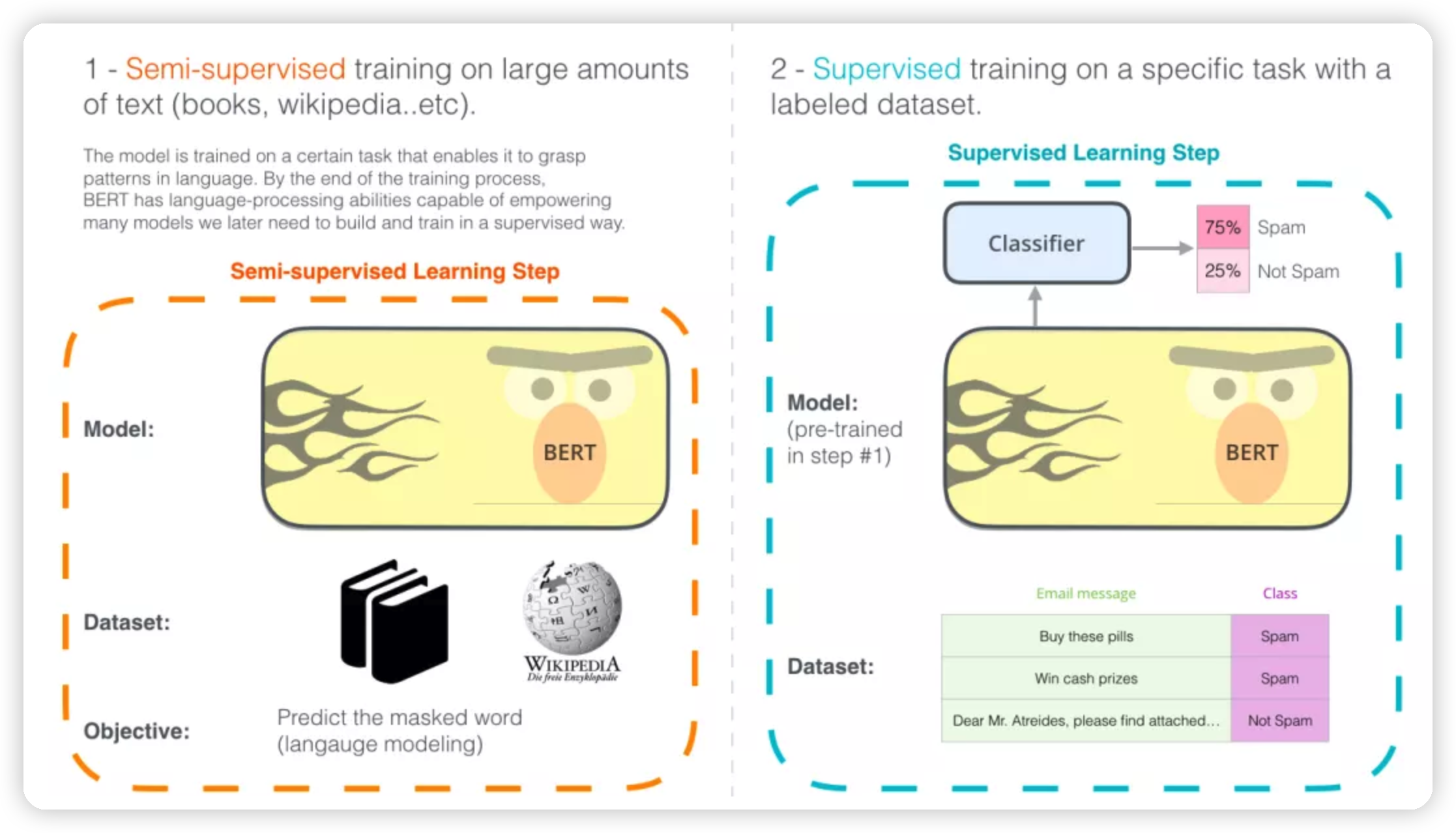
这里有一个很不错的图讲bert的用法的:
* 先通过完形填空的方式,用大量的语料做预训练。
* 然后针对特定的任务,做微调
Introduction
BERT:Bidirectional Encoder Representation from Transformer
用来预训练bidirectional representation,也就是说,bert输出的是每一个token对应的bidirectional representation,用来后续做其他任务。
这里有一个新的名词:pretrain的过程是通过jointly conditioning on both left and right context in all layers
也就是生成基于左边和右边的词的联合概率分布

bert的优势是:
can be finetuned with just one additional output layer, without substantial taskspecific architecture modifications.
* 关键在于不需要做task-specific architecture。感觉就距离通用的做法进了一步
这里还提到了两个概念:
* sentence-level task,比如natural language inference, paraphrasing。模型输出的是句子之间的关系。
* token-level task, 比如named entity recognition, question answering。模型输出是token-level


* sentence-level主要是接一个classifier就行
* 相比之下,token-level需要生成question-answer等,是需要一个一个token输出结果的,可能相对来说更加复杂一些
论文中提到,当时有两种方法吧预训练好的language representation(我不太确定这里是不是模型)应用到下游的任务中:
* feature-based
* fine-tuning
feature-based的意思就是把模型生成的输出作为一路新的feature,一起给下游使用:

* 这里ELMo就是一种,用预训练的模型生成上下文相关的embedding,然后和其他的feature拼接到一起,输入到下一层。
fine-tuning这里提到的就是OpenAI GPT:
* 其实也是现在大家常说的fine tune,模型中(我是根据LoRA来理解的)引入一些task-specific parameter,然后针对下游任务做训练,调整这些参数。
然后有一段针对GPT这种单向的生成模型的抨击:
The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training. For example, in OpenAI GPT, the authors use a left-to-right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (Vaswani et al., 2017). Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying finetuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions.
现在看起来,这里随便说的一句:
* token-level tasks such as question answering, where it is crucial to incorporate context from both directions
* 并不是非常有道理。这里也没有详细解释,为什么token-level task需要双向的输入
然后bert这里还提了一句他们做了"next sentence prediction",用来一起训练text-pair representation。目前还不知道是什么,后面文章中应该会提到。
Related Work
- unsupervised feature-based approaches
- 这里一个最基本的例子就是学习word embedding
- 后续word embedding被拓展了,有sentence embedding和paragraph embedding
- fine-tune的就是上面说的GPT这种
这里还提到了transfer learning:
* 在大量的数据集上训练的一些supervised task是可以做transfer learning的。说明语言结构什么的已经被学习了。
* 如果做过CV的应该知道,transfer learning用的很多,把卷积相关的不变,后面的输出层改一下,就可以用了
* transfer learning和pretrain的区别是,pretrain就是要学习通用的结构,并且(应该)一般是无监督的。比如用language model这种,或者是auto-encoder这种。而transfer learning则是确定好了任务,已经做过监督训练了,然后把部分层冻结,做的迁移。
BERT
- bert就是transformer的encoder
- 有bert base,是12层encoder
- 还有一个bert large,24层encoder,hidden feature size以及head都会多一些。做这个区分主要是用bert base和GPT去做对比
Input/output representations
上面说了bert会处理token-level/sentence-level的任务。
* sentence-level的任务需要输入多个句子,比如(question, answer),他们会把这个拼接起来作为一个句子输入给bert
WordPiece embedding(这里应该是两个,一个是tokenizer,另一个是token -> embedding的转化)
起始的第一个token总是一个特殊的[CLS]token:
The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.
* 用来代表总结性的信息

对于每一个token的生成,由三个部分组成,在图中有展示:
* 第一部分是原本的token embedding
* 第二部分是segment embedding,用来指示这个token属于第一个句子还是第二个句子
* 起始中间拼接的特殊的[SEP]在理论上已经可以学习到第一个句子和第二个句子的信息,但是这里还是加上了segment embedding,应该是为了让学习更容易一些
* 这个segment embedding论文中说是用的learned embedding。
* 
* 所谓learned embedding,就是在训练的时候一起训练的参数。并未是类似token embedding一样是预训练好的
* 第三部分和transformer相同,是position embedding
Pre-training BERT
文中首先提到,如果用传统的模型去训练双向的模型,会出现信息泄漏的问题:

* 所以bert的方法是做cloze task,就是完形填空:
* 对于每一个句子,他们会随机mask掉15%的token
* 然后在输出的位置,对于被mask掉的token,去让模型还原原始的token
这种完形填空有一个直观的问题,就是训练的时候有[MASK]这个token,但是在推理,或者是finetune的时候是没有的
* 这里的做法是,当一个token被选为mask的时候。80%的时间会被替换为mask,10%的时间替换为random的token。而10%的时间则不变。
另一个预训练的任务是用来让bert理解句子之间的关系:
* 
* 这里的C deepseek说错了,就是输入开头的[CLS]
可以看到两个训练任务,bert原文并没有说他们是怎么一起做训练的,这里问了下deepseek:
* 
* 
最后就是finetune了,这里给一个question answer的例子:
* 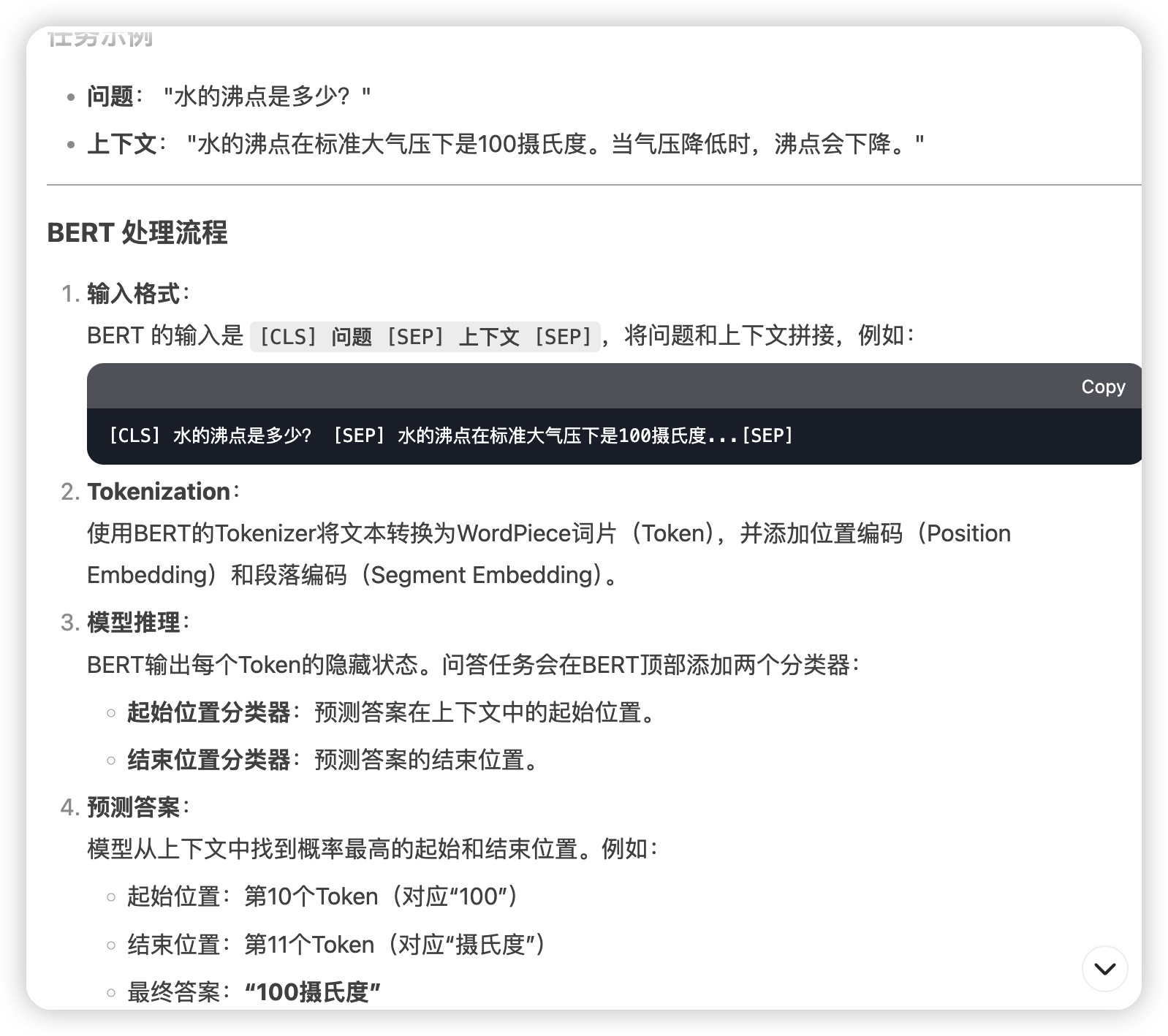
* 
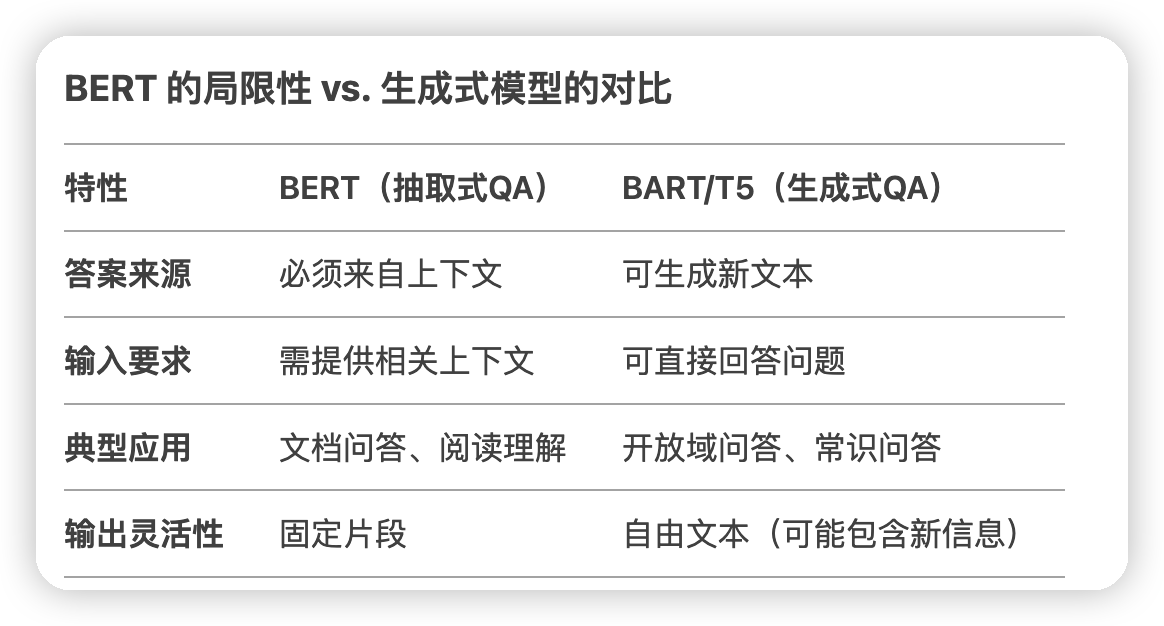
* 这里有一个特点,就是bert这种类似的question answering叫做抽取式问答,答案只能在给出的上下文中。
* 
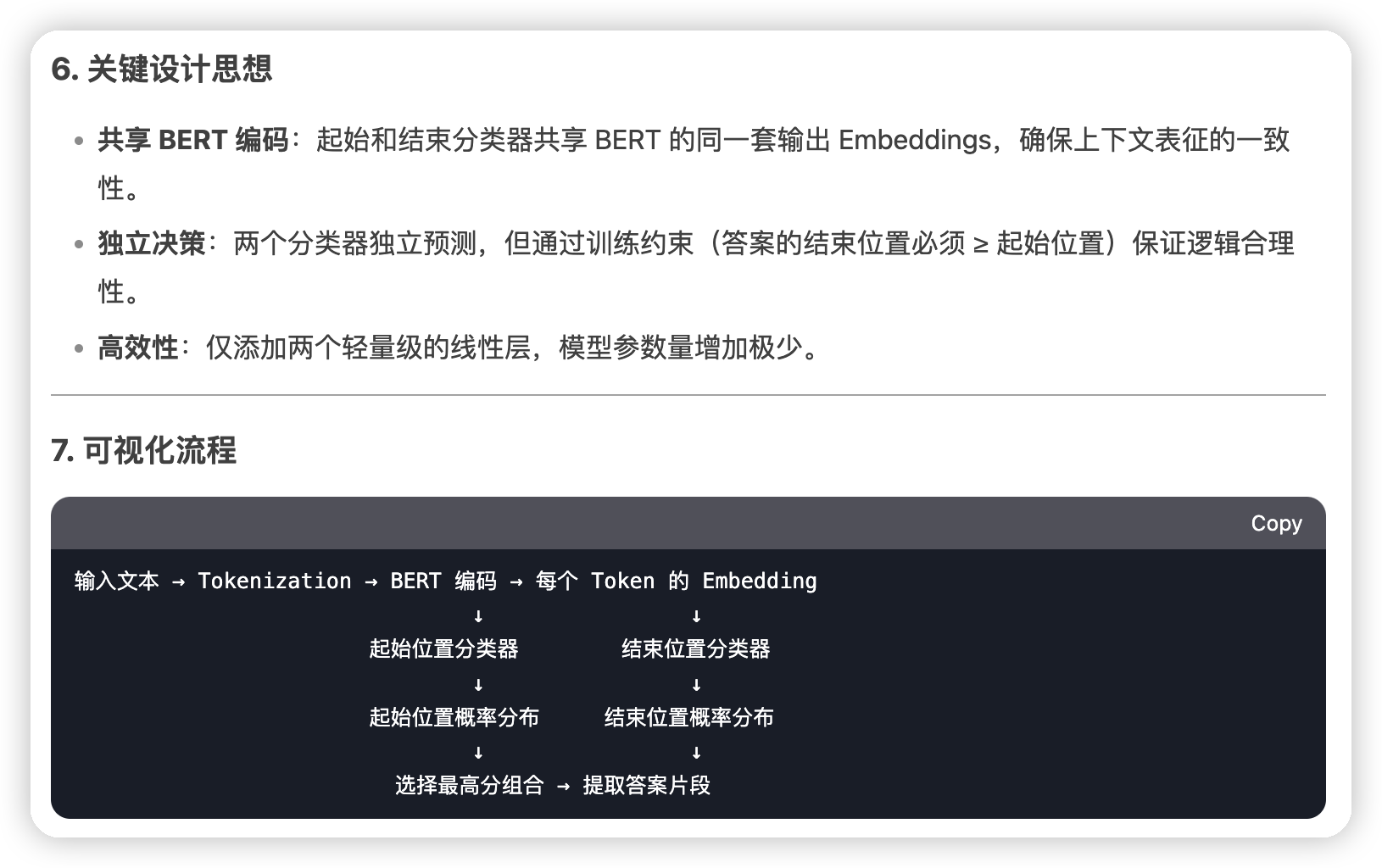
* 然后这里还有一个问题,是这个起始点和终止点的预测,是怎么和bert的输出接到一起的
* 
* 
* 
消融实验
这块我不是特别想看原文了,直接叫deepseek帮忙看的:
* 
* 
* 
*

文章评论