文章:https://zhuanlan.zhihu.com/p/673903240
通信的实现方式分为两种类型:机器内通信与机器间通信。
机器内通信:
* 共享内存(QPI/UPI),比如:CPU与CPU之间的通信可以通过共享内存。
* PCIe,通常是CPU与GPU之间的通信。
* NVLink,通常是GPU与GPU之间的通信,也可以用于CPU与GPU之间的通信。
机器间通信:
* TCP/IP 网络协议。
* RDMA (Remote Direct Memory Access) 网络协议。
* InfiniBand
* iWARP
* RoCE
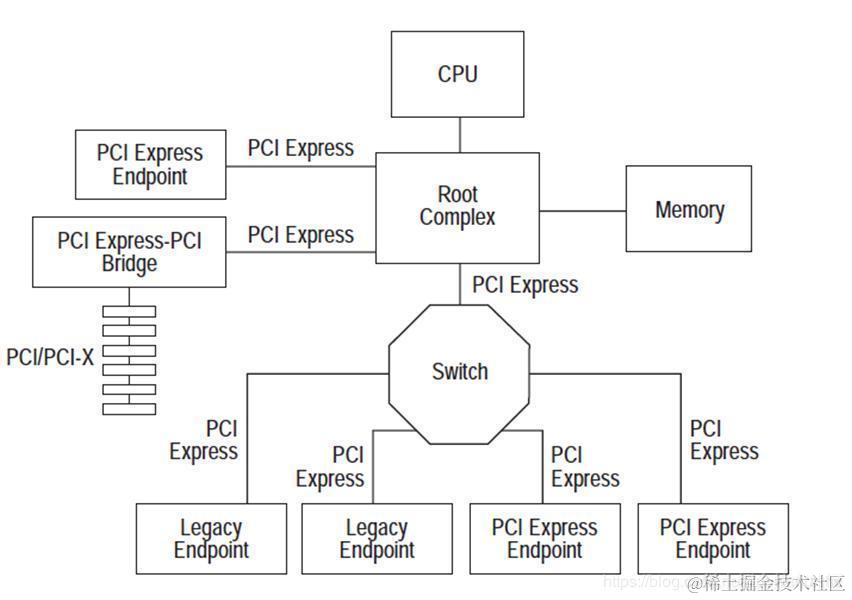
PCIE
PCI-Express(peripheral component interconnect express),简称PCIe,是一种高速串行计算机扩展总线标准,主要用于扩充计算机系统总线数据吞吐量以及提高设备通信速度。
* 比如GPU/CPU的通信,SSD/CPU的通信,就是走的PCIe
拓扑结构如下,这里的PCIE endpoint就是接入的各种设备(主板上看的那些插槽)
NVLink
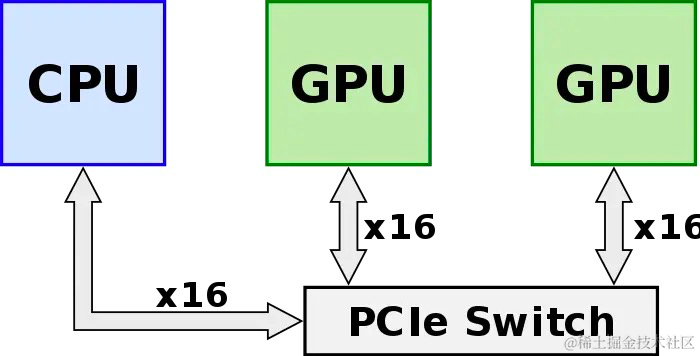
最开始,GPU/GPU的通信需要经过CPU,限制吞吐。
后续NVIDIA开发了GPUDirect P2P,使GPU可以通过PCIE直接访问目标GPU的显存,避免经过CPU(host memory)。
但是这种方法还是受到了PCIe的限制,无法做到更高的带宽,所以有了NVLink

NVLink高速互联主要有两种:
* 第一种是以桥接器的形式实现。
* 另一种是在主板上集成 NVLink 接口。
我这里就有两块NVLink,只能是两个GPU点对点的相连。
(主板上的NVLink接口不太确定是怎么连的,可能也是点对点。)
NVSwitch
因为NVLink只有点对点的互联,当GPU数量多的时候,拓扑会比较复杂。
所以引入NVSwitch,把多块GPU通过NVLink做成全互联的形式。
差不多是这样:
GPU ⇄ NVLink ⇄ NVSwitch ⇄ NVLink ⇄ GPU
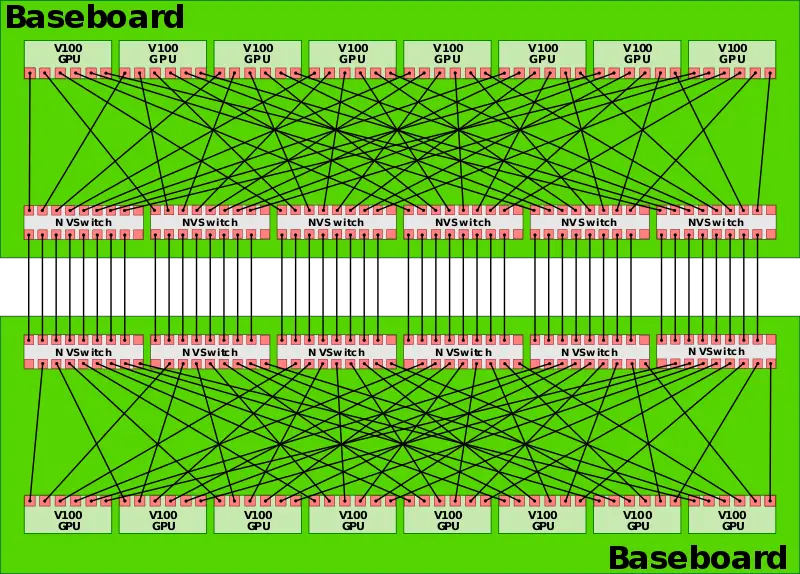
这里有一个跨机的示意图16块卡
GPU P2P通信这块,在Demystifying NCCL这篇paper中有更详细的记载
然后是跨机通信的部分:
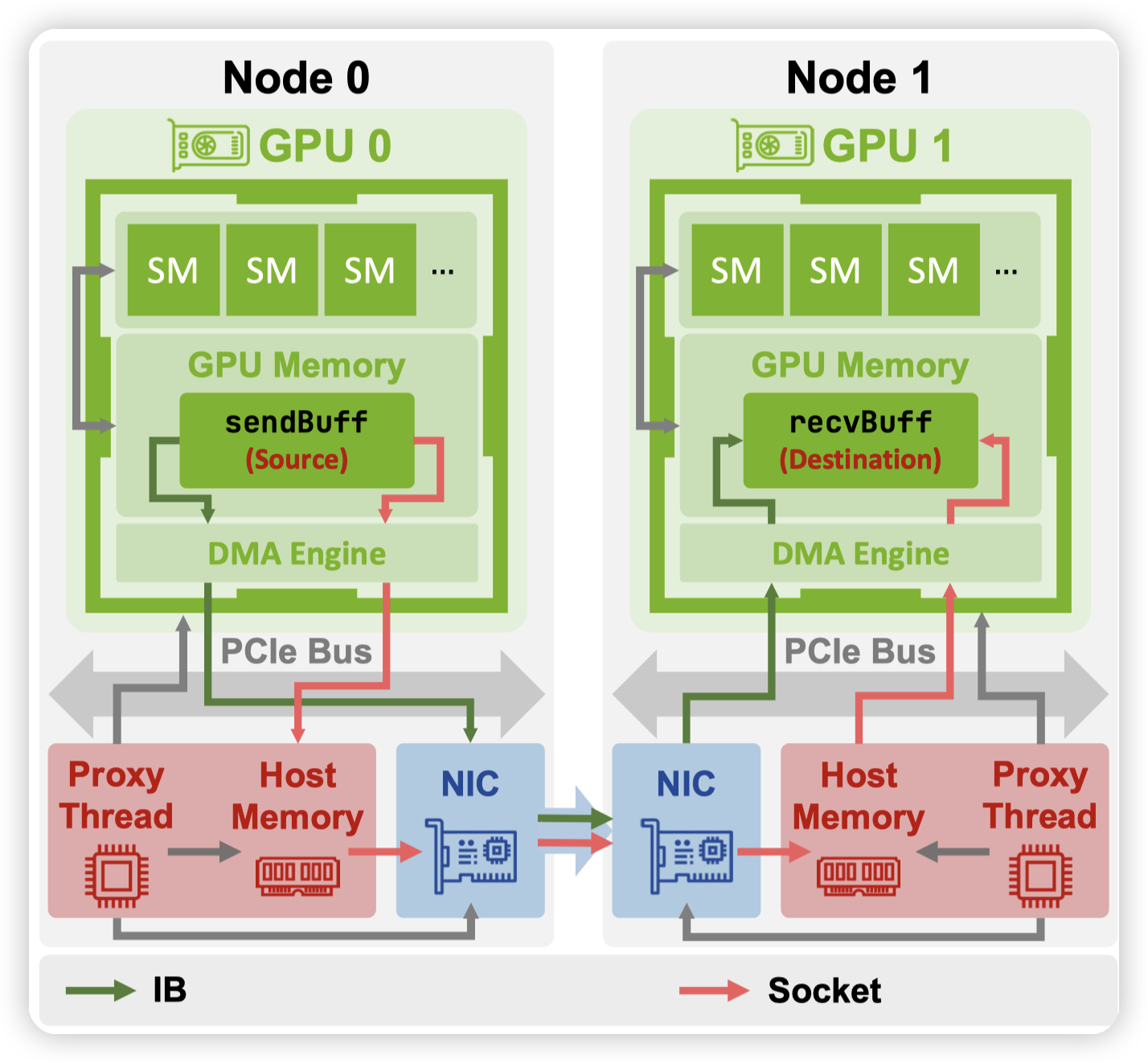
走TCP/IP的对应的就是这里的socket,GPU拷贝到host memory,然后拷贝到NIC上,再走TCP发送到对端。
RDMA
RDMA(远程直接数据存取)就是为了解决网络传输中服务器端数据处理的延迟而产生的。
对比传统的网络传输机制,RDMA无需操作系统和TCP/IP协议栈的介入。RDMA的内核旁路机制,允许应用与网卡之间的直接数据读写。
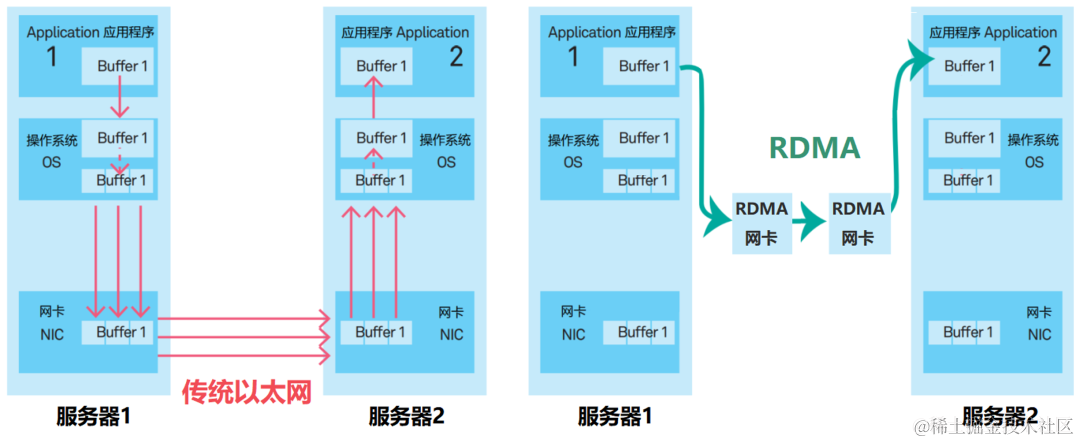
有几类的RDMA,分别是Infiniband, RoCE, iWARP。
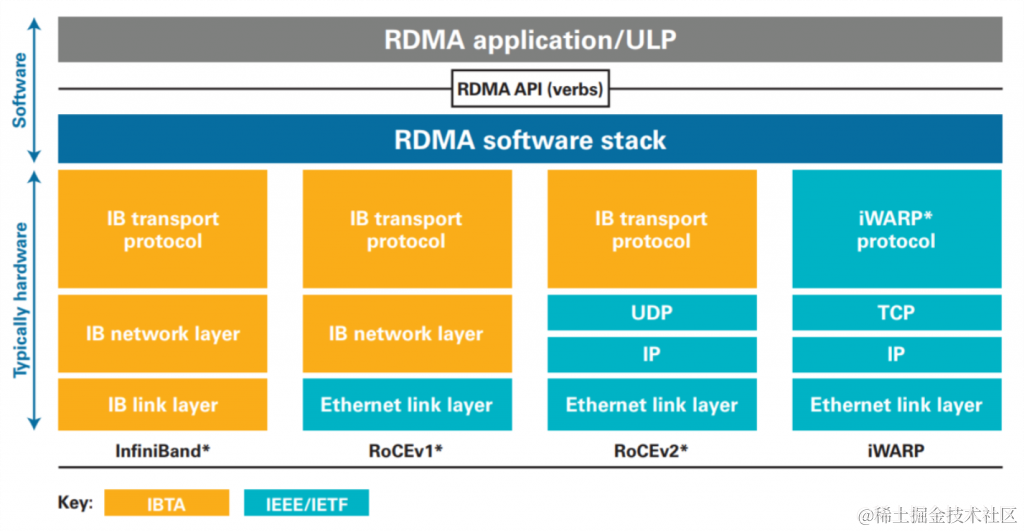
* IB(InfiniBand): 基于 InfiniBand 架构的 RDMA 技术,由 IBTA(InfiniBand Trade Association)提出。搭建基于 IB 技术的 RDMA 网络需要专用的 IB 网卡和 IB 交换机。
* iWARP(Internet Wide Area RDMA Protocal): 基于 TCP/IP 协议的 RDMA 技术,由 IETF 标 准定义。iWARP 支持在标准以太网基础设施上使用 RDMA 技术,但服务器需要使用支持iWARP 的网卡。
* RoCE(RDMA over Converged Ethernet): 基于以太网的 RDMA 技术,也是由 IBTA 提出。RoCE 支持在标准以太网基础设施上使用RDMA技术,但是需要交换机支持无损以太网传输,需要服务器使用 RoCE 网卡。
简单想就是对硬件需求的不同。协议栈的实现会有一些区别,对上层的区别应该就是性能/稳定性,以及成本了。使用上都是verbs,RDMA的api
文章后面讲了很多IB的细节设计,这里感觉我碰的不多,就不提了。
RDMA的api对上层的一个关键抽象就是queue pair:
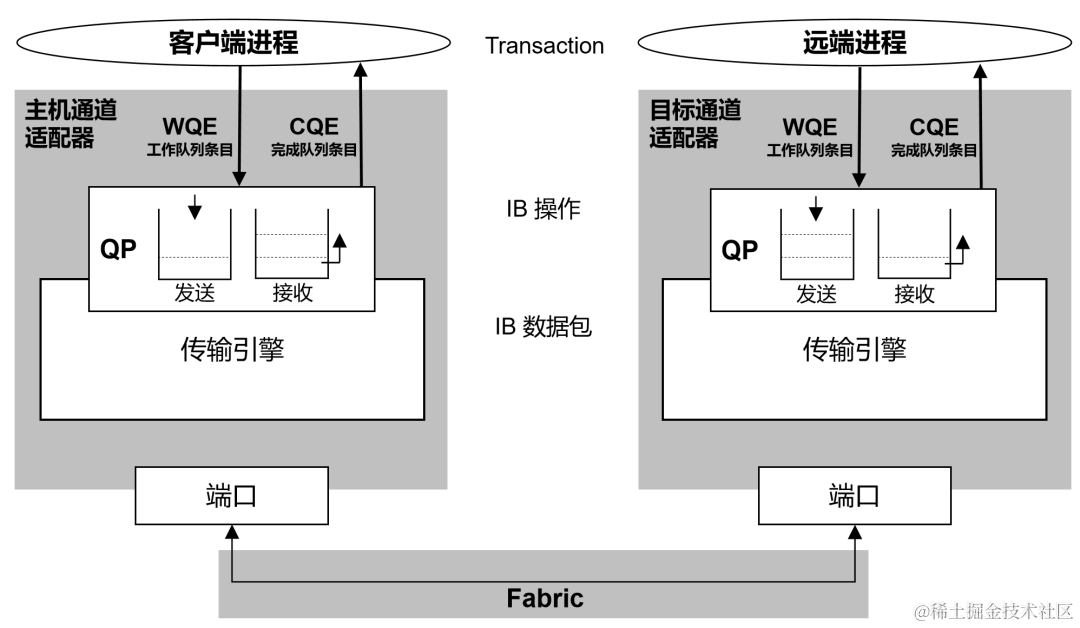
这个queue pair可以看作是两个机器的通信通道。
* 发送方生成要写的数据,放到WQ中(应该是work queue,因为一次请求对应work request)
* RDMA负责把数据传到对端,并通过DMA,从NIC直接修改内存
RDMA中所谓的polling,就是需要去polling这里的内存,或者是通过特殊的写操作,去polling CQ。在接受到数据的时候可以进行相应。
这里的CQ就是completion queue,部分请求完成后,就会在这里写一条数据,进行通知。
对于上层软件层的话,差不多有这个模型就行,因为NCCL等库已经屏蔽了RDMA这些细节了。
然后文章后面讲了一下通信原语,感觉也是看Demystifying NCCL就行
GPUDirect
这里最后还整理了一下GPUDirect相关的
- GPUDirect Shared Memory (2012) : Nvidia在PCIe上实现了单机上的GPUDirect Shared Memory 技术;
- GPUDirect P2P (2014): Nvidia在PCIe上实现了单机上的GPUDirect P2P技术;
- GPUDirect RDMA(2014):提升多机多卡通信性能;
主要看GPUDirect RDMA。在Demystifying NCCL中亦有记载。
简单说就是,两个GPU通信的时候,即便是走RDMA,也是拷贝到内存中,然后再走PCIe从内存拷贝到显存中。
GPUDirect RDMA则是让NIC可以直接把数据写到显存,从而跳过host memory。
* 这篇文章说要求设备共享上游的PCI Express root complex。
* Demystifying NCCL中说是共享PCIe Switch
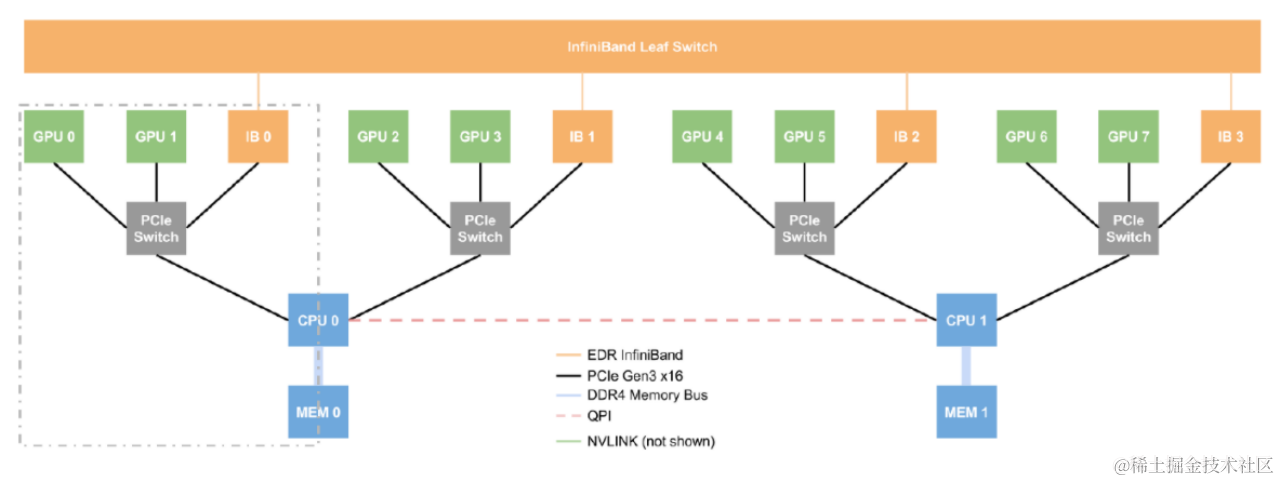
这里有一张拓扑结构来整理一下上面提到的东西。
因为单个IB无法承载所有的GPU的流量,所以这里做了拆分,两个GPU对应一个IB
* 也可能是PCIe switch不够一下挂8个卡,因为这里需要用GPUDirect RDMA
跨机通信就可以通过GPU -> IB -> IB switch来进行。
这里两个CPU对应的是两个socket,中间通过QPI连接。速度相对较慢。所以文章中也提到了通过IB连接CPU,让跨socet的通信走IB,而不是QPI。
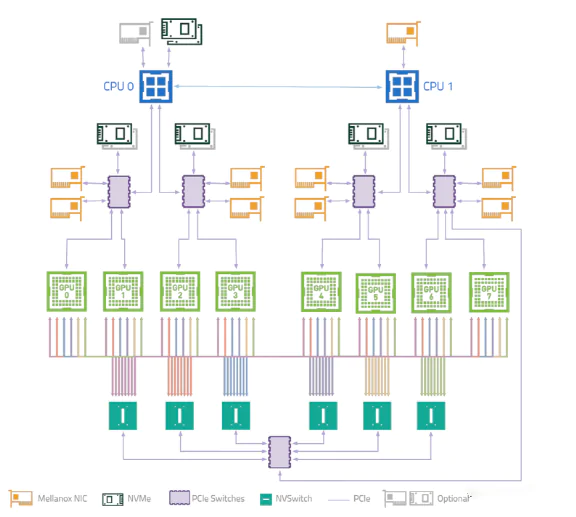
这个图(有点糊)还带了NVSwitch,展示了机内通信和跨机通信。
机器内通信可以都走NVSwitch
机器间通信则还是GPUDirect RDMA,通过同switch下的IB进行通信,然后IB再去走IB的交换机。
GPUDirect RDMA这个技术配合上这个拓扑,也带来了一些复杂度,因为NCCL这些库里做点对点通信的时候,就需要考虑对应的QP,准确的发送到对应GPU的IB上。

文章评论