这篇论文介绍了一种名为HippoRAG的新型检索框架,旨在解决大语言模型(LLMs)在整合新知识时的效率问题。以下是文章的核心内容概述:
核心创新:受神经生物学启发的长期记忆机制
HippoRAG的灵感来源于人类大脑的海马索引理论。人脑通过海马区(负责关联索引)和新皮质(负责存储具体记忆)的协作实现高效记忆整合。HippoRAG模仿这一机制:
- 海马索引的模拟:构建一个开放式的知识图谱(KG),存储文本中的实体和关系。
- 新皮质的模拟:利用LLM解析文本并提取知识。
- 个性化PageRank(PPR)算法:模仿海马的模式补全功能,通过图搜索关联分散的知识片段。
技术亮点
- 离线索引:
- 使用LLM从文本中提取三元组(实体-关系-实体),构建知识图谱。
- 引入同义词边(通过检索编码器检测相似实体),增强图谱的关联性。
- 在线检索:
- 从查询中提取关键实体(如“Stanford教授”和“Alzheimer’s”)。
- 在知识图谱中运行PPR算法,从查询实体出发扩散概率,找到相关子图。
- 根据节点权重(类似逆文档频率)和关联路径,快速定位相关段落。
- 单步多跳检索:
- 传统RAG需多次检索迭代,而HippoRAG通过一次图搜索即可完成多跳推理,效率提升6-13倍,成本降低10-30倍。
代码
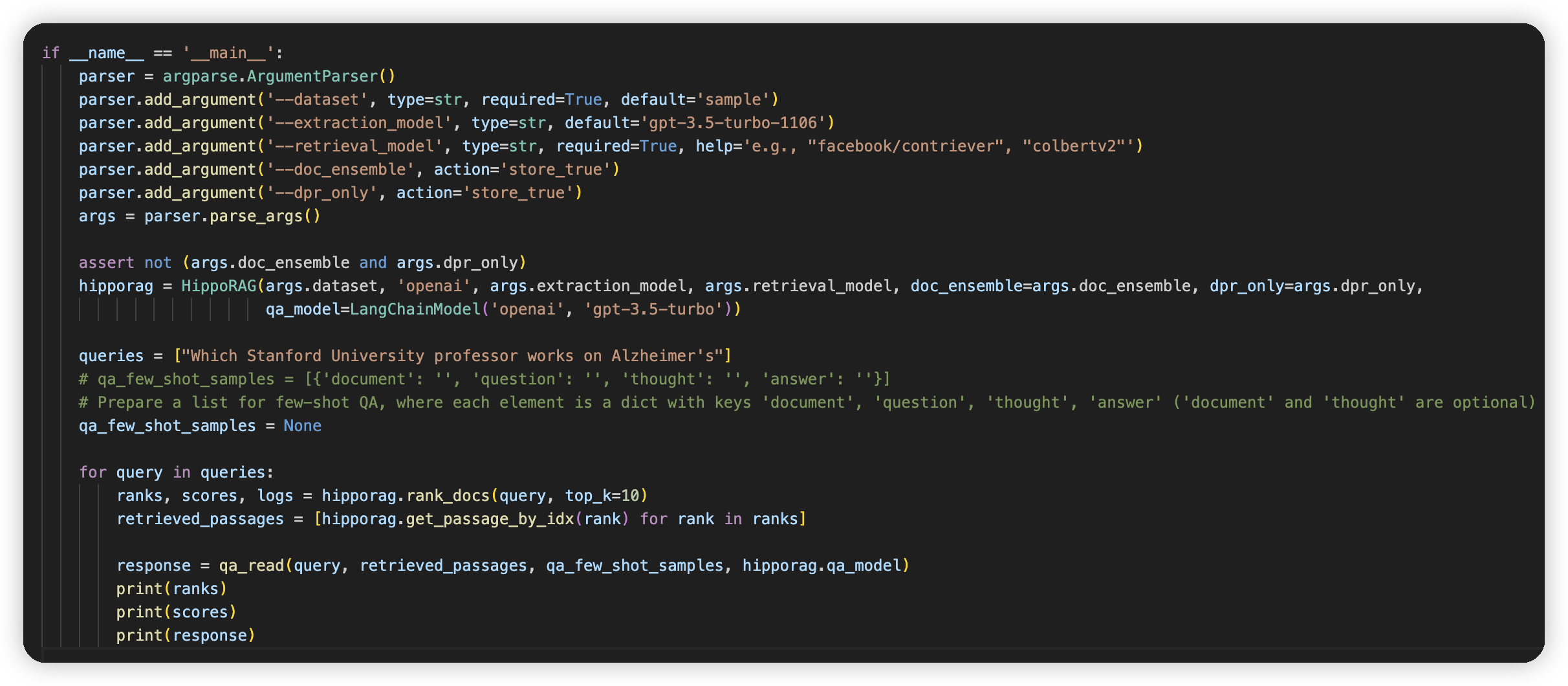
使用方式也比较简单,提供的是rank_docs做retrieval
Index
这里option的dpr指的是Dense Passage Retrieval,就是指代传统的向量检索方法
数据处理有两种,要么是用colbert做检索,要么是用hf上的retrieval encoder做,也就是常见的向量检索方法
以colbert这个为例子:setup_hipporag_colbert.sh
openie_with_retrieval_option_parallel.py
named_entity_extraction_parallel.py
来做实体提取
然后create_graph.py创建图
colbertv2_knn然后跑knn,接着又通过create_graph创建图了
最后调用colbertv2_indexing.py
- openie_with_retrieval_option_parallel
- 就是用大模型做实体提取
- 他会先做NER,也就是named entity recognition,提取出所有的实体
- 然后再通过实体和原始的文档,把KG抽取出来。得到三元组
- named_entity_extraction_parallel
- 只做实体提取
- 这里是针对数据集的query做提取,也就是关键词提取
- create_graph
- 读取三元组,创建图
- 这里会基于colbert做的knn,做一下近似边的连接。相当于做实体消重了

Query
这个方法是HippoRAG系统的核心排序算法,通过结合语义检索和知识图谱推理来实现文档排序。主要流程分为四个阶段:
实体提取与链接
query_ner_list = self.query_ner(query) # 命名实体识别
if使用ColBERTv2:
all_phrase_weights, linking_score_map = self.link_node_by_colbertv2()
else: # DPR
all_phrase_weights, linking_score_map = self.link_node_by_dpr()
使用LLM提取查询中的关键实体(如人物、地点等)
通过语义检索将实体链接到知识图谱节点,生成初始权重向量
图谱传播计算
if graph_alg 'ppr':
ppr_phrase_probs = self.run_pagerank_igraph_chunk()
elif graph_alg 'neighbor':
... # 邻居扩展算法
使用个性化PageRank算法在知识图谱上传播实体权重
通过三层矩阵转换(phrase->fact->doc)计算文档相关性概率
支持多种图算法(PPR/邻居扩展/路径查找)
多策略分数融合
if 实体置信度低:
doc_prob = 混合PPR分数和检索分数
else:
doc_prob = 纯PPR分数
动态权重调整:根据实体识别置信度决定融合比例
检索分数来自ColBERTv2/DPR的语义匹配结果
混合使用min-max归一化保证分数尺度一致
结果优化输出
sorted_doc_ids = np.argsort(doc_prob)[::-1] # 降序排列
logs收集:
- 实体识别结果
- 节点链接分数
- 图谱关系路径
- 文档包含的关键短语
最终返回top_k文档及其解释性日志
日志系统帮助分析排序决策过程
关键设计特点:
混合检索架构:
第一层:基于语义的密集检索(ColBERTv2/DPR)
第二层:基于知识图谱的推理增强
通过doc_ensemble参数控制混合比例
知识图谱的三层表示:
短语层(phrase)--关系--> 事实层(fact)--包含--> 文档层(doc)
使用稀疏矩阵存储层级关系(docs_to_facts_mat等)
矩阵乘法实现概率的高效传播
自适应权重机制:
node_specificity:根据短语文档频率反比例加权
weight = 1 / self.phrase_to_num_doc[phrase_id]
recognition_threshold:动态调整图谱权重占比
图算法扩展性:
支持PPR、多跳邻居、路径查找等算法
通过graph_alg参数切换不同传播策略
典型应用场景:
当查询包含明确实体(如"爱因斯坦的相对论")时,系统会:
识别"爱因斯坦"和"相对论"实体
在知识图谱中找到相关节点
沿图谱关系传播权重
找到同时包含这两个概念及其关联概念的文档
这种设计特别适合需要深层语义理解的复杂查询场景,相比传统检索方法能更好地捕获概念间的隐含关联。
IRCoT
他们还测试了IRCoT的方式
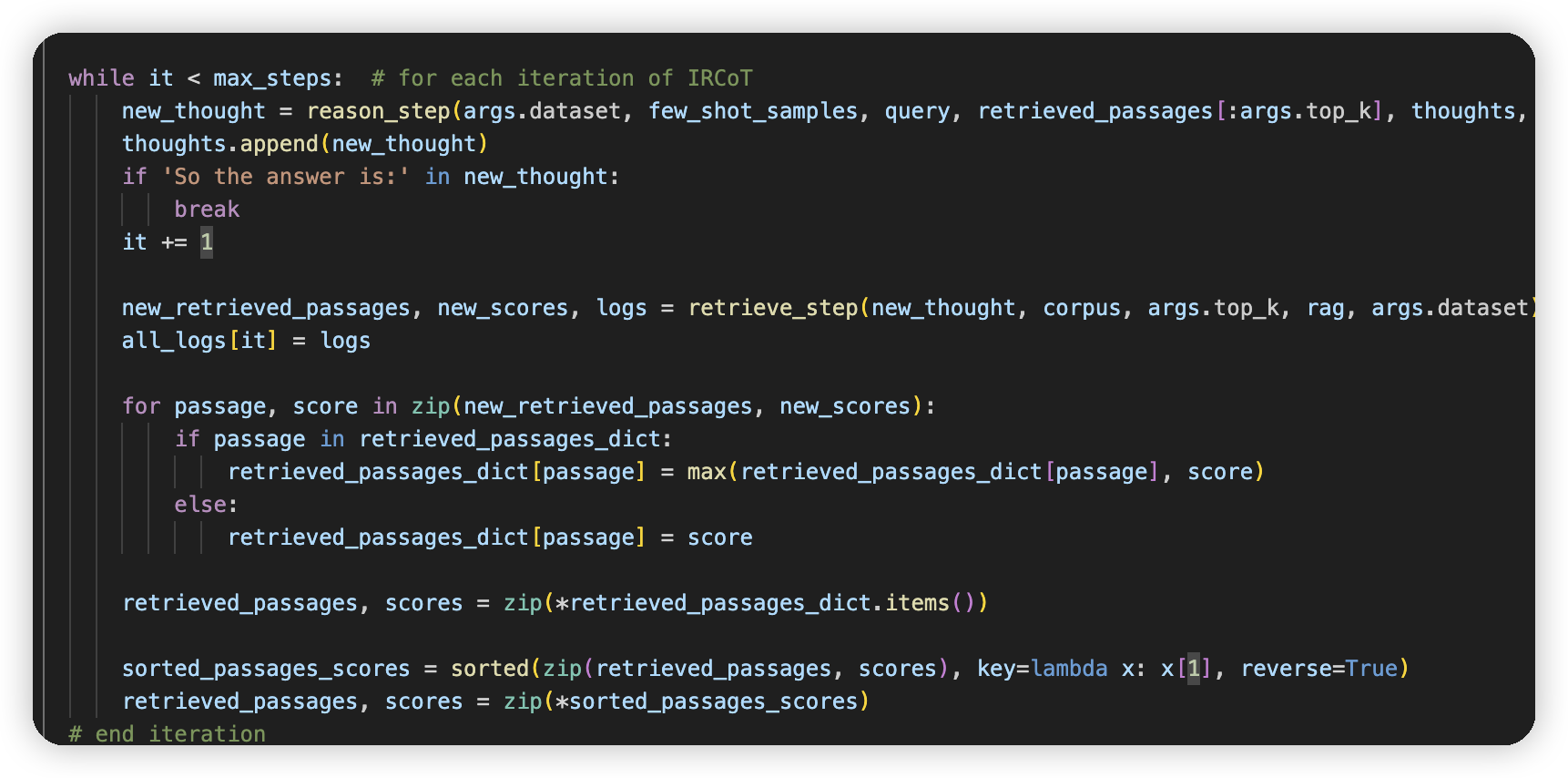
就是搞了多轮,之前是做一次rank_doc,这个就是每次retrieval完,会reason一下,拿到新问题

文章评论