最近新出了一本书,是Modern B-Tree Techniques的续集,More Modern B-Tree Techniques。这里做一下简单的总结。
后面打算整理一下Btree相关技术,写一篇文章,会总结一下这本书,前作,一些相关的Paper,以及一些工业界的Btree实现。
TLDR
tldr版,整体来说,我感觉书中细节的内容不多,基本上就是概括一下几个方向的技术,这里大概总结了一下,然后列了一些我觉得值得关注的paper:

- btree结构,可能关注的点
- Write optimized btree就是lsm的思想
- Root to leaf traversal就是pointer swizzling
- Self repairing btree就是在btree的节点上加fence key,用来做校验。没有更强的校验了
- Deferred update就是可以先只更新主表,延迟更新二级索引

- Differential data structure优化写入性能的思想
- 感觉都是一些lsm的技巧,compaction策略/bloom filter优化查询什么的

- btree上的查询
- 有序性可以加速group/agg查询,以及一些集合的查询,如union/and等
- 可以通过一些compression手段,如prefix truncation/offset value coding加速btree节点内的查询性能

- btree上的并发控制
- 各种上锁方法,比如更新粒度的gap lock。总结了下之前btree上锁的几种方法,ARIES/IM,ARIES/KVL等
- 多版本存储上的上锁方法,和btree无关,目前基本成为通用的实现。
- 在lsm上的上锁方法提了下spanner的,就是维护查询的range,放到一些索引结构里求交集,放弃了在btree上上锁的方式

- Memory btree
- 讲btree的层次结构可以应用到不同的存储结构上(cache/memory,flash/disk)
- Pointer swizzling
- Single page recover,就是aurora那个
- 然后是新出现的内存数据库的一些并发控制技术,和btree关联也不算很大
Paper list
- Compression:
- T. Do and G. Graefe, “Robust and efficient sorting with offsetvalue coding,” ACM TODS, vol. 48, no. 1, 2023, 2:1–2:23.
- G. Graefe and T. Do, “Offset-value coding in database query processing,” EDBT Conference, 2023, pp. 464–470.
- H. Zhang, X. Liu, D. G. Andersen, M. Kaminsky, K. Keeton, and A. Pavlo, “Order-preserving key compression for in-memory search trees,” ACM SIGMOD Conference, 2020, pp. 1601–1615.
- Page
- G. Graefe, I. Petrov, T. Ivanov, and V. Marinov, “A hybrid page layout integrating PAX and NSM,” IDEAS, 2013, pp. 86–95.
- Query processing
- T. Do, G. Graefe, and J. Naughton, “Efficient sorting, duplicate removal, grouping, and aggregation,” ACM TODS, vol. 47, no. 4, 2022, 16:1–16:35.
- P. V. Sandt, Y. Chronis, and J. M. Patel, “Efficiently searching in-memory sorted arrays: Revenge of the interpolation search?” ACM SIGMOD Conference, 2019, pp. 36–53.
- Insert optimized techniques
- N. Glombiewski, B. Seeger, and G. Graefe, “Continuous merging: Avoiding waves of misery in tiered log-structured merge trees, unpublished,” 2021
- C. Luo and M. J. Carey, “LSM-based storage techniques: A survey,” The VLDB Journal, vol. 29, no. 1, 2020, pp. 393–418.
- G. Graefe, H. Kimura, and H. A. Kuno, “Foster b-trees,” ACM ToDS, vol. 37, no. 3, 2012, 17:1–17:29.*
- H. V. Jagadish, P. P. S. Narayan, S. Seshadri, S. Sudarshan, and R. Kanneganti, “Incremental organization for data recording and warehousing,” VLDB Conference, 1997, pp. 16–25
- G. Graefe, Sorting and Indexing with Partitioned B-Trees. CIDR, 2003.
- Lock
- G. Graefe, “Avoiding index-navigation deadlocks,” in Synthesis Lectures on Data Management, Morgan & Claypool Publishers, 2019.
- G. Graefe, “Deferred lock enforcement,” in Synthesis Lectures on Data Management, Morgan & Claypool Publishers, 2019.
- G. Graefe, “Orthogonal key-value locking,” in Synthesis Lectures on Data Management, Morgan & Claypool Publishers, Extended from Goetz Graefe, Hideaki Kimura: Orthogonal Key-Value Locking, BTW Conference, pp. 237–256.
- Recovery
- G. Graefe, W. Guy, and C. Sauer, “Instant recovery with writeahead logging: Page repair, system restart, media restore, and system failover,” in Synthesis Lectures on Data Management, 2nd edition, Morgan & Claypool Publishers, 2016, pp. 1–113.
Notes
然后是一些细节的点:
Chapter 2
- 这里提到了一个特殊的点,是Btree上存储的是哈希的值,这样可以保证key分布是均匀的,从而可以使用btree上的插值搜索,避免二分了。同时也需要缓存下所以的branch node,避免io
- btree consistency checking,如果没有sibling pointer的话,每个page可以引入fence key,来提供btree结构的一致性校验,可以提前发现问题。
- 校验一般发生在root-to-leaf traversal,可以对比parent page上记录的key和子节点上的fence key
Chapter3
- 3.1 In-Page Organization and Compression
- Btree搜索的开销:一般是和列式存储进行对比。一般的经验来说,如果要查询的数据超过了整体数据的1%,那就不用二级索引搜索,直接用列存扫描即可。
- 这里提到了masstree,就是btree和trie的结合版。效果比较类似btree使用了前缀压缩,即把相同前缀的kv使用trie压缩到一起,然后不同的地方就用btree存储。
- 但是这里提到一个比较关键的点是,还不清楚masstree和btree + prefix compression的性能对比。如果btree性能可以满足需求的话,就不需要重新引入masstree这样一个新的数据结构了
- order-preserving code可以在压缩btree节点内部的数据,提高扫描性能,并且还支持二分搜索
- 如果btree内部存储的是row id的话,可以再使用一些压缩方法来压缩row id
- 3.2 Learned Indexes
- 如果学习到的数据分布是均匀的话,就可以使用插值搜索来提高速度
- 3.3 Write-Optimized B-Trees, Foster B-Trees
- 这里介绍了一下Foster Btree,实际上非常类似Blink tree,只不过向右孩子的link是暂时出现的,当非叶子结点加入了指向新分裂出来的page后,就会把向右孩子的link删掉。
- 分裂位置的选择策略有很多种:
- 比如按照size分, 按照branch key最小分,以及按照workload分
- 3.4 Root-to-Leaf Traversals
- pointer swizzling
- 在btree的branch node上记录子节点的元数据,来支持层级结构的zone map/zone filter。比如记录min/max,count等
- 缓存root-to-leaf path来加速搜索。(一种可能的工业实现是innodb的Adaptive Hash Index)
- 3.5 self repairing btree
- 这里就是上面说的记录fence key,来做check
- 3.6 Deferred Updates and Deferred Index Optimization
- 延迟更新二级索引,可以等到二级索引用的时候在进行更新,可以做到batch io,以及做merge sort
- 这里也有一些differential data structure的思想,在memory中写入数据后,在merge到持久化存储的时候,再更新二级索引,实现延迟的二级索引更新。
Chapter 4
- 这一章其实主要是说类似LSM优化的技术,可以看lsm的那篇survey。
- 比如一些写入,查询的tradeoff
- 有一些关键的概念我暂时也没搞清楚,就不说非常详细了。
- linear partitioned btree
- continuous merging
Chapter 5
- 这一章主要提了很多offset value coding的作用
- 有序的结果中,可以做快速的集合计算,比如intersection/union/difference。这里就可以做不同索引之间的merge,避免扫描
Chapter 6
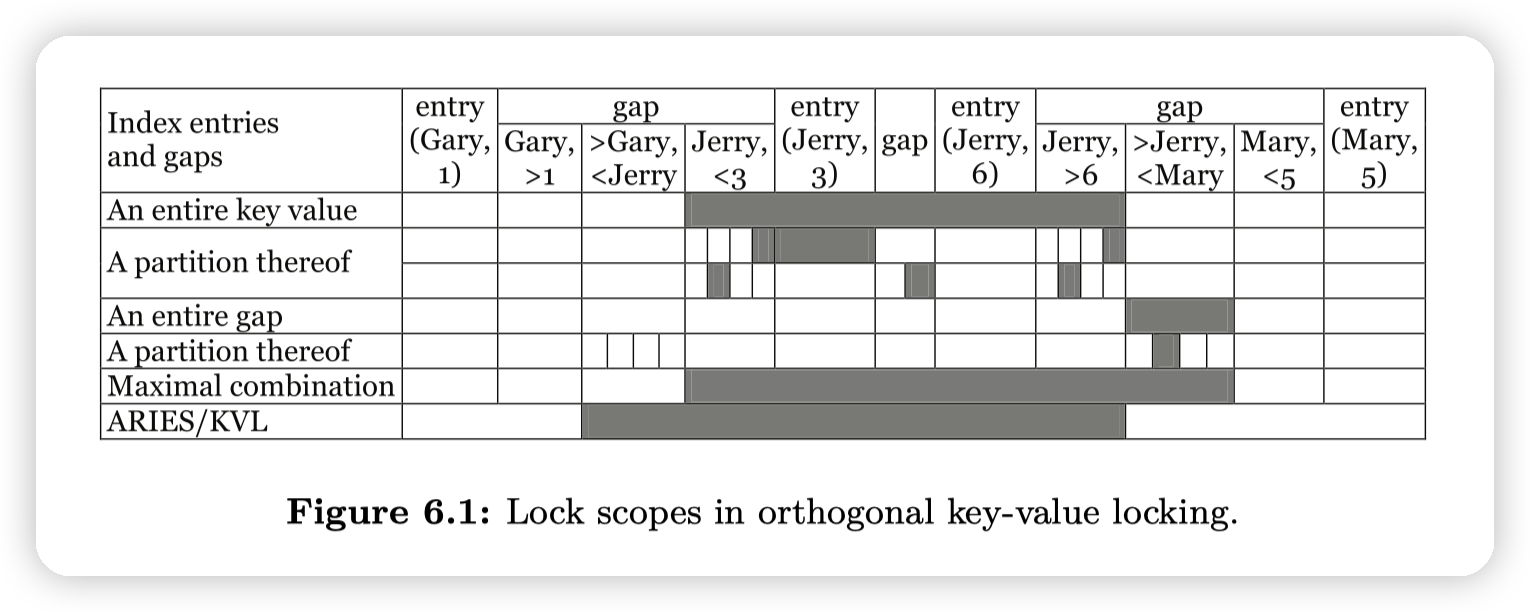
- 不同的锁方法的区别,有一个图比较直观:
- 多版本存储上的锁方法
- 如果是2PL的话,只需要2个版本来强化原本的2PL。整体思路就是,写者上写锁,创建一个uncommitted version,放锁的时候是更新committed version。读者上读锁,锁committed version,避免写者更新。可以提供更高的并发度
- 实际上在transactional information system中已经提到这种方法了,叫 2V2PL
- 只读事务的话,用多个版本提供快照读
- lock duration
- 提前放锁提高并发度,引入commit dependency
- 还有一个defered lock enforcement是上比较弱的锁(具体还没有细看)
- 还有点额外的技术,如early detection write-write conflict,以及mv storage,可以避免OCC的事务私有的buffer,这一点在近几年的事务并发控制算法里比较常见
- LSM上的锁
- 提了spanner的例子,上面的tldr中已经说了
Chapter 7
- pointer swizzling,又提了提
- btree在其他存储结构上的应用,比如cache/memory
- high-level lock
- 一个可能的点是,在内存数据库里,lock manager显得比较重,所以需要尽量避免
- 确定性数据库,先通过log确定好执行顺序,再执行
- 说了说single page recover
Summary
最后有一个总结,主要说了查询相关的,应该和作者在napa有关:
if business intelligence and machine learning require efficient scans of few columns but many rows within a table, column storage is superior to traditional database storage formats; but with b-trees suitably formatted and compressed, they emulate column storage and replicate its advantages very well

文章评论
Root to leaf traversal就是pointer swizzling 这个是不是写得有点误导性,pointer swizzling不一般说的是pointer指向的节点有可能是内存结构,也有可能是磁盘页面。pointer chasing?