Retrieval-Augmented Generation with Hierarchical Knowledge
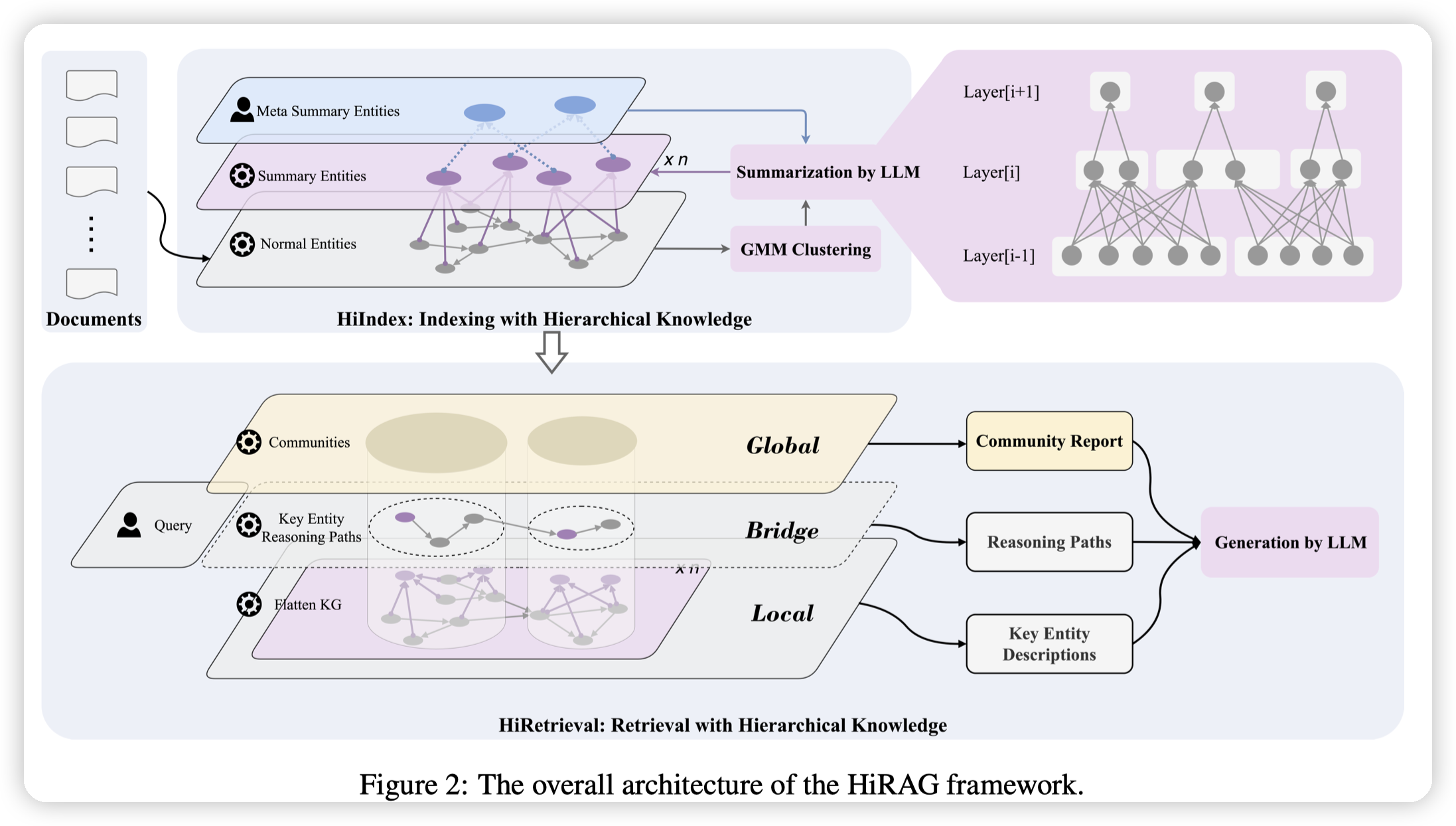
* 基本思路是通过GMM对实体做聚类,在构图的时候额外增加了若干层的summarize的节点。
* 这里和社区总结是正交的,实现中这两个技术都会使用。
* 聚类出来的总结节点主要是为了连接语意相似,但是没有直接关系的点。
* 个人感觉,这个可能可以替换社区总结。把这种实体的summary扩充一些,然后global问答的时候针对这些实体做总结应该也是可以的
代码实现上是基于nano-graphrag的:
* 抽图的时候用了两阶段的抽图,先抽取实体,再抽取关系
* 然后跑聚类,得到每一层的新的簇。然后让输入给LLM生成新的高层的点边
* 如果某一个簇过大,会做随机选择,sample一些点来做总结
* 感觉是可以做多轮总结的,知识图谱应该还是精准度更优先一些
* 这里新的高层的点的类型也是单独定义的。在prompt中是叫META_ENTITY_TYPE
* 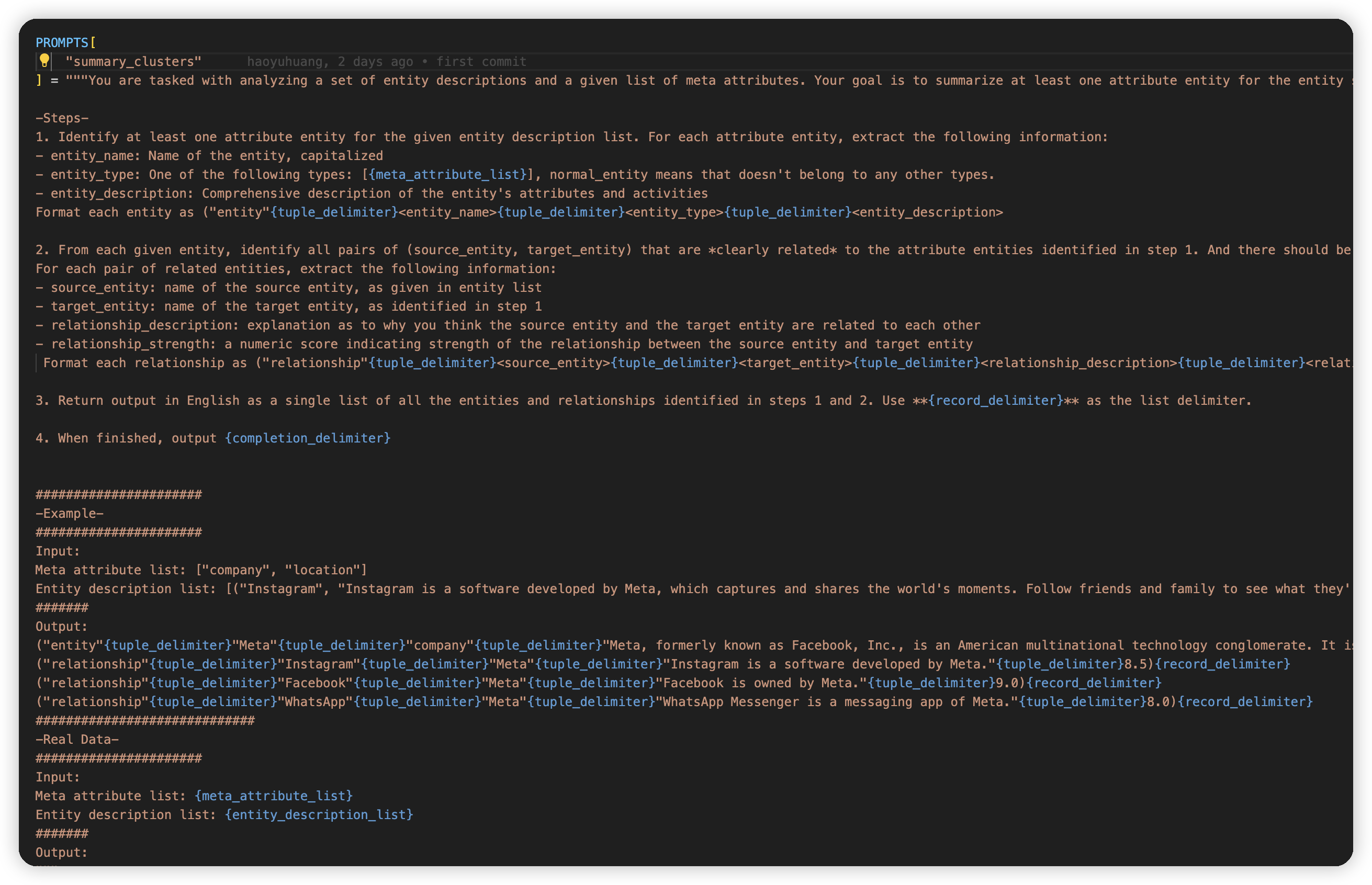
* 总结的prompt,这里的一个例子是把instangram/facebook等几个产品拿出来,然后总结了个新的实体是meta
* 其他的地方,社区总结什么的都是一样的
- 然后看看查询,既然有了高层的实体放到图上,主要的目的就是为了连接不同的底层实体。所以肯定是需要有一些路径相关的查询的
- _build_hierarchical_query_context 中
- 先用vdb查出来关联的实体
- 然后根据包含关联实体的数量,查询若干个community
- 然后会把每个community中和本次查询相关的实体拿出来
- 上述几个步骤得到的所有实体,会用nx.shotest_path查询关联实体之间的最短路
- 这里比较变态的是,他只会走一条路径,而不是给定节点之间的路径查一个子图。一条路径的问题在于,路径上节点先后顺序的选择就比较关键一些。

对应这里的逻辑
- 这里比较变态的是,他只会走一条路径,而不是给定节点之间的路径查一个子图。一条路径的问题在于,路径上节点先后顺序的选择就比较关键一些。
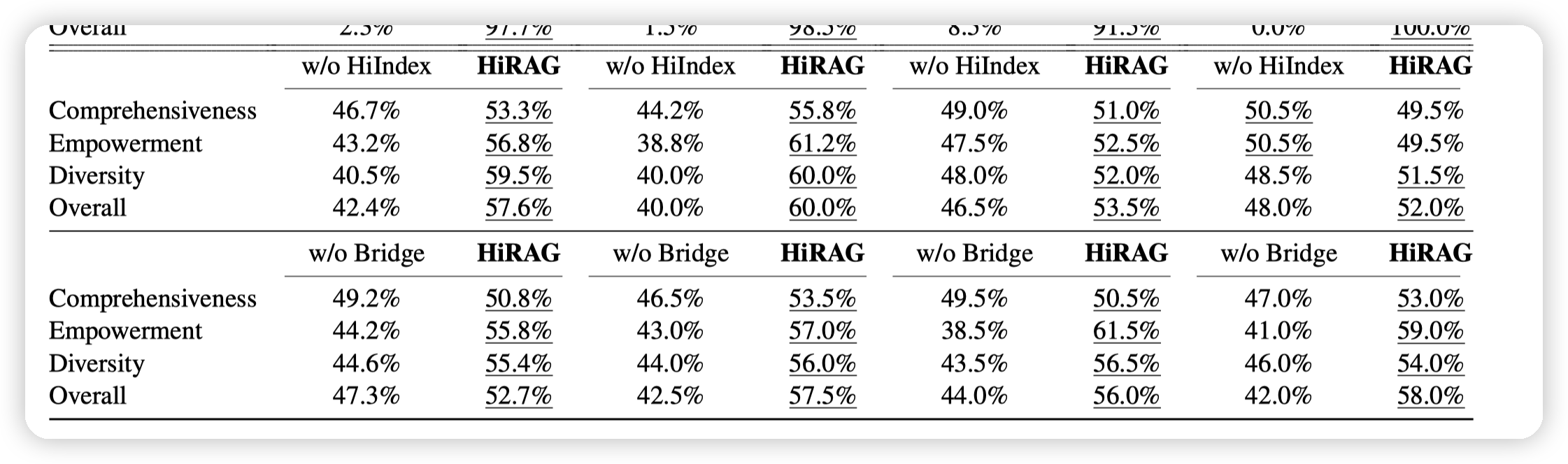
这里还有两种策略的消融实验:
* 从这里看,感觉Bridge这个策略更关键一些。隐含了说明,即便是在现有的graphrag系统中,也可以引入这套策略来做强化

文章评论