最近有一个新开源的仓库openaurora,以及对应的paper《Understanding the Performance Implications of the Design Principles in Storage-Disaggregated Databases》,讲了讲存算分离数据库的一些设计点,以及这些设计点的带来的效果。
周末有时间简单读了读,也引发了一些思考,这里就简单提一些我个人认为存算分离数据库的一些设计点吧。这里整体写的比较琐碎,可能后面会再写一个更加体系化的文章,提高下阅读体验。
论文整体的组织形式还是可以的,这里就按照他的思路来讲一讲,在设计存算分离数据库的时候,要回答的一些问题:
* 首先,软件架构的演进,为什么从单一的宏内核转化成了分离式的架构,这种存算分离的架构的优势是什么,劣势是什么?
* 其次,针对上述存算分离架构的劣势,大家的解决方案是什么?
* 比如各大厂商大部分都选择了Log-as-the-Database的技术方案,那么Log-as-the-Database可以带来什么优势?
* 同样的,在存算分离架构下,多个计算节点共享数据副本,会带来哪些问题,以及如何解决?
设计点
存算分离其实有很多种,个人感觉说的模糊一点,从单一的宏内核拆分开,就是分离式软件架构了,其中如果稍微把存储和计算拆的开一点,就已经算是存算分离了。这里具体拆的有多细其实还是有多种不同的设计的:
* 拿Aurora这一系列看,PolarDB是shared-disk,磁盘层没有数据库内核相关的逻辑,而Aurora则是把RedoLog的重放和磁盘层放到了一起,然后上面计算层放到了一起。
* 往早点看,RDS部署到EBS上是不是也算是存算分离。
* 再早点,GFS/BigTable这套,基于LSM的引擎和Append Only Storage System分离,也是。
这里无非是视角的问题。与之类似的也有shared-storage/shared-nothing之分,就不多说了。
存算分离的主要优点就是拓展性强,既然大家软件都是分离开的,如果哪一层/哪一个组件出现了瓶颈,那么独立去拓展/修复他就好了,不需要影响其他人。
比如使用RDS的早期,可能发现单独一块本地盘无法存下所有的数据,所以可以利用云存储的能力,把数据库部署到EBS上,也就是所谓的Remote Disk架构,从而获得更强大的存储能力。
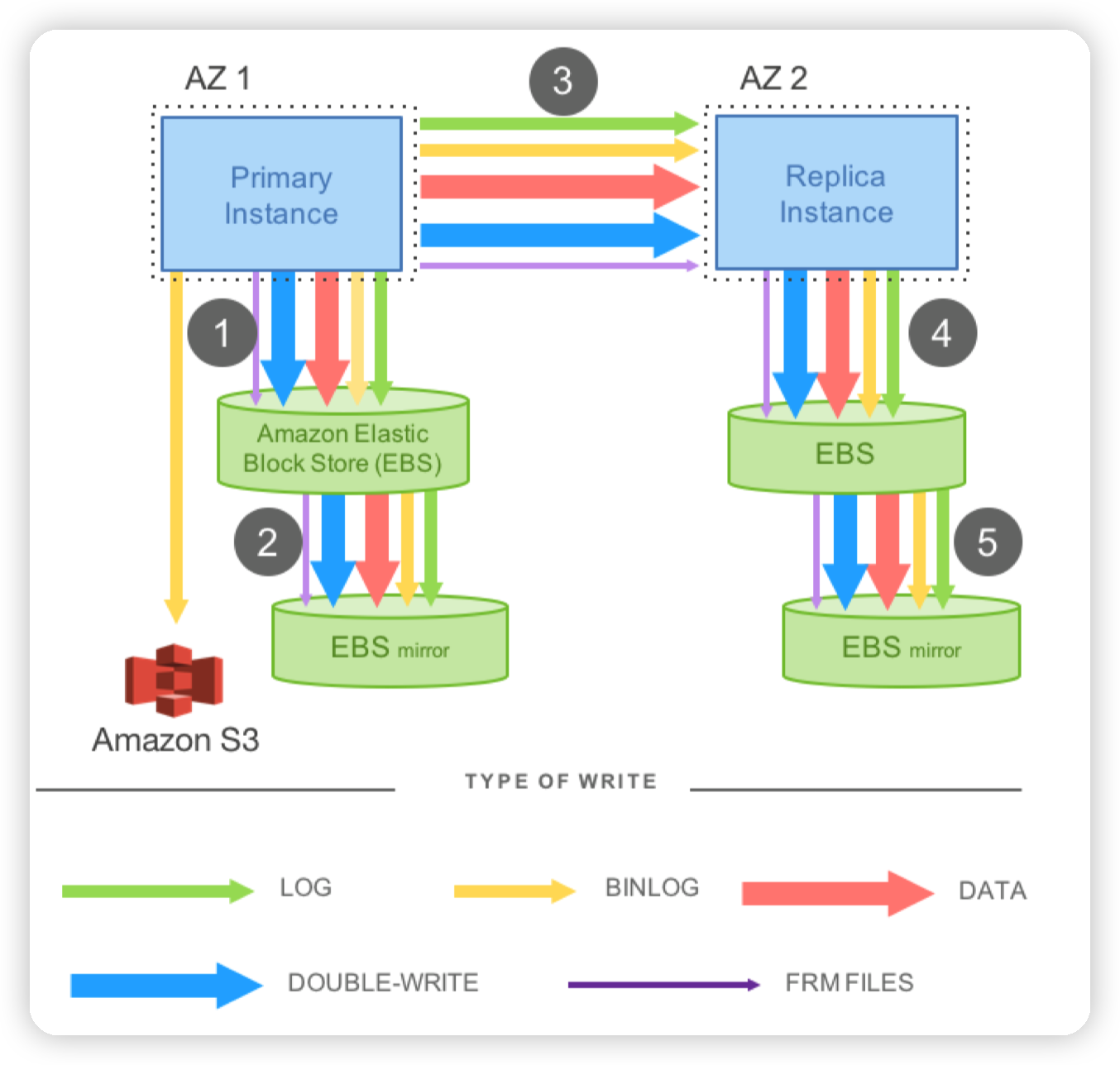
然而在一般的部署模式下,为了提高服务的可用性,数据库都会有从库来跟进主库的变更,从而在主库挂掉的时候及时成为主库,继续提供服务。这种部署方式就会带来两个问题:
* 如果有3AZ的复制,底层存储是AZ内的3副本复制,那么总的存储空间就会来到原来的9倍
* 同样的,存储空间的放大必然也伴随着写入的放大。此时就会导致网络的带宽陷入瓶颈。
* 实际上,即便是没有AZ之间的部署,单纯的使用Remote Disk,因为网络的延迟等问题,也很容易导致性能出现大幅度的下降。(paper中有evaluation)
此时为了解决这个问题,Aurora的SharedStorage的设计就出现了。SharedStorage的设计可以降低副本的存储数量,通过让所有的计算节点共享相同的数据副本,可以减少需要存储的数据量,以及写入这些数据所占用的网络带宽。
。。。比较尴尬的是写到这里有点不太想很正式的写了,这里随便提一些后面写正式文章需要注意的关键的点吧,避免一些思考忘掉:
- 存算分离的优势不仅是可以独立扩容,还有机型上的差异。存储类机型瓶颈在磁盘和网卡,就不会放很多的CPU/Memory在上面,与之对应的,一些内存型机器目的不在于存储数据,而是提供高性能的服务,比如做计算/缓存,那么就不需要很多盘。
- shared storage相对于shared disk来说,另一个关键的点是将Page语意的存储分离出去了,那么在计算层的恢复就不需要走传统数据库的Redo流程(即任何时间都可以认为Page已经写完了,不需要Recover,那么唯一要做的就只有Undo而已)
- shared storage的一个劣势在于软件架构更加复杂一些,存储层要负责重放Log,以及存储数据,部分系统可能又把这里做成一个无状态的服务,然后把磁盘的能力下放到类似WAS的系统中。否则resource disaggregation无法做到那么好,可能会有资源瓶颈问题。
- shared storage/disk的做法都对RO节点有一些冲击:
- 和shared nothing那套不同,shared nothing基本不会对数据库内核有什么逻辑上的冲击。都是在外层做的复制。而shared storage这套直接把数据库内核劈开,让存储的数据在上层不感知的情况下发生动态的变化。
- 从RO节点读请求的视角来说,要保证的无非就是两点,一个是多个Page之间的原子读,比如同时持有多个Page锁,进行读取,最经典的case就是SMO了,第二个则是日志之间的依赖,比如Innodb中,回放了PrimaryIndex的写入之前,必须回放UndoLog的写入。这一点其实也可以通过原子读来解决,不过为了避免持锁太久,以及考虑到Innodb的实现,我们还是分开看。
- 单线程回放的话,考虑mtr级别的上锁就行了,整体比较简单。
- 多线程回放的话,需要考虑page之间依赖的问题,以及原子读的问题。
- page之间依赖的话,不太清楚其他人具体怎么做的。
- 原子读的话,主要就是btree结构的一致性了,这种就需要一些特殊的探测手段。比如Socrates中提到了,他们的Btree是允许在结构持续变化的时候进行读取的,Blink-tree其实就是一个类似的手段。
- 还有一种读的方案,比较直观,就是上述的问题来自于并发更新,那么我读的时候直接锁定一个LSN,所有的page都读这个lsn对应的版本,此时就是一个数据库的快照了。
- 当然这种做法问题比较明显,就是缓存中需要处理不同版本的page,开销整体也大一些。
- 上面说的都是RO全缓存的情况下的处理方案,在不全缓存的情况下,还需要处理RW/RO之间的lag,比如RW写入了新版本的数据,RO可能还没有来得及回放对应的日志,就从存储节点上读到了一个比较新的数据,这个问题也叫做future page的问题。
- 这个问题的处理方法也很多,其中,如果数据库本身不依赖Page原子读这个性质的话,即每次读取一个page的时候,都是用的当前RO所回放的最新的Page,那么future page的问题,和读一个page,然后log applier快速回放,读下一个page读到比较新的page则是一个问题了。此时就可以用相同的方法去做处理。
- 还有一个相关联的问题是,为什么读取Page的接口是GetPage@LSN,每次读最新的有什么问题?
- 这里其实也和实现关联比较大,再单独讨论吧
- RO上还有一个优化是允许换出脏页,也涉及到一些细节的处理。
- 另一个优化则是,为了避免落后的RO影响存储节点的checkpoint,可以通过存储多版本的Page来优化回放速度。这个就是做物化了。大家做的方案应该基本也类似。
- RO上还有一个需要提的是事务相关的同步,毕竟没有了事务锁/RW上的一些内存操作了,只有log同步过来,所以为了支持RO上的事务语意的读取。
- 要么只依赖数据,不依赖锁,对于innodb来说,只提供RR/RC,不提供serializable。注意readview也是需要单独处理的。
- 要么同步上锁操作,目前应该没人这么干。
- 要么改并发控制协议,比如读推高readts,然后持久化,也没人这么干。
- 应用log is database之后,优化网络带宽后,数据库的吞吐主要来自于两个点了:
- 写操作写wal的延迟,优化思路是拆分出log store,然后优化日志的写入性能,比如写三副本内存,或者是写pmem
- 单写入节点的瓶颈,最近各个厂也都发了相关的paper,多主架构。
目前想到差不多就这点,后面有多的再说。

文章评论