行CAS
还有一个问题就是我们pop的时候,需要首先获得原始的栈顶,然后判断是否为空,再获取第二个元素作为新的栈顶。在这个过程中,可能我们在获取新的栈顶的时候,原本的栈顶已经被delete掉了
在GC的语言中,这是没问题的,因为我们这个线程对这个对象有引用,所以这个对象不会被删除
但是在C语言中,在其他线程中可能就已经delete掉这个元素了,不会进行判断

用hazard pointer,我们每次删除节点的时候,将他放入到retireList中
当retireList值较多的时候,我们进行删除(有点类似GC)
但是删除的时候,判断每个节点是不是存在于其他线程的hazard pointer中
但是实现这个判断过程也需要一定的trick,因为这是一个多人读,一个人写的过程
难不成要用R/W lock?

为什么lock free
比如我们在临界区的时候,出现了page-fault,阻塞了大量了线程
或者在临界区崩溃等问题

lock free就是为了去避免lock出现的开销(以及上面提到的问题)
而且lock free仍然需要类似lock中的memory fence来保证内存的一致性
他并不会缓解竞争,所以具体的使用还是要根据情况决定
Lecture 18

事务内存的优点
主要是提高开发效率,想对于锁来说代码更加安全,并且performance也不低

如何存储数据
eager versioning就是直接写,然后通过log来回退
lazy versioning则是写到buffer中,commit的时候再真的写进去

乐观和悲观的conflict detection
悲观的detection和eager的配合,因为每一次load and store都会检测,所以写到内存中没问题
乐观的detection和lazy versioning配合,最后commit的时候检测缓冲区
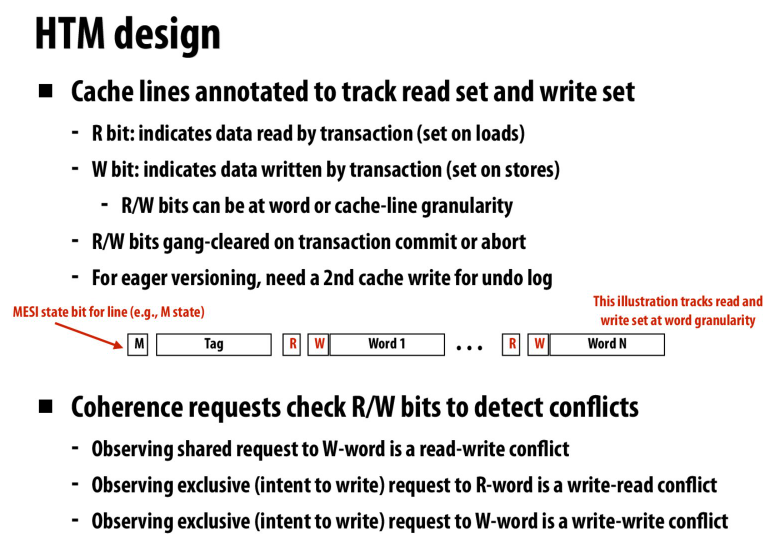
硬件中的设计
为cache line添加R/W位,用来指示cache line在读写集合中
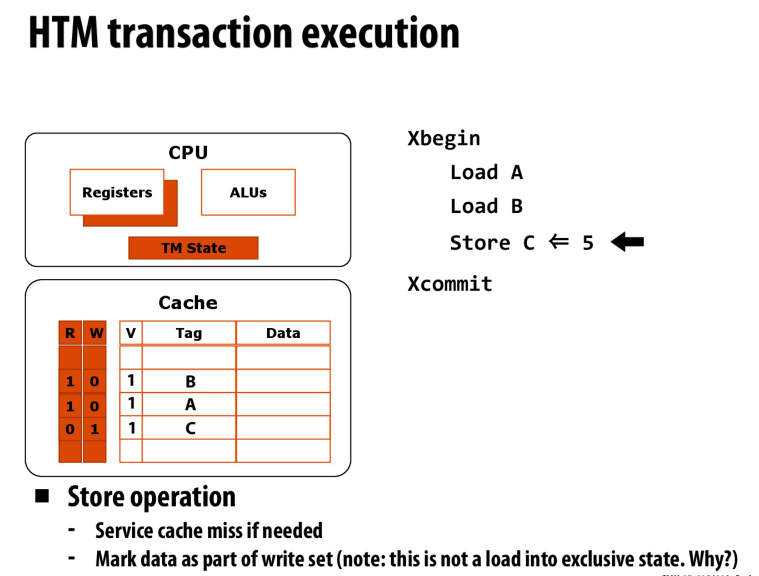
lazy + optimistic
对于load,读取数据到cache line中,并标记为R
对于store,同样读取数据到cache line中,但是在缓存一致性协议下,不进行总线读请求(exclusive)
因为我们不想让别人知道我们在写(写在本地的l1中,不想让其他核看到)
然后在提交的时候,对于cache line中的数据发出总线请求,其他的处理器会看到这里的请求,并检测是否有冲突,然后abort
特别的,如果我们的数据超过了l1的容量,那txn必须abort

通过硬件支持的txn memory来加速事务处理,然后通过软件在这个基础上进行利用
比如拆分一系列操作为小的操作,然后用txn memory来加速

文章评论