最近又重新看了看graphrag相关的一些东西,简单整理点内容。
目前能用的开源框架,graphrag相关的,除了ms的graphrag之外,还有ragflow,以及dbgpt。这里简单介绍一下他们graphrag的实现方式:
RagFlow
ragflow有多种类型的解析方法,比如paper/book等,然后KG是专门的一种,代码在rag/app/knowledge_graph.py里
- index.py:build_knowledge_graph_chunks
- 看注释里基本流程是和ms的graphrag是一样的
-
并行执行graph extractor,这里的prompt和graphrag是一样的
- 实体提取的策略也和graph rag相同,会走多轮,尝试提取出最多的实体数量
-
然后直接构图(这里貌似和graphrag不太一样,graphrag应该没有分别构图然后merge的流程,不过没啥影响,这里不太涉及到LLM
-
并行提取每个文档的图之后,做graph_merge
- 点边的merge逻辑比较简单,比较关键的是属性上的。这里他简单的判断,两个重复的点,如果第一个的description不包含第二个description的前32个字符,则把后一个点的description append上去。用这样来做去重。
-
ms的graphrag应该是用llm做的总结
-
merge之后,有一个entity resolution的流程,这里就是实体去重了。
- 他会先根据entity type去分类实体,然后对于每一类的实体,两两遍历,检查他们是否是相似。这里是一个预检查,看他们的编辑距离。
- 这个预检查有点怪怪的...,看代码实现,如果是英文的,看编辑距离。如果不是英文的,则只要属性中有一个相同的就算相似。
-
性能上,感觉如果先做GE,然后对相似的再去让LLM判重会更好一点
-
如果预检查过了,会让LLM去判断两个实体是否是一样的。
-
最后会消除重复的点,并merge点上的属性,以及边和边的属性
- 他会先根据entity type去分类实体,然后对于每一类的实体,两两遍历,检查他们是否是相似。这里是一个预检查,看他们的编辑距离。
-
然后是community,这里直接是leiden跑聚类,然后总结community,也是和ms graph rag一样的流程
-
最后有一个多的mind map extractor
- 这里的输入是用的graph rag之后的数据。社区信息,点边什么的都用上了
-
然后就是一个prompt,用markdown格式直接生成mind map了。然后会有markdown to json,再转化成python的map
-
mindmap的merge比较简单,就是两个dict的map。有点类似树的归并,相同层级,相同level,就把数据append了
-
实际跑起来效果不是很好,基本上就是两层的mindmap,可能是他们代码有什么bug,这里写的比较乱。
DBGPT
一个使用的例子在examples/rag/graph_rag_examples中,有两种kg:
- BuiltinKnowledgeGraph
-
CommunitySummaryKnowledgeGraph
rag构建流程:
- index_store.load_document
- 先看builtin knowledge graph
- load_document传入list chunk
-
triplet_extractor,提取三元组
- 通用的LLMExtractor,不同子类是不同的parse response以及prompt
-
这里的triplet就是subject, predicate, object,主谓宾,然后是个few shot learning。感觉和ms那个思路不太一样
-
把三元组写入到graph_store中
-
检索的话是用llm先提取关键词,然后直接去图上搜索了,貌似也没有向量相关的能力
-
再看下community summary kg
- aload_document_graph
- 在图上加上doc相关的信息:
- 由doc/chunk组成的顶点
-
Doc include chunk
-
Chunk include chunk
-
Chunk next chunk
- 在图上加上doc相关的信息:
-
aload_triplet_graph
- Graph extractor
- Extract
-
在chunk_history中(是一个vector store)搜索近似的chunk,作为当前chunk的上下文保存起来,并把当前chunk存到chunk history中
-
Llm extractor中支持加上history一起做提取。所以这里会把当前chunk和相关联的chunk一起去提取实体。也是few shot learning,没有额外的魔法
-
这里的prompt还是没有类型这个概念的。实体只有名字,和summary。关系只有实体/实体/summary
-
每一个chunk都会生成若干个graph,这里区分开的目的是方便记录顶点和边都和哪些chunk相关联。
- Graph extractor
-
build_communities
- Tugraph plugin,也是调用leiden,先发现社区
-
对于每一个社区,拿出社区相关的点边来,有一个LLM summarizer。prompt中会告诉LLM他具有社区总结和实体关系识别的功能,然后直接把string类型的图吐给他让他直接做识别
-
这里感觉上下文很容易爆了?把整个图都吐出来的话
-
然后会把community相关的信息放到meta store中,存到vector store中了
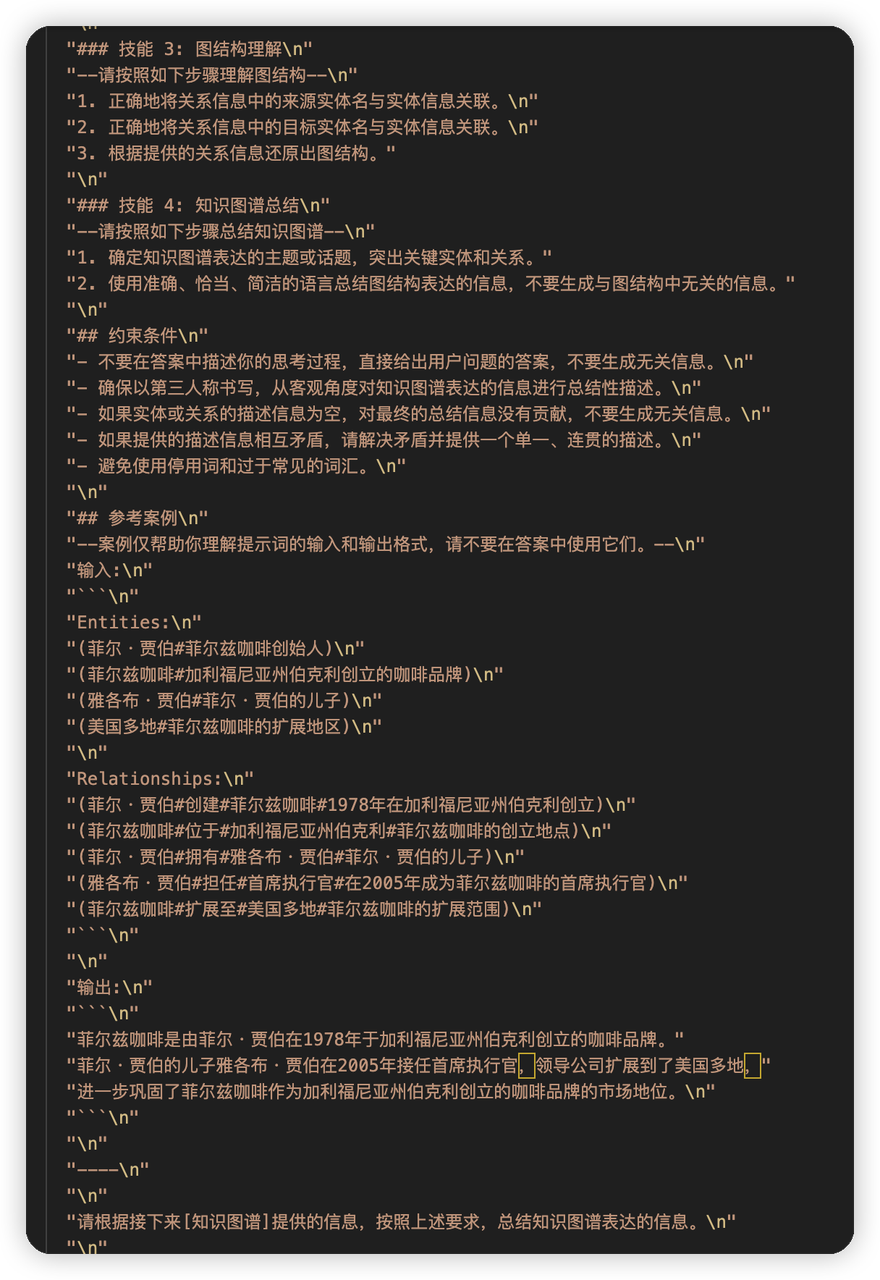
-
search相关:
- asimilar_search_with_scores
- 因为community是存储在vector store的,先根据query做近似搜索。(我比较怀疑,把这么多数据都用embedding整理可以吗,感觉文本空间上的搜索在这里效果不一定会好)
- 不过ms graphrag直接搜所有community也有点变态
- Keyword extractor提取关键字,然后在继续是做graph_store.explore(),搜索子图
-
然后这里还有一种document graph的搜索模式
- 搜索和这个实体关联,或者包含这个实体的chunk,以及对应的链。(应该也是会很多,这里有深度限制)
-
然后这个包含实体的chunk应该需要全文索引的功能
-
上下文都搜索完了之后,有一个hybrid search prompt,把社区的summary,三元组的数据,以及关联的doc图中的数据拿出来,丢给大模型做问答,只有一轮。
-
这里基本不涉及到超context window的考虑,感觉有点虚?不知道是不是这里导致dbgpt在做建图的时候卡住的问题。
- 因为community是存储在vector store的,先根据query做近似搜索。(我比较怀疑,把这么多数据都用embedding整理可以吗,感觉文本空间上的搜索在这里效果不一定会好)
- asimilar_search_with_scores
- aload_document_graph
- 先看builtin knowledge graph
MS GraphRAG
ms最近在graphrag相关又做了一些探索,发了几篇文章,这里简单介绍一下:
* https://www.microsoft.com/en-us/research/blog/graphrag-auto-tuning-provides-rapid-adaptation-to-new-domains/
* https://www.microsoft.com/en-us/research/blog/introducing-drift-search-combining-global-and-local-search-methods-to-improve-quality-and-efficiency/
* https://www.microsoft.com/en-us/research/blog/graphrag-improving-global-search-via-dynamic-community-selection/
3个主题,Auto tuning,DRIFT search,以及dynamic community selection
Auto tuning
这里主要针对的是ms graphrag要求使用者在使用的时候提前识别出要提取的实体类型,所以他们搞了一个auto tuning,就是根据数据集去调整prompt,让prompt可以直接提取和数据集相关的实体,而不需要用户预定义。
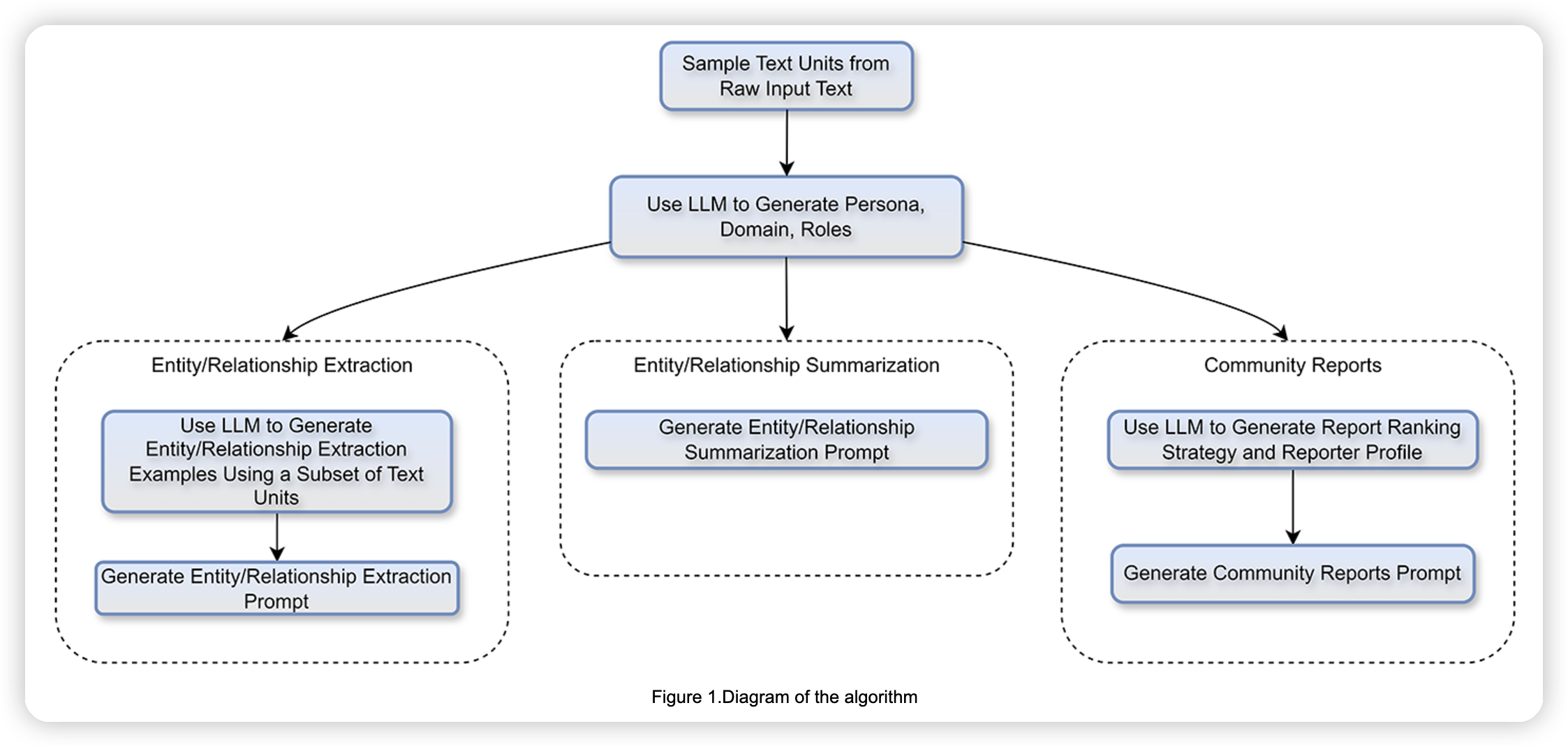
目前实现的比较简单,基本上就是不告诉模型具体的类型,让他自己去提取实体。然后会sample数据集中的一些数据提取出来一些例子,做few shot learning
prompt模版基本上是固定的,只不过few shot learning这块不一样:
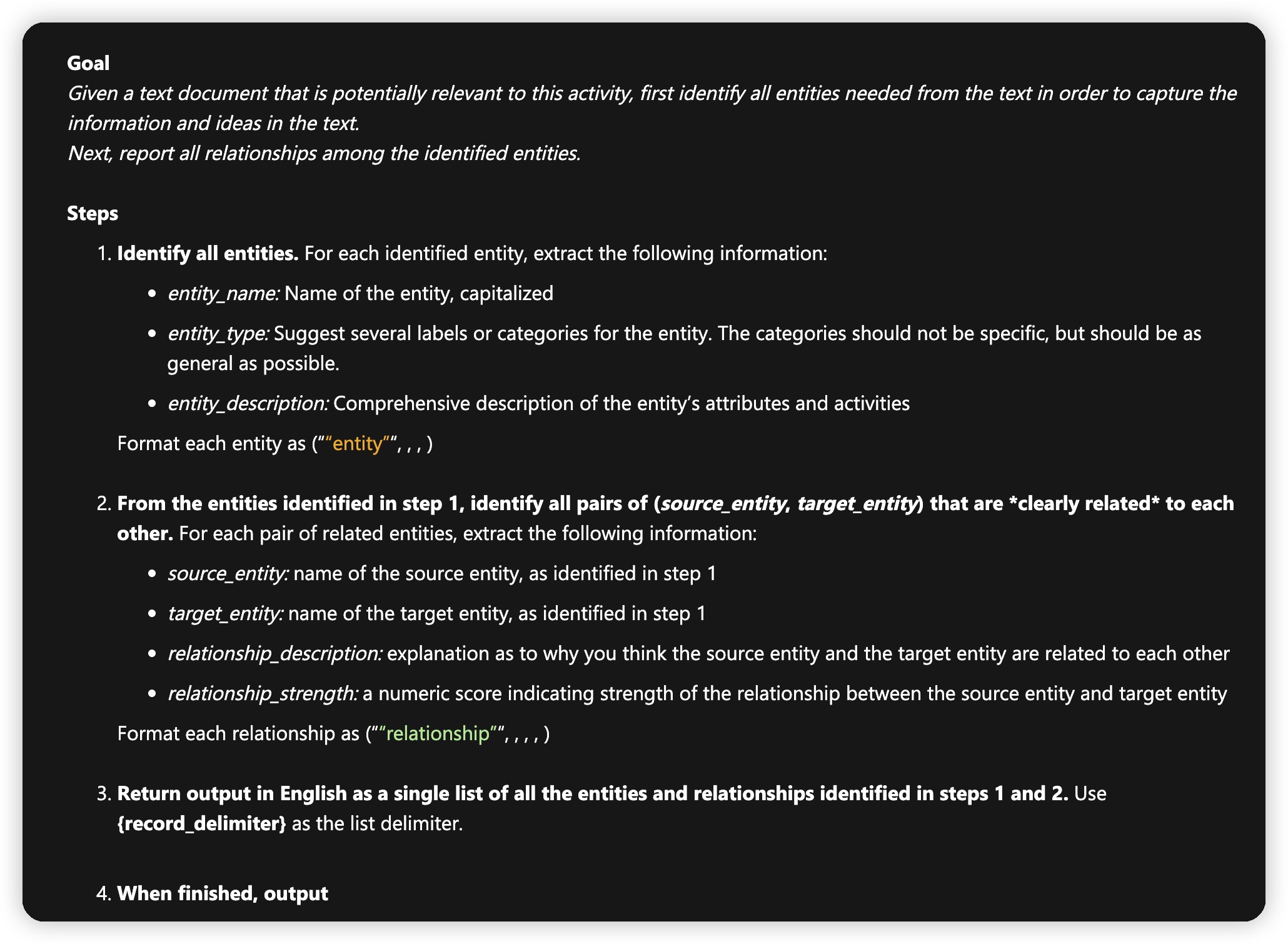
因为不指定具体的类型了,所以提取出来的实体肯定是更多的。这里我感觉ms graphrag应该默认是这种行为,除非非常确定要提取的实体类型
然后通过和数据集相关的few shot learning来提高实体提取的效果。
DRIFT search
DRIFT的意思是dynamic reasoning and inference with flexible traversal
基本思路就是通过高层的社区信息来帮助回答local search的答案
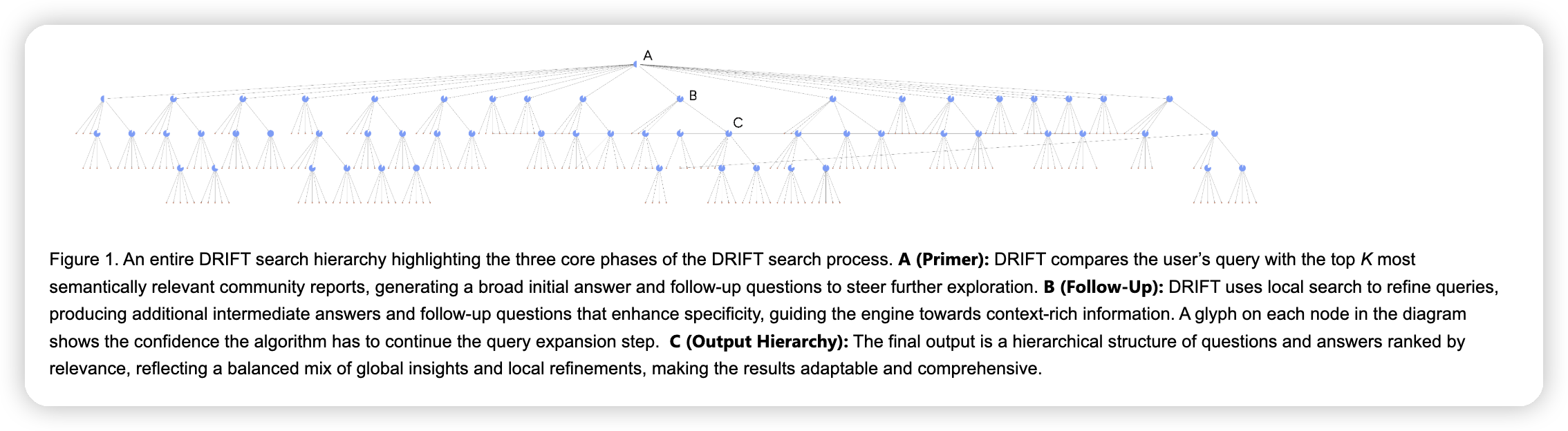
流程是:
* 首先根据用户的query,搜索topk关联的community reports。然后针对每一个community reports,生成initial answer,以及一些follow-up questions
* 然后使用local search来回答这些follow-up questions。来补充这个社区下,回答用户query的更多上下文。这里可以做多轮,ms说他们这里就做了两轮
* 然后把搜索出来的这个树,再去rerank一下,取一部分给LLM生成最终的回答
ms说这里有一些分治的感觉,把query分解成若干个和community相关的问题,并去用细节回答这些问题,最终再整合答案。主要针对的是一些既需要深度也需要广度的回答。
Dynamic community selection
这篇文章主要针对的是,ms graphrag目前针对global search会固定一层community level去做搜索。这种方式相对来说比较低效,因为并不是所有的community都需要拿来回答用户的query。
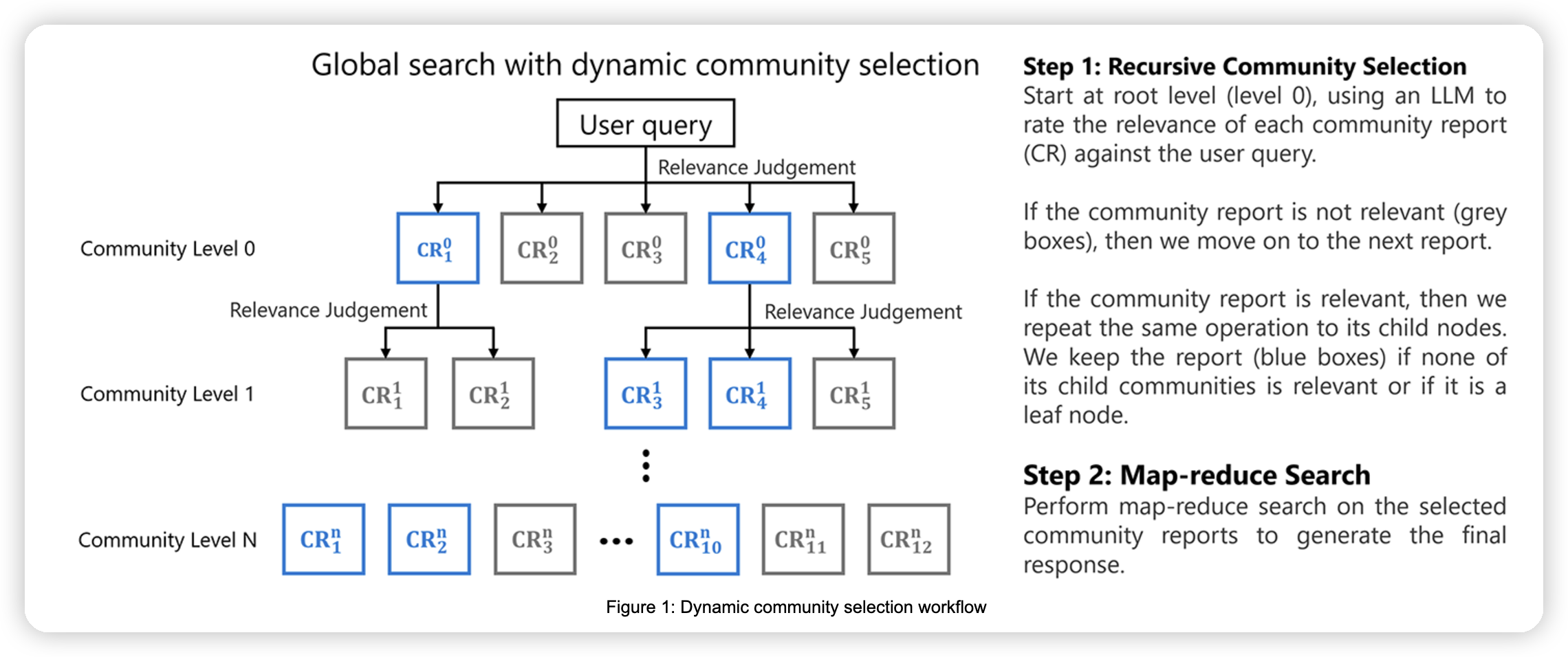
基本思路是:
* 从root节点开始遍历,针对每一个community,判断他是否和用户的query相关。如果相关的话,则遍历到他的子节点中,获取更多的信息。不相关的话,则停止搜索
* 最终把选出来的相关的community report一起生成最终的答案
这里比较好的利用了分层图的结构,可以做到由抽象到具体的搜索,并及时prune掉不需要的上下文。其实感觉上面的drift search有点像了。
dynamic selection的另一个好处是,把问题拆解成了rating/answer,其中rating的部分可以使用一些轻量化的模型去做,从而减少开销。然后把最终的总结内容用能力比较强的模型来回答。

这里有一个benchmark
* 第一行是说,如果使用dynamic search at level 1,即在第一层prune掉一些report,回答的结果怎么样。右面基本上接近50%,说明和static search at level 1相比较,质量基本相同,并且开销减少了非常多
* 第二行是说,如果允许dynamic search到level 3,此时有29个query会收集到更多的community report,从而增加了cost。但是回答的质量也显著的增加了。
summary
其实可以看到,ms逐渐在提高graphrag的易用性,使用auto tuning,以及通过dynamic selection避免用户指定具体的community level。
并且drift search/dynamic selection也在开发分层图结构的优势,可以从抽象到具体,global insight/local refinement结合起来回答。
其实也可以感觉到,drift search/dynamic selection还可以再做一些融合,来避免让用户指定global search/local search,比如再去利用一下分层图的性质,把dynamic selection做到叶子节点这个级别,这样可以有更好的易用性。
LazyGraphRAG
突然发现又出了一篇,再补一下:
* https://www.microsoft.com/en-us/research/blog/lazygraphrag-setting-a-new-standard-for-quality-and-cost/
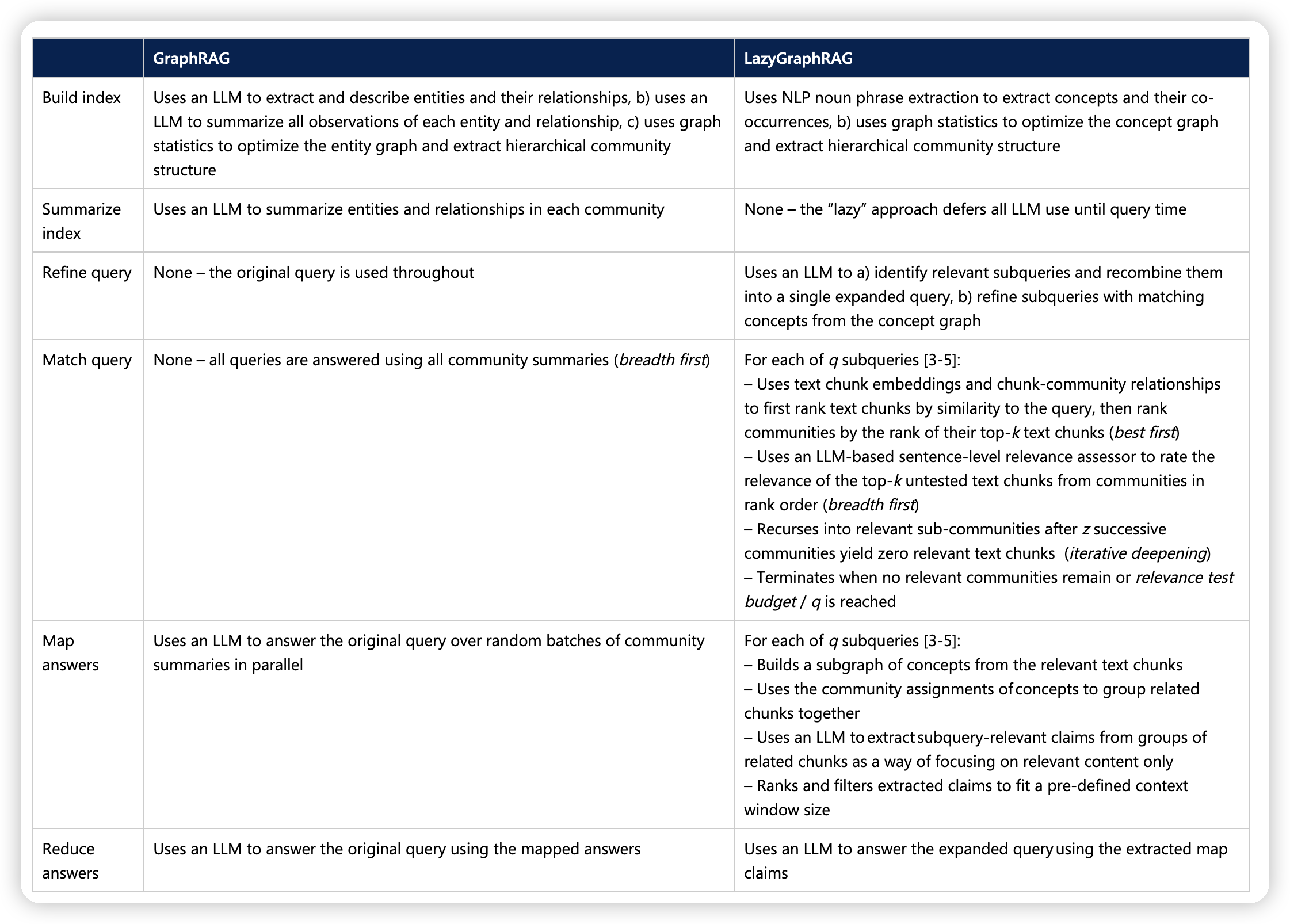
LazyGraphRAG的做法:
* 使用NLP技术(noun phrase extraction)去提取concepts,然后构建分层图
* 不做community summarize
* refine query:
* 使用LLM提取相关的sub query(又是分治了)
* 针对sub query,使用上面提取出来的concept graph来refine query(应该是把问题针对现有的concept重提一遍?)
* 把sub query组成一个大的query
* match query:
* 对于每一个sub query
* 首先根据text chunk embedding来rank text chunk
* 然后根据text chunk rank以及chunk-community relationship来rank community
* 再根据community order去用llm rank其中的text chunk(这里是怎么做的,遍历所有的text chunk?)
* 递归向下,遍历子的sub-community,直到community没有找到关联的text chunk了
* (这里细节的实现还不是很清楚,要等他放开实现再看)
* map answer:
* 对于每一个sub query
* 把提取出来的相关的text chunk构成一个subgraph
* 根据community来group text chunk,然后用LLM去提取相关的上下文,再去rank一下
* reduce answer
* 把相关上下文,和组成的大的query用LLM来总结答案
感觉核心思路就是,community summarize/entity extraction要针对query去做,所以就根据noun先提取出所有相关的概念,然后在搜索的时候再去做community相关的聚合
结果显示在各个方面都吊打了其他的搜索方式,并且在global search上,可以用非常少的cost达到相似的效果
- 有一个点是,这里并没有看出来有递归向上的总结机制,还是可以很好的回答global query。
- 可能是,global query只需要相关的一些chunk就能回答
- 他这里的测试有问题?
LazyGraphRAG表现出了,在比较好的查询机制下,就算没有LLM接入的data summarization,也可以达到非常好的效果。
* 核心应该还是针对问题去做相关信息的提取
* 并且这种方法对one-off query比较有用,比如可能针对一个数据集就想问一下问题。
不过这里也说了,并不是说这种方法好,就可以替换掉原本的graphrag的方式了:
* 预先提取的实体/社区总结可以做更多的事情而不只是回答问题,比如对数据集有一个概览,或者是生成报告
* 如果预先提取的实体,再加上LazyGraphRAG的问答机制,可以做到更好的效果
* 针对LazyGraphRAG的问答机制去做的graph data index机制(比如pre-emptive claim/topic extraction)可以做到更好的效果

文章评论