先看这篇博客理解一下dispatch的高层设计
https://blog.ezyang.com/2020/09/lets-talk-about-the-pytorch-dispatcher/
DispatchKey
Dispatch key是64bit中的某一个bit。bit位越高优先级就越高。
这块很多的设计都可以从DispatchKey.h中看到设计
有一个关键的设计就是dispatch key被拆分成了两块,分别是
- 48位的functionality
-
16位(目前)的backend,包括CPU,CUDA,XLA等等
拆成两块的核心目的是为了节省bit,避免64bit无法表示一个dispatch key。
两者共同组合形成真正的runtime key,所以严格来说一个dispatch key也可能是两个bit。
函数isPerBackendFunctionalityKey判断了那些functionality是可以根据per backend做定制的。toRuntimePerBackendFunctionalityKey则是对应的拼接逻辑。会把functionality和对应的backend拼接到一起。
这里要明白的一个核心点就是dispatch key在dispatch key set中是64bit的,相当于是一个压缩的表示。但是真正拼接出来之后是有很多的(不局限于64个),可以叫runtime dispatch key,此时会再根据这个dispatch key去dispatch table中查找对应的op。
注释中提到的几类dispatch key:
| 分类 | 例子 | 特点 |
|---|---|---|
| (1) 不可定制的 backend | FPGA、Vulkan、Metal |
不需要按 backend 拆分 autograd/sparse,省一个 bit;独占 bit + 独占 runtime slot |
| (2) 不可定制的 functionality | Functionalize、Conjugate、Negative、BackendSelect |
全局只有一个 handler |
| (3) 可按 backend 定制的 functionality | Dense、Sparse、AutogradFunctionality |
只占 1 个 bit,但映射到 N 个 runtime slot |
| (4) (3) 的 per-backend 实例 | CPU、SparseCPU、AutogradCUDA |
不占 bit,但占独立 runtime slot |
| (5) alias key | Autograd、CompositeImplicitAutograd |
暂时跳过 |
- 这里的runtime slot说的就是dispatch table中的一个slot,对应一个op
-
1 + 2 + 3这三类有具体的bit,会出现在dispatch key set中
-
1 + 2 + 4则是有dispatch table的slot。
- 3 -> 4的转化就是上面说的根据backend进行定制的。
DispatchKeySet
Dispatch key set就是一个uint64,包含了上面说的从dispatch key到64bit的编码逻辑。以及按照优先级获取dispatch key的逻辑。
bit: 63 ............................. 16 | 15 .......... 1 | 0
[ functionality bits (高位) ] | [ backend bits ] |
Dense/Sparse/Autograd/... CPU/CUDA/...
高频使用的接口包括:
- operator|,用来合并多个dispatch key set。
- ezyang的blog中有提到,dispatch key的计算逻辑是输入的tensor的dispatch key set做并集,然后加上local include/exclude,再取high priority
- highestPriorityTypeId,构造出最高优先级的dispatch key
- 这里会先把最高优先级的functionality key查出来。通过count leading zeros来做
-
然后判断如果是per backend functionality key的话,会把highestBackendKey也取出来拼成runtime dispatch key
-
否则functionality key就是runtime dispatch key了
-
查dispatch key是一个比较高频的操作,这里还单独做了一下优化:
- getDispatchTableIndexForDispatchKeySet,直接计算出dispatch table的index,而不是转成dispatch key enum再去查了。
-
这里计算index是一个预计算好的table,也就是说不需要上面的highestBackendKey等if else了,直接查表。
TensorImpl
Dispatch key set就放在tensor impl中
at::Tensor是一个intrusive_ptr
这里注释中写到在facebook的系统中,会有400M live tensor。所以每增加1个uint64会增加 3.2G的内存。所以这里的实现对内存的要求是非常高的。
| 字段 | 作用 |
|---|---|
Storage storage_ |
指向真正的数据缓冲区(StorageImpl),多个 tensor 可共享同一 storage(view 的基础) |
autograd_meta_ |
autograd 元数据(grad、grad_fn 等)。不需要梯度时为 nullptr,省一个对象 |
extra_meta_ |
额外元数据,懒分配(symbolic shape、named tensor、fake tensor 等都塞这里) |
version_counter_ |
版本计数,原地操作时自增,autograd 用它检测"保存的张量被修改" |
pyobj_slot_ |
指向对应的 Python 对象(dispatch 到 Python 的桥梁,下面详述) |
sizes_and_strides_ |
sizes 和 strides,内联预留 5 维,避免堆分配 |
storage_offset_, numel_ |
偏移和元素总数 |
data_type_ |
dtype(TypeMeta,仅 2 字节) |
device_opt_ |
设备(仅 3 字节) |
key_set_ |
dispatch 的核心,就是DispatchKeySet |
有一些关键的函数在这里:
- is_python_dispatch,会判断dispatch key中是否包含Python key
- 比如FakeTensor,或者一些wrapped tensor,他的key set中会被加上Python key。
-
在dispatch的时候,如果有Python key,就会从上面记录的pyobj_slot_中找到对应的Python对象
-
然后调用到Python的__torch_dispatch__
Dispatch机制实现
核心机制的示意图,然后跟着这里的链路来看代码
TORCH_LIBRARY(...) / TORCH_LIBRARY_IMPL(...)
│
▼ registerDef / registerImpl / registerFallback
Dispatcher (singleton, list<OperatorDef>)
│
▼ 每个算子
OperatorEntry
├─ kernels_ : flat_hash_map<DispatchKey, list<AnnotatedKernel>> 注册原始数据
├─ dispatchTable_: array<KernelFunction, num_runtime_entries> 编译后的密集表
└─ dispatchKeyExtractor_ schema 信息
调用时:
TypedOperatorHandle::call(args...)
└─> Dispatcher::call
├─> DispatchKeyExtractor::getDispatchKeySetUnboxed(args)
│ └─> tensor.key_set() OR ... -> | TLS.included -> & nonFallthroughKeys
├─> OperatorEntry::lookup(keyset)
│ └─> dispatchTable_[keyset.getDispatchTableIndex()]
└─> KernelFunction::call(op, keyset, args...)
↓ 进入具体 kernel
kernel 内部可调 redispatch(keyset.remove(自己的 key), args...)
调用链路
先看调用链路,以Add举例子
```C++
用户写 at::add(a, b)
↓ 转发
at::_ops::add_Tensor::call(a, b) ← 这一层是 codegen 生成
↓
TypedOperatorHandle::call(a, b) ← 你问的这一层
↓
Dispatcher::call(*this, a, b)
↓
DispatchKeyExtractor → OperatorEntry::lookup → KernelFunction::call
<pre><code class="line-numbers">用户层的aten::add会调用到codegen生成的add\_Tensor:call()
然后调用到TypedOperatorHandle::call,就到了dispatcher这一层
<br>
一个小细节,这里的关联路径的函数都会尽量做inline,C10\_ALWAYS\_INLINE\_UNLESS\_MOBILE,但是在mobile上不会做。因为mobile上代码占据的空间也是需要考虑的。
<br>
### DispatchKeyExtractor
Dispatch key extractor的作用就是从算子的args中获取dispatch key,同时合并tls的dispatch key set,生成最终使用的dispatch key set。
是每一个operator对应一个dispatch key extractor
核心要处理的是3个事情:
- 根据算子的schema提取出那些位置是包含dispatch key的。
- 不同的算子schema不同,所以dispatch key extractor是per operator的
- 会记录在dispatch\_arg\_indices\_reverse\_中
- Fall through,算子可能给某些key注册fallthrough kernel,表示的是这个算子不做任何事,请直接走到下一层。
- 比如Autograd中无grad的操作。
- Fall through的作用就是为了避免调用到无用的算子再去redispatch。所以这里会直接跳到真正干活的那一层。
- 接口是setOperatorHasFallthroughForKey,机制就是维护一个mask,在计算dispatch key set的时候,会把这些fall through的key mask掉。这样就不会选到这些dispatch key,也就走不到对应的kernel了
- 计算dispatch key,这里会处理Boxed/Unboxed
- getDispatchKeySetUnboxed
- 在编译期展开args,对于tensor等包含key\_set()的对象,or到一起。对于其他类型则是空操作,会被编译器优化掉
- getDispatchKeySetBoxed
- 根据注册的schema从栈中把参数pop出来,也是把key\_set() or到一起。
- 两者计算了参数的key set之后,都会调用到:computeDispatchKeySet
- 这里会获取local dispatch key set。
- ((key\_set | local.included\_) - local.excluded\_) & mask,得到最终的dispatch key set
- mask就是fall through kernel,不选
## Kernel注册
算子注册的入口在torch/library.h中
主要是两个宏:
```C++
TORCH_LIBRARY(mylib, m) {
m.def("scaled_add(Tensor a, Tensor b, float s) -> Tensor");
}
m.def()用于定义算子的schema
mylib对应算子的namespace,调用的时候对应mylib::scaled_add
比如平常使用的aten的算子,namespace就是aten
```C++
TORCH_LIBRARY_IMPL(mylib, CPU, m) {
m.impl("scaled_add", &scaled_add_cpu);
}
TORCH_LIBRARY_IMPL(mylib, CUDA, m) {
m.impl("scaled_add", &scaled_add_cuda);
}
m.impl用于注册算子的实现
第二个参数CPU/CUDA对应dispatch key
<br>
TORCH\_LIBRARY宏最终会调用到`c10::Dispatcher::singleton().registerLibrary`,注册对应的namespace
里面的m.def(),会调用到`c10::Dispatcher::singleton().registerDef`,注册算子对应的schema
m.impl则会调用到`c10::Dispatcher::singleton().registerImpl`,对应注册算子的实现。
- 注意这里m.impl没有传入dispatch key,这个是宏帮忙做了,他会把dispatch key传给m(是一个Library对象),然后再调m.impl
细节流程图:
```C++
TORCH_LIBRARY_IMPL(myops, CUDA, m)
│ k = CUDA (枚举成员名, 裸标识符)
▼
_TORCH_LIBRARY_IMPL: c10::DispatchKey::k → c10::DispatchKey::CUDA
│ std::make_optional(...) 作为第4个参数
▼
TorchLibraryInit(..., k, ...) → lib_(kind, ns, k, ...)
▼
Library 构造: 存入成员 dispatch_key_ (CatchAll 归一为空)
▼
m.impl("add", fn) → Library::_impl
│ dispatch_key = f 级 key (若有) 否则 块级 dispatch_key_
▼
Dispatcher::registerImpl(name, dispatch_key, kernel)
▼
OperatorEntry::registerKernel() // kernel 挂到该 dispatch key
</code></pre>
<br>
这里的m上,除了def/impl,还有一个fallback的功能,作用是给dispatch key注册fallback kernel:
```C++
TORCH_LIBRARY_IMPL(_, AutogradPrivateUse1, m) {
m.fallback(torch::CppFunction::makeFallthrough());
}
- 注意第一个参数是 `_`——这是个特殊 namespace 占位符,表示"我注册的不是某个特定 namespace 的算子,而是给整个 dispatch key 注册一个通用 fallback"。`m.fallback(...)` 不带算子名。
- 针对dispatch key做的,所以没有算子名,也没有namespace的名字
- 对应dispatcher这一层,就是调用到`registerFallback`
<br>
语义对照表:
| 项目 | `registerDef` | `registerImpl` | `registerFallback` |
| --- | --- | --- | --- |
| 回答的问题 | 这个算子长什么样? | 在某个 backend 上怎么算这个算子? | 当某个 backend 没有专门 kernel 时,默认怎么处理所有算子? |
| 用户宏 | `TORCH_LIBRARY` 里的 `m.def(...)` | `TORCH_LIBRARY_IMPL` 里的 `m.impl(...)` | `TORCH_LIBRARY_IMPL` 里的 `m.fallback(...)` |
| 作用范围 | 单个算子 | 单个算子 × 单个 dispatch key | 单个 dispatch key × 所有算子 |
| 写到哪里 | `OperatorEntry::schema_` | `OperatorEntry::kernels_[key]` | `Dispatcher::backendFallbackKernels_[idx]` |
| 一次注册影响 | 1 个 OperatorEntry | 1 个 OperatorEntry 的若干 dispatchTable entry | 所有 OperatorEntry 的对应 entry |
| 重复注册 | 一般禁止(同名 schema 多次会出错) | 允许(warning,新覆盖旧) | 一般禁止(除 `AutogradPrivateUse1` 例外) |
整体的注册/调用的交互逻辑:
```C++
┌─────────────────────────────────────┐
│ Dispatcher │
│ │
m.def(schema) ──> │ registerDef │ ────> Listeners 通知
│ └─> OperatorEntry::registerSchema │
│ │
m.impl(name,k) ──> │ registerImpl │
│ └─> OperatorEntry::registerKernel │
│ └─> kernels_[key] + │
│ updateDispatchTable_(key) │
│ │
m.fallback(f) ──> │ registerFallback │ ────> 遍历所有 OperatorEntry
│ └─> backendFallbackKernels_[idx] + │ updateFallback
│ updateDispatchTable_ │
└─────────────────────────────────────┘
每次 op 调用:
─────────────────
Dispatcher::call
├─ 提取 keyset
├─ OperatorEntry::lookup(keyset) ─> dispatchTable_[idx]
│ 这一格是 [Note] DispatchTable computation 的解析结果:
│ (1) kernels_[key] ← registerImpl 注册的
│ (2) kernels_[alias key] ← registerImpl(Composite*, Autograd) 注册的
│ (3) backendFallbackKernels_ ← registerFallback 注册的
│ (4) missingKernel ← reportError
└─ KernelFunction::call(...)
OperatorEntry
上面的注册,以及调用相关的逻辑最后都会到OperatorEntry中,来看一下这个结构
它的单一职责:持有一个算子的所有运行时状态——schema、所有 backend 的 kernel 注册、编译好的 dispatch table、签名校验、Python op handle 缓存——并提供原子的 lookup 和 register/deregister 接口。
- registerSchema
- 首次Dispatcher::registerDef的时候,会创建算子对应的OperatorEntry
-
校验每个注册的kernel的schema
-
dispatchKeyExtractor_.registerSchema,解析schema,记录tensor的位置,方便运行时获取dispatch key
-
registerKernel
- 校验schema
-
对于不传dispatch key的case,对应catch-all,也就是这个kernel对所有dispatch key都生效。内部会被转化成CompositeImplicitAutograd
-
将kernel注册到对应的dispatchkey上,是一个哈希表
-
updateDispatchTable_/updateDispatchTableFull_,维护dispatch table,等下细看一下
-
updateFallback
- 和上层Dispatcher配合的,registerFallback的时候会把kernel更新到backendFallbackKernels_中对应的dispatch key的位置
-
然后调用所有的operator,都调用updateFallback,对应调用到updateDispatchTable_,算子会更新自己的dispatch table,把fallback kernel放进去。
UpdateDispatchTable
分几种情况:
- undefined
- 不太确定是什么时候传过来,catch all应该是对应CompositeImplicitAutograd
-
直接调用updateDispatchTableEntry_,对应的dispatch key就是undefined
-
Dispatch key是alias key
- 不是runtime dispatch key,也就是说不在dispatch table中有位置。而是对应若干个runtime key
-
比如Autograd,会对应各种backend,AutogradCPU, AutogradCUDA等
-
getRuntimeDispatchKeySet,把对应的runtime key取出来,调用updateDispatchTableEntry_,表示更新这些runtime key对应的dispatchtable entry
-
Dispatch key是Composite alias
- 比如CompositeImplicitAutograd/CompositeExplicitAutograd
-
也是调用updateDispatchTableEntry_,dispatch key是undefined
-
Dispatch key是backend key
- 比如CPU,CUDA
-
此时会针对AutogradCPU做一次更新
UpdateDispatchTableEntry
-
getDispatchTableIndexForDispatchKey,根据dispatch key,算出dispatch table中的位置
-
computeDispatchTableEntry,根据当前的注册情况,计算对应位置需要使用的kernel
- 这里会根据operatorEntry,以及dispatcher中注册的全局的fallback kernel,来计算一下对应dispatch key要使用的kernel
-
有一个简单的模型是看ezyang的博客这里的图:
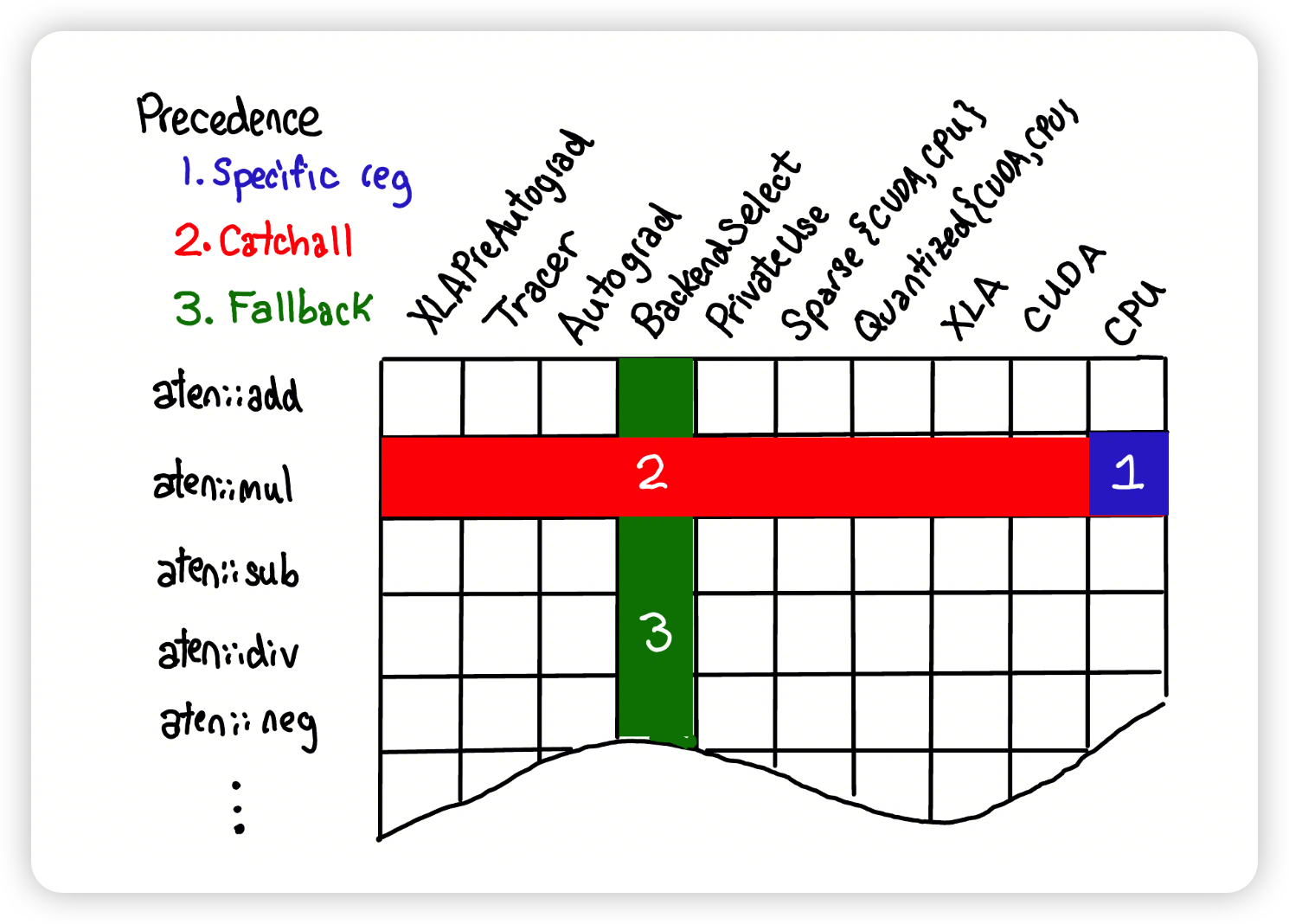
- 最高优先级,如果有直接针对这个dispatch key做的注册,就用这个
-
Alias key,这里看当前key是不是被某些alias key覆盖了,这里对应上面的红色线。也就是catch all进来的CompositeImplicitAutograd逻辑,会覆盖这个算子下的各种runtime key。
- CompositeExplicitAutogradNonFunctional
- 我也没看懂,是下面的CompositeExplicitAutograd去掉了某些特殊的backend,XLA等
- CompositeExplicitAutograd
- 表示这个kernel覆盖所有的backend,但是autograd需要单独注册
- CompositeImplicitAutograd
- (俗称 "math kernel") 是最强的 alias,覆盖几乎所有 runtime key。它的含义:op 作者用其它 op 组合实现,因此autograd 自动可得(autograd 会沿着子 op 走)
- Autograd
-
FuncTorchBatchedDecomposition
-
Fall through kernel,对应上面的绿色条
-
如果还是没有,则会写一个MissingKernel()在里面,放到dispatch table中。运行时遇到就会报错
-
note,这块逻辑比较复杂,而且我也没有用到这种比较详细的算子dispatch的逻辑,所以这里看的糊一些。大概有一个概念即可,后面如果有注册算子相关的问题可以再回来研究这里
-
然后注意上面的分支2,对undefined dispatch key也生效。也就是说比如输入是没有tensor的时候,对应的dispatch key就是undefined,此时就可能走到上面的alias中。
-
dispatchKeyExtractor_.setOperatorHasFallthroughForKey
- 更新dispatch key extractor,记录对应dispatch key的位置是不是fall through,方便dispatch key extractor跳过。(通过mask)
Lookup
逻辑则简单很多,就是根据上面计算出来的dispatch table来查表。输入的是dispatch key set,getDispatchTableIndexForDispatchKeySet得到dispatch table的idx,然后找到对应的kernel返回
kernel的调用里还会处理一下是否包含symint的参数,这个就等到inductor阶段再来看了。
最终就是operatorEntry中的函数指针调用

文章评论