终于来学习transformer了
seq2seq就是一种实现。这里的区别是:
* seq2seq特指 encoder/decoder的架构,先encoder编码成一个vector,再用decoder生成输出
* transformer就是这种
* Transduction Model 不仅限于编码器-解码器架构,还可以包括其他形式的序列转换方法。
- 例如,基于规则的系统、统计模型或端到端的神经网络模型。

attention的作用是用来捕获长距离依赖关系,这里再来解释一下:

To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as [17, 18] and [9].
transformer之前,做transduction model都是用RNN,或者convolution。
Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure [5, 2, 35]. Here, the encoder maps an input sequence of symbol representations (x 1 , ..., x n ) to a sequence of continuous representations z = (z 1 , ..., z n ). Given z, the decoder then generates an output sequence (y 1 , ..., y m ) of symbols one element at a time. At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
encoder-decoder架构的模型。这里提到了auto-regressived的概念,再复习一下:


transformer的架构也是一样的:
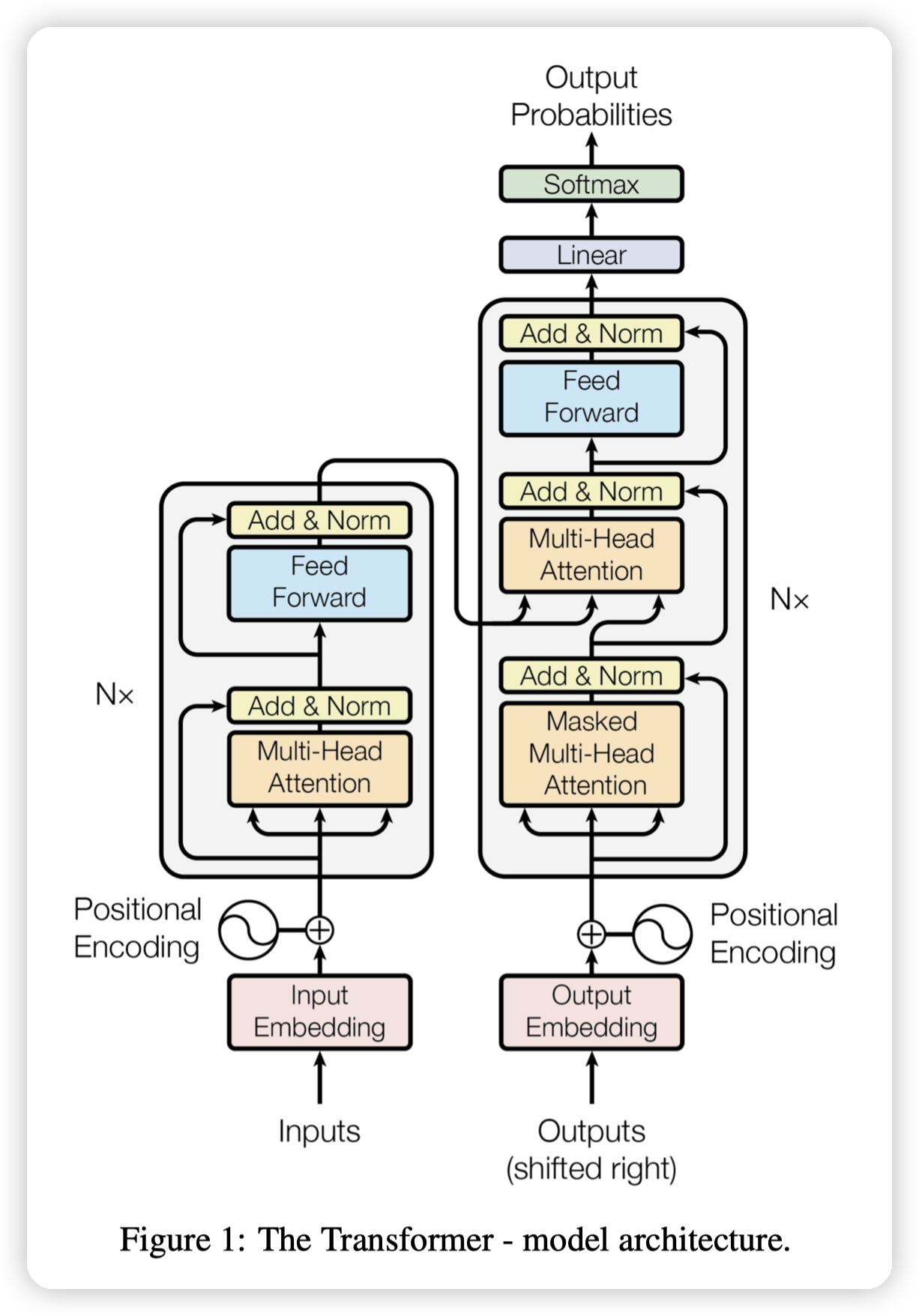
Encoder
encoder有6层一样的,每一层有两个子层,在图中有表示:
* 第一层是multi head self-attention
* 第二层是positionwise fully connected feed-forward network,这个可以理解为一个长度为1的卷积。就是给每一个元素单独过一个全连接层,而全连接层的权重是共享的。
* TODO,为什么不走全连接层,因为计算复杂度?
层与层之间有 residual connection,让参数学diff,而不是直接学习输出。以及normalize,归一化数据的输入,避免影响网络训练
为了保证利用上residual connection,每一层的输入和输出的维度都是相同的,都是d = 512。
不过大的层与层之间看起来是没有residual connection的,这里应该还是有做升降维的空间的。不知道为啥没搞?
Decoder
decoder也是6层。有3个子层:
* 第一层和第三层相同
* 第二层是一个multi head attention。这里的attention是decoder的output对encoder的attention。有点本次生成结果,要看之前的状态的意思了。
decoder还需要加上对未来的掩码,避免关注到未来的位置。
* 一个细节是,这个掩码只能加到attention中,在算softmax的时候才可以忽略权重。加到input里并不能让attention忽略这里的权重
Attention
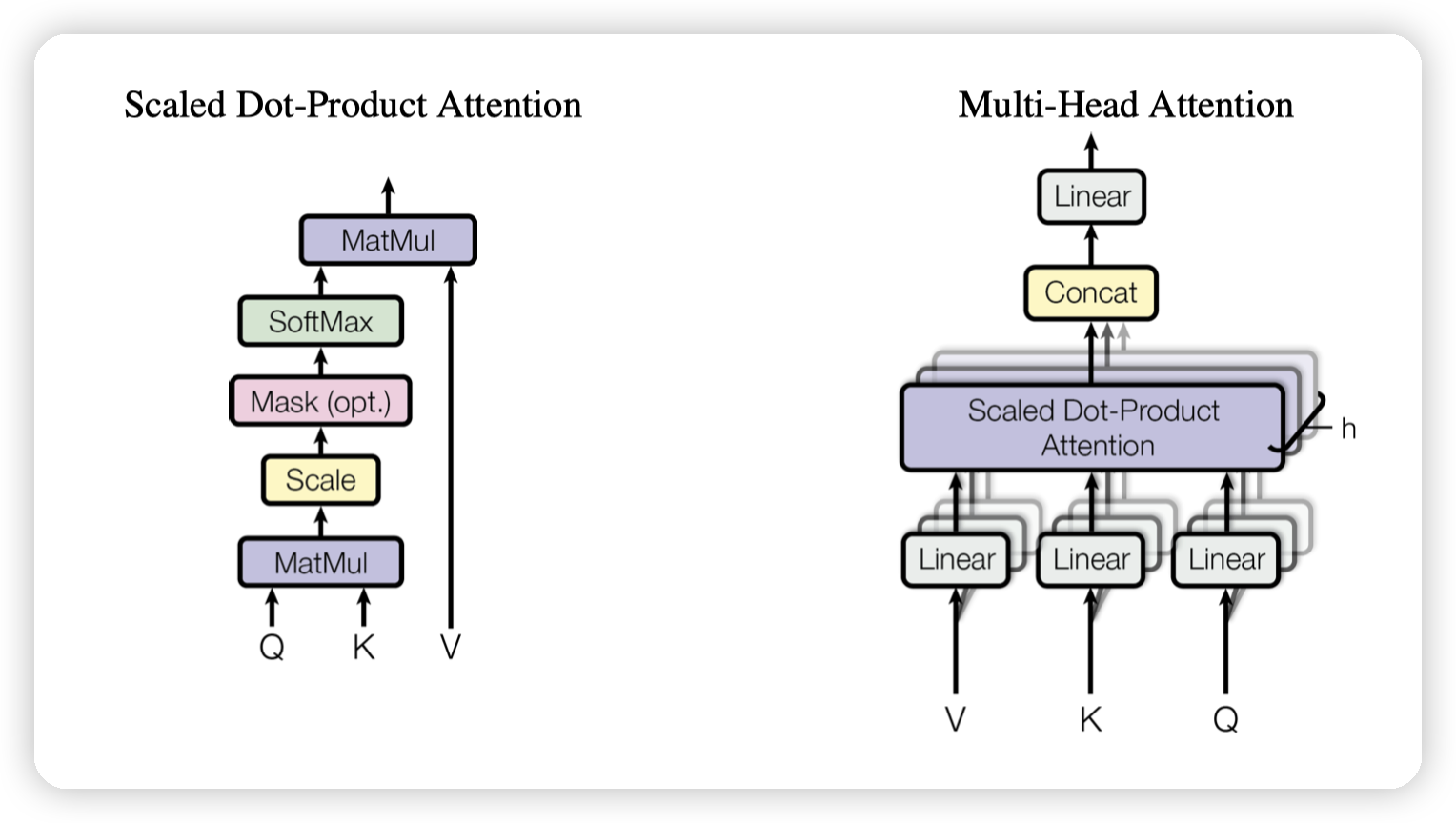
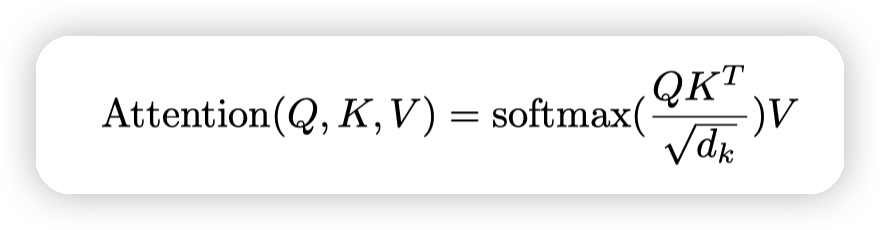
基本的计算公式
这里有一些额外的解释:
* 有两种常用的attention:additive attention,dot-product(multiplicative attention)
* additive attention用单层的feed-forward network来计算compatibility(可以理解为注意力?)
* 这里使用的是dot-product,但是多了一个scaling factor,就是开根号。
* 因为他们发现在d变大的时候,additive attention表现会更好,可能是因为dot product会导致数据移动到softmax的边缘处,此时梯度会很小
* 因为dot product计算快,并且效果相似,所以选择了dot product,然后加上scaling factor来缓解梯度的问题

对QKV的一些理解

这里还有一些例子
有关multi head,这里是在做线性变换的时候,把d这个维度,也就是特征的维度减少了。
最后多个head的输出拼接起来成为原来的d。
需要注意的是,QK的d可以和V的d不同。因为QK是计算相似性的,得到一个比例再放到V上面
paper中的d是512,他们分了8个head,每个head的dv/dk都是64
Embedding and Softmax
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension d model . We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [30]. In the embedding layers, we multiply those weights by √ d model .
这一段有两个细节:
* 这里说的两个embedding layer分别是encoder input和decoder input
* 权重乘上一个根号d model


之所以称上一个因子是因为初始化用的比较小的方差。
相当于是对参数做一下归一化
positional encoding
因为transformer没有RNN了,也没有convolution了。所以需要positional encoding来反应输入序列的位置信息。
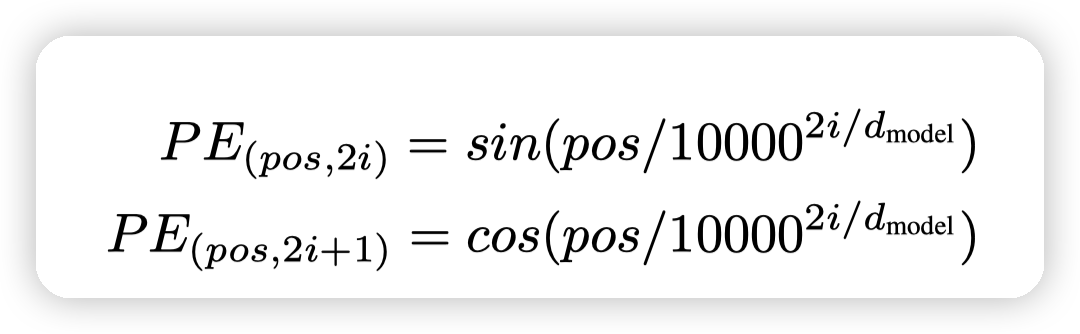
详细一些的可以看这个文章:https://zhuanlan.zhihu.com/p/454482273
用正弦曲线的作用是:
for any fixed offset k, PE pos+k can be represented as a linear function of PE pos .
也有其他的方法可以做到类似的效果,但是因为正弦曲线的计算简单,就用这个了。

这里可能有的一个直观问题是:
虽然你说的正弦函数有比较好的性质可以用线性变化表达相对位置。但是在使用中,这个positional encoding和embedding编码到了一起,这个时候模型还容易利用到这种性质吗?
* 公式中可以看出来,还是会有一样的性质的
* 用着确实有效。

几种捕获位置相关信息的做法:
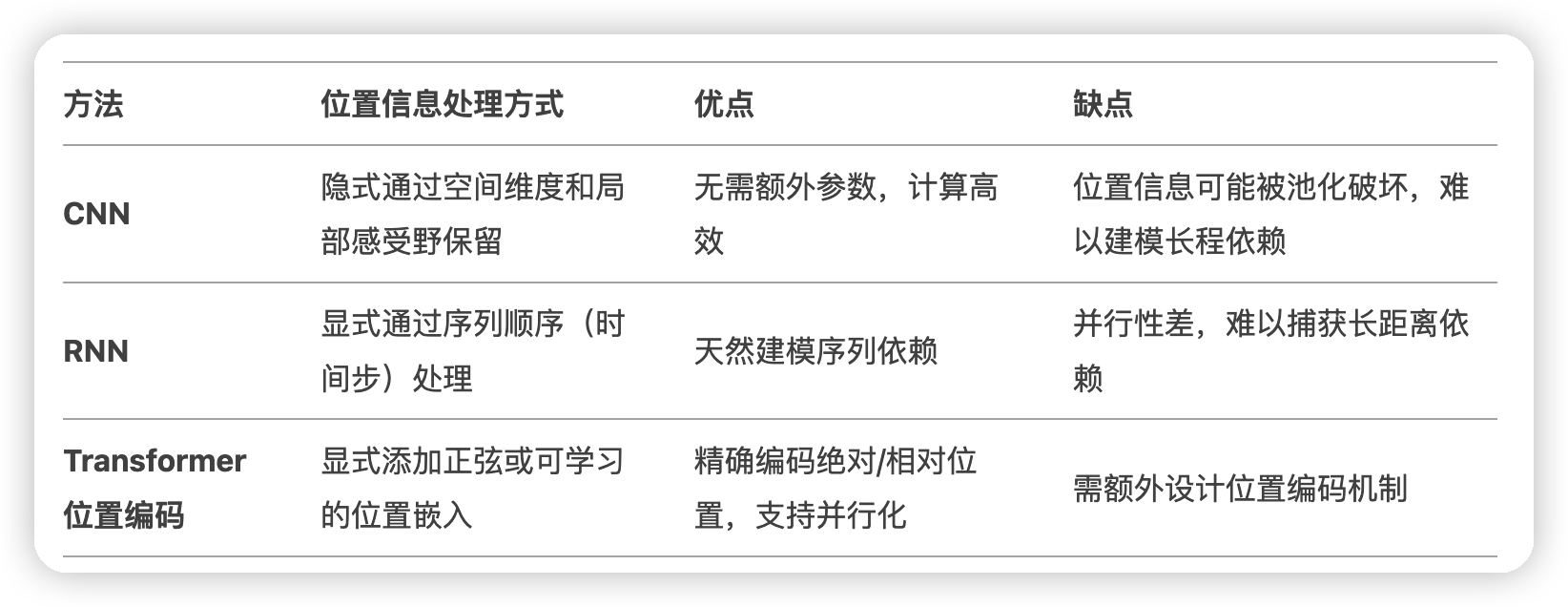
Why Self-Attention
设计层的关键点:
* 总的计算复杂度
* 并行计算的数量
* 长距离依赖的捕获
* 具体来说,是说模型捕获两个token所需要的路径。
* 比如RNN,就是计算sequence length次,才能得到第一个token和最后一个token的依赖
* 而transformer则是常数,因为是每一个位置对其他所有位置的attention。
Learning long-range dependencies is a key challenge in many sequence transduction tasks.
One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network
The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies
transformer这种计算方式在序列长的时候会退化,这时候就可以只捕获局部的信息。类似卷积一样,每一层只看旁边r个位置的attention。
另一个比较好的点是,self-attention可以让模型的可解释性更强一些,因为可以观察attention的分布来看模型这一层都捕获了什么信息
attention的思路就是考虑多个位置的融合信息。既然CNN可以用在序列处理上,attention这种自然也可以放倒CV上做一做。
搜了下vision transformer就是做这个的

这样就可以利用self attention的机制,来处理全局信息了。
这里也有一个缺点,是虽然他通用,但是他没有CNN的平移不变性和局部性,这一点需要模型自己学习。比如需要“一只猫从各个位置出现的图片”来学习平移不变性。
这估计也就是为什么vision transformer需要大量数据了。或者说为什么transformer需要大量数据?因为他需要大量数据来训练这样通用的模型。

这种混合模型就是比较自然的想法了
后面还有attention的可视化
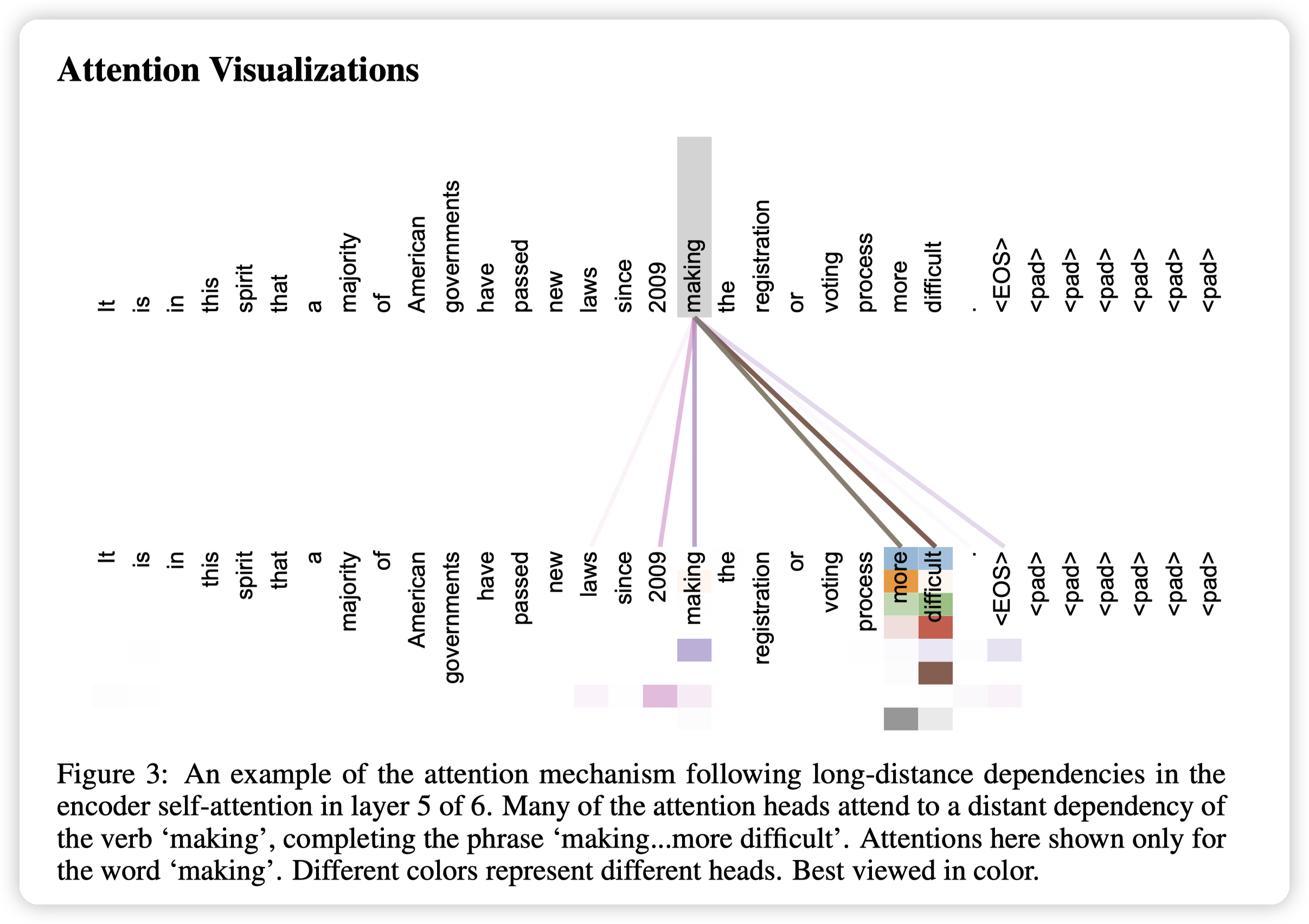
这里是making和more/difficult关注到了。
表示模型学会了making more difficult这个短语。这个应该算是语意上的
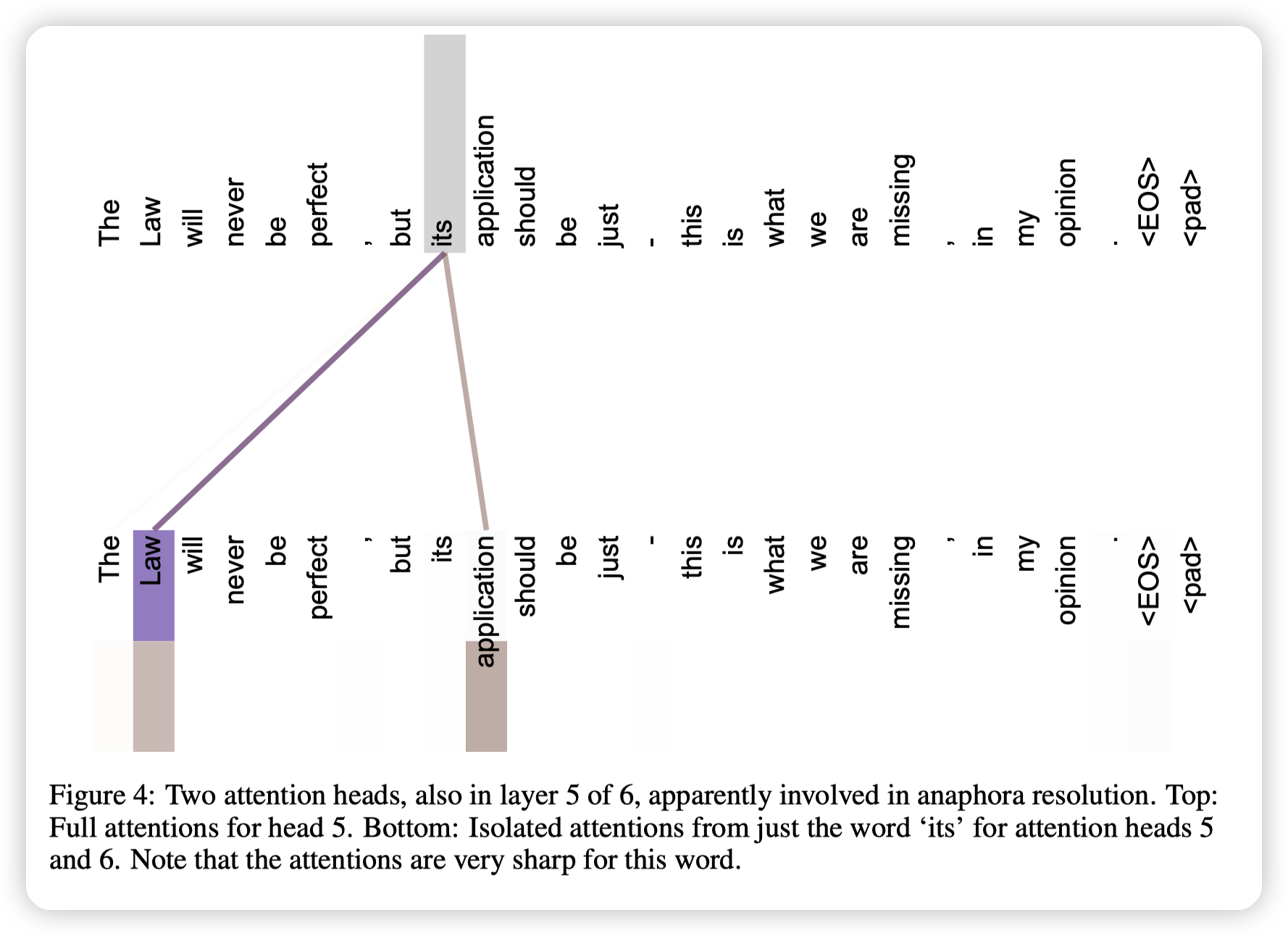
另一个语意上的,这里的its关注到了前面的law,表示他理解到了its指代的是law。
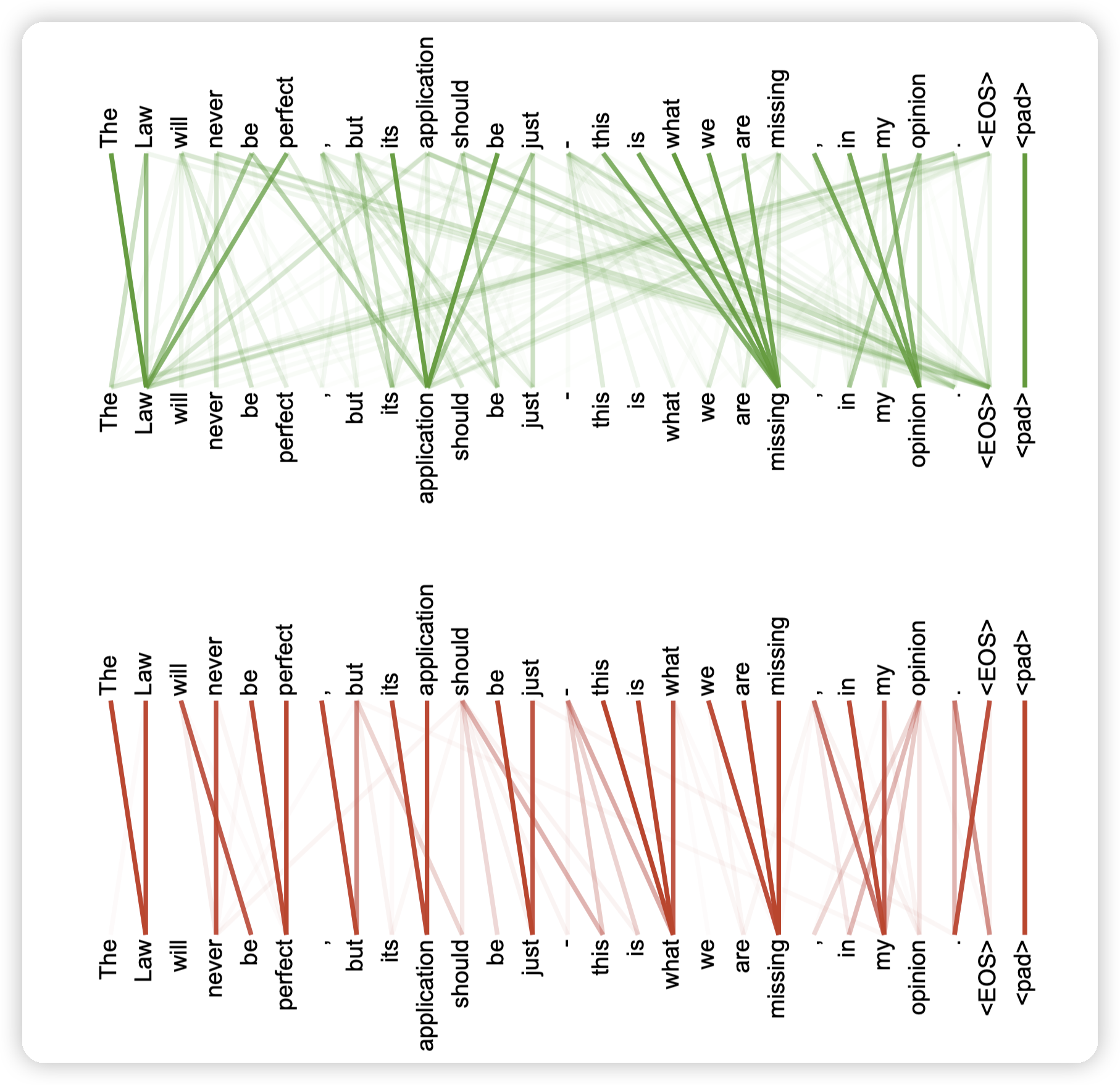
这里则是句法结构上的理解:
* 上面这里,比如this is what we are missing。
* 下面这里:The law, will be, this is what, we are missing。说明学习到了结构上的信息
神奇

文章评论