背景
- 最近微软开源了GraphRAG的实现,这里来介绍一下GraphRAG相关的技术。
RAG
RAG(Retrieval-Augmented Generation)技术用于将信息检索的技术和大模型相结合,用来克服大模型的的静态限制,使其能够动态地集成来自外部信息的最新数据,从而提高其输出结果的准确性和可靠性。具体来说,RAG 旨在解决以下三个关键问题:
- 领域特化的知识问题
- LLM 通常使用广泛而通用的数据进行训练,以最大限度地提高其适用性和可访问性。然而,这种方法导致 LLM 在特定领域的表现往往不尽如人意。
- RAG 通过检索与查询相关的专门信息,可以有效地解决这一问题,使 LLM 在特定领域的性能得到显著提升。
- 信息更新问题
- LLM 的训练数据通常是静态的,这意味着它们无法获取训练之后产生的最新信息。
- RAG 可以实时检索来自外部数据源的最新信息,使 LLM 能够及时更新其知识库,并提供更准确和相关的回答。
- 幻觉问题
- LLM 有时会产生看似合理但错误的回答,这种现象被称为“幻觉”。
- RAG 通过检索来自外部数据源的真实信息,可以有效地减少幻觉现象的发生,并提高 LLM 输出结果的可靠性。
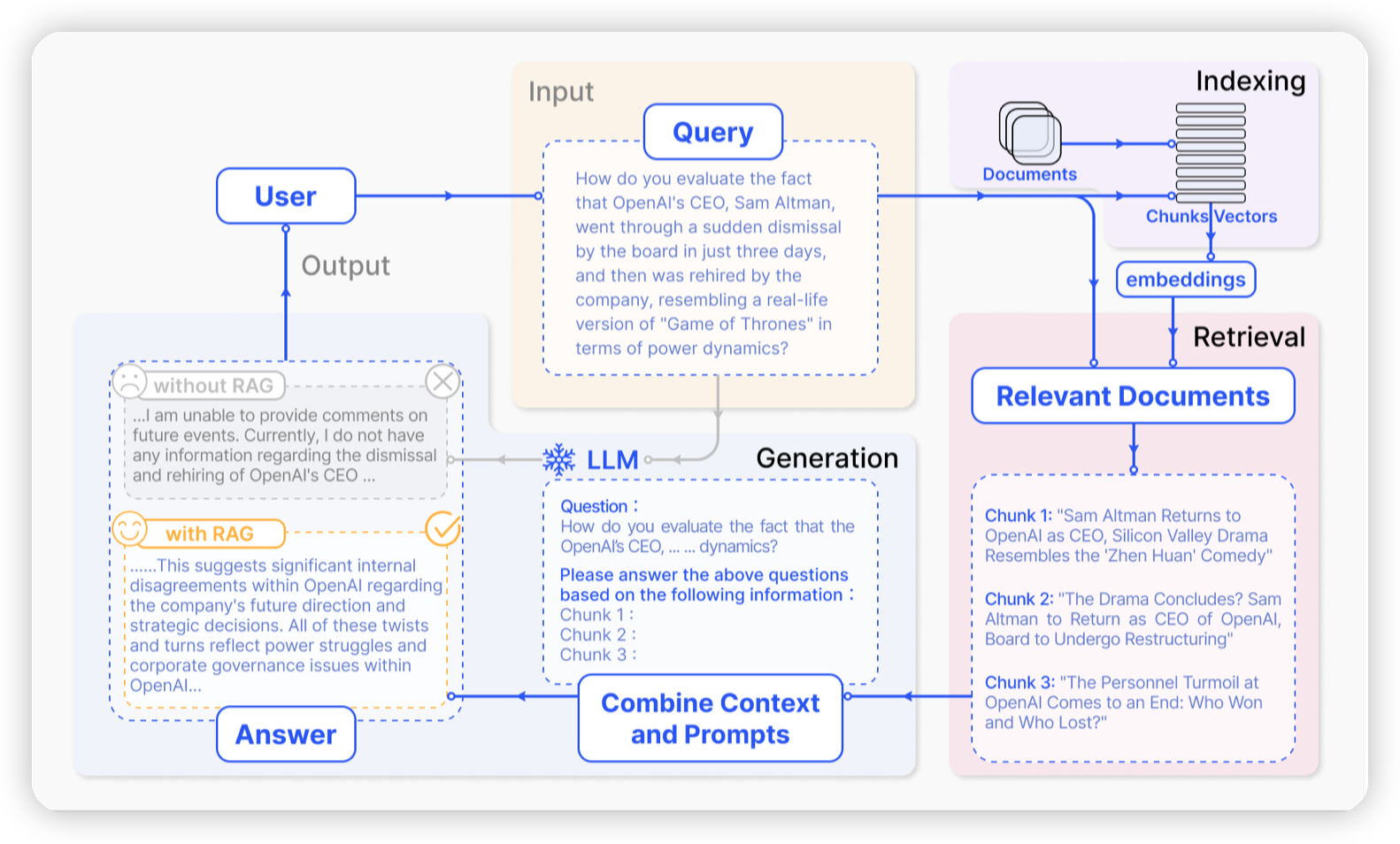
- RAG的基本流程可以分为3个阶段:
- 索引:
- 创建一个外部数据源的索引,用于检索相关信息。
- 目前比较常用的方法是生成文本的embedding,从而提高检索的效率和准确性。
- 检索:
- 根据用户查询,从索引中检索出与查询相关的文档。
- 检索的方法有多种,对应到上述生成文本embedding的方法,就是通过向量近似搜索找到相关文档。
- 生成:
- 将检索到的文档和用户的查询结合起来,使用LLM生成最终的答案。
- 索引:
RAG的缺陷
之前有研究[Seven Failure Points When Engineering a Retrieval Augmented Generation System]总结了RAG的若干个问题,因为目前模型以及RAG框架的迅速发展,部分问题已经得到了解决。不过目前常见的基于向量的检索方式还有一些问题存在(推荐看看这个文章):
- 向量搜索的可解释性较差,部分时候无法清楚的知道用户的请求和用于回答请求的文档之间的关系。
- 当要求在大型数据集或者单个大型文档上进行整体的总结时,现有的RAG框架表现一般不好。在论文中,这种总结性的问题被称为QFS(query focused summarization)任务。
- 比如:_
What are the top 5 themes in the data?__/__What is the major conflict in this story and who are the protagonist and antagonist?_
- 比如:_
GraphRAG
Structured data, such as knowledge graphs (KGs), provide high-quality context and mitigate model hallucinations.
- 目前业界关注度比较高的一个方向就是GraphRAG,使用图相关的技术来提高检索数据的质量以及准确性,比如基于知识图谱来提供高质量的上下文,从而提高LLM回答问题的质量。
Knowledge Graph-Enhanced Question Answering Pipeline
论文[Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering]
NebulaGraph[https://www.nebula-graph.com.cn/posts/graph-rag-llm]
Neo4J[https://neo4j.com/developer-blog/knowledge-graph-rag-application/]
DBGPT[https://www.cnblogs.com/fanzhidongyzby/p/18252630/graphrag]
上述系统都是使用了知识图谱来强化上下文检索的质量。

GraphRAG的基本流程为:
- 索引:
- 通过LLM/传统的NLP技术从文本中提取实体,关系,以及一些预先定义的属性(如实体关系的描述)。
- 将实体,关系写入图数据库。
- 检索:
- 通过LLM提取查询中的关键词。并在向量数据库中检索相关的实体。
- 基于相关的实体,通过Text2GQL等技术生成图查询语句,查询图数据库,提取子图。
- 生成:
- 将子图使用自然语言进行描述,转化成文本,并作为上下文提交给LLM进行处理。
上述流程中可以发现,GraphRAG的优势在于可以通过图结构保留数据之间的结构化关系,从而可以准确的解释用户提问与LLM回答之间的关系,并且提高回答的质量。
- 比如用户可以知道每一条关系/每一个实体都是从哪些文本中提取出来的,从而确保逻辑的准确性。
Knowledge Graph with Semantic Clustering

为了解决RAG无法回答总结性问题的缺陷,微软的论文[From Local to Global: A Graph RAG Approach to Query-Focused Summarization]以及开源实现[https://github.com/microsoft/graphrag]提出:
- 在数据集提取出来的知识图谱上应用图的社区发现算法(如Louvain, Leiden),来将知识图谱划分为若干个相关的社区,并在此之上使用LLM进行总结,从而得到一个具有总结信息的社区描述。那么总结性质的问题就可以通过这个社区描述来回答。
- 这种聚类的方式带来的另一个好处就是,在回答问题的时候,如果上下文窗口长度不足/希望节省成本,那么可以使用上一层的更加简短的社区描述来提供上下文,而在希望得到更加具体的描述的时候,则可以使用其子社区作为上下文提供给LLM。

- 微软GraphRAG的基本流程:
- Index:
- Source Documents -> Text Chunks:对原始的数据集做切分,切分成若干个文本段。
- Text Chunks -> Element Instances:使用LLM从文本段中提取实体和关系,以及其对应的原始文本。
- Element Instances -> Element Summaries:对实体和关系相关联的原始文本做总结。
- Element Summaries -> Graph Communities:使用社区发现算法(Leiden)生成社区,每个社区有属于自己的实体。这里会递归进行社区发现,从而得到一个多层的图,每一层都是对下一层的总结。
- Graph Communities -> Community Summaries:对每个社区,使用LLM总结其包含的实体以及关系,得到社区的总结信息。
- Query:
- Query有Local Search/Global Search之分,Global Search是回答总结类的问题,而Local Search则是用于回答和某个特定的实体相关的问题。
- Local Search:方法和上面提到的使用知识图谱增强上下文检索的方法相同。同时这里在回答的时候也会引用一些社区总结类的上下文。

-
Global Search:使用之前提取出来的社区总结信息,针对用户的问题提取出若干个关键点,并让LLM进行打分。最后根据分数排序,选择若干个关键点进行最终答案的生成。
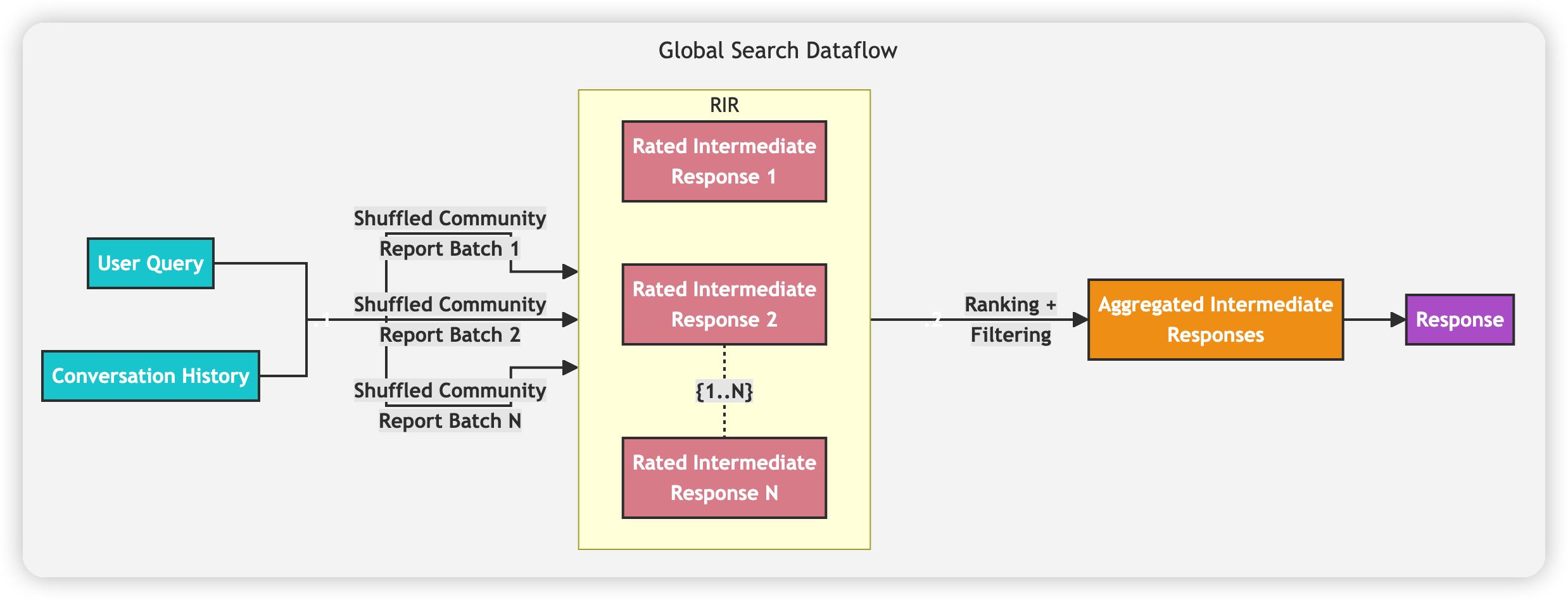
- Index:
通过上述流程可以发现,在对知识图谱进行聚类后,我们可以提取出一些高层次的总结信息,并用以回答总结性质的问题。
- 利用分层的社区总结信息,我们还可以支持更加高效的信息检索。比如传统的RAG在上下文不够的时候,只使用了TopK的文本作为输入,而使用GraphRAG我们可以通过用社区总结信息替换具体文本的方法来节省token,从而降低成本/提供检索质量。
- 图的另一个非常大的优势是对数据的可视化:比如有的时候,用户并不知道要提问什么。而GraphRAG在聚类之后生成的多个社区以及对应的总结信息可以供用户自由探索,在用户找到自己的兴趣点后,可以逐渐进入更深一层的图去检索其子社区,以及对应的描述。通过GraphRAG用户可以对数据集有一个更加直观的认识,并且因为知识经过聚类,浏览起来也更加高效。
-
一个个人的小思考是:
- 有关总结信息,其实可以考虑生成文本Embedding之后做一次聚类,然后在把相似的Text Chunk继续生成总结性质的Embedding,或者放入大模型中生成人类可读的总结。这个方案个人猜测应该也是可以完成总结性问题的回答的。
- 而图在总结信息这个问题中的作用,可能更多的是提供比较好的解释性,以及减少了上下文的噪声(相对于直接喂一堆意义不明的Text Chunk做总结)来提高质量。有了好的解释性,人类可读,自然可以和可视化结合起来,从而对数据集有更清晰的解释了。
Implementation
这里大概讲一下目前开源的实现
Microsoft
https://github.com/microsoft/graphrag
- Index相关
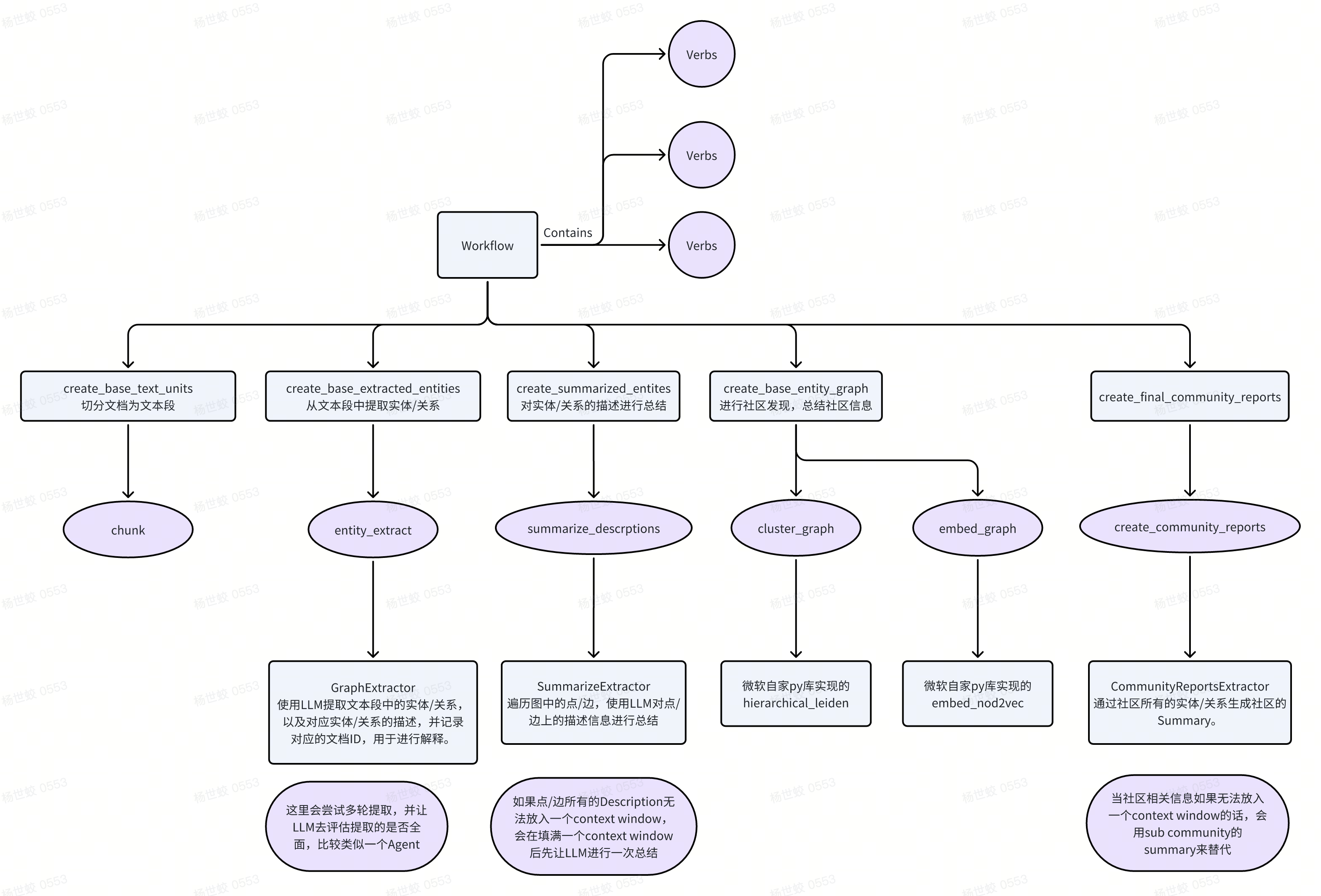
-
Query相关
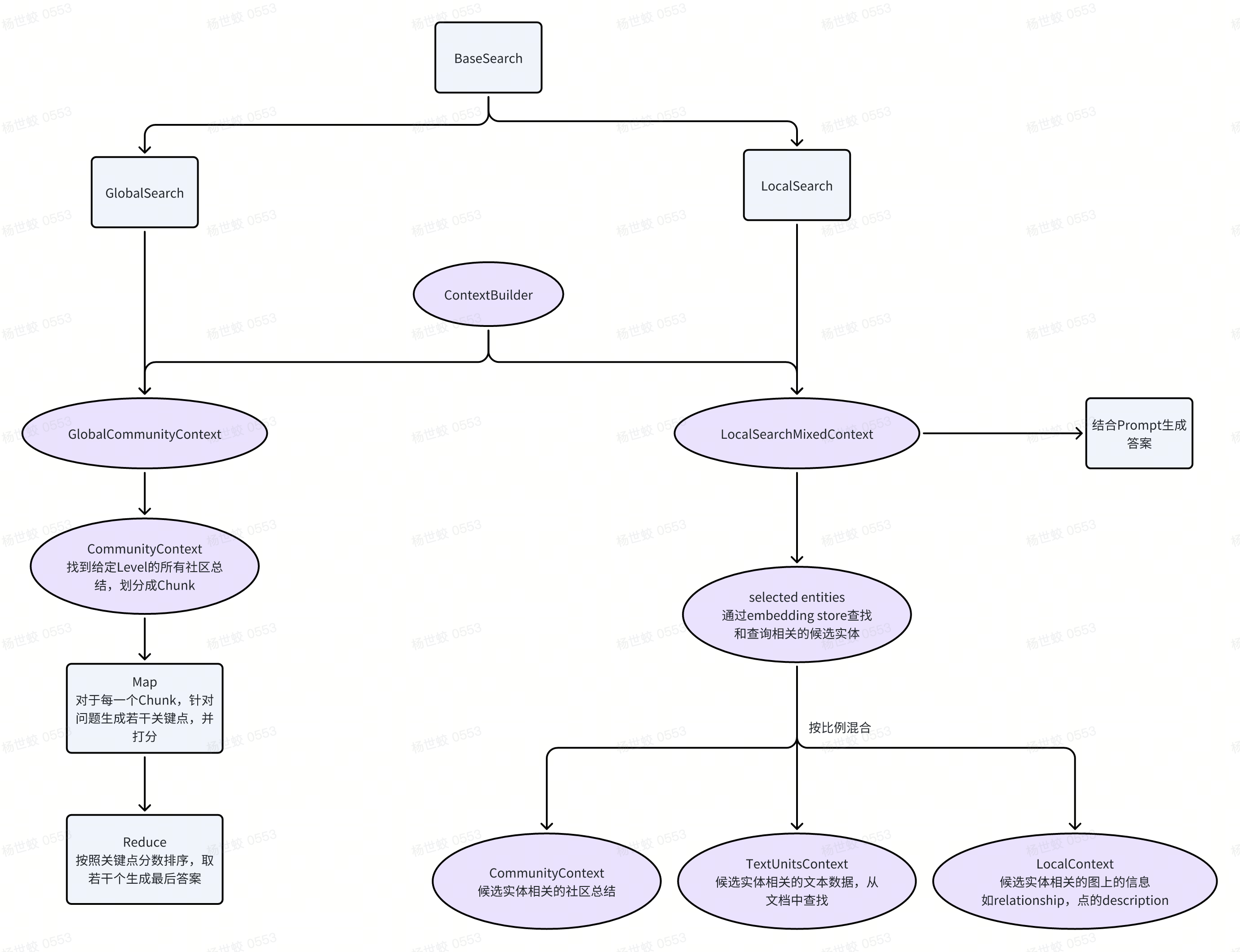
-
一些特别的点:
- 框架核心逻辑比较简单,明白关键的流程(Index,Query)即可。
- 然后可以通过阅读Prompt来明白LLM在这个框架中是怎么起作用的。这个框架中大量的使用了few shot learning,还是值得学习的。
- 代码细节比较多,比如框架会有一些处理屏蔽实体/Doc的逻辑,比如用户发现某些文档有明显错误,就可以告诉框架不去引用对应的文档。
- 在各个调用LLM的地方都有考虑ContextWindow不够用的情况,也都作出了相应的处理,感觉比较务实一些。
可能大家一开始都会比较迷惑这个实体关系是怎么提取出来的,这里我贴一下代码中提取实体用的Prompt:

DBGPT
资料来自于这篇文章:https://www.cnblogs.com/fanzhidongyzby/p/18252630/graphrag

- 通过TripletExtractor提取知识图谱需要的三元组(起点,关系,终点)

- 通过图存储写入三元组,进行图结构的存储

-
查询时,先通过LLM/VectorStore提取请求中的关键词(实体)。然后到图数据库中进行多条查询提取子图。最后提供子图以及用户的查询给LLM来生成最终的答案。
Futures
Visualize
- 上面在介绍微软的GraphRAG中也提到了,图本身的一个性质就是可视化比较好,带有聚类的GraphRAG可以让用户对数据集有一个非常直观的感受,并且根据兴趣探索起来也更加方便。个人感觉这个是一个非常吸引人的点。
Cost-Effective
- 在微软的GraphRAG放出后,很多人发现GraphRAG虽然效果很棒,但是他太贵了,可能的一点优化方案有:
- 在索引阶段,图谱的提取,数据的总结可能可以通过一些领域特化的模型来进行优化,降低成本。这篇文章也提到了类似的思路[https://www.cnblogs.com/fanzhidongyzby/p/18252630/graphrag]。
- 在查询阶段,通过Agent/一些别的手段使用Graph/Vector进行混合查询,这篇文章[https://gradientflow.com/graphrag-design-patterns-challenges-recommendations/]中也提到了类似的方案。
Incremental Updates
- 目前开源的GraphRAG的框架是不支持增量更新的,每次都是全量重新生成,不太便于落地。
- 其中实体信息提取/总结这块可以增量进行。
- 社区发现需要增量进行,不清楚是否有成熟的算法。
- 生成社区后,社区的总结需要可以增量进行,这里通过LLM做应该就可以。
Related Works
-
这篇文章主要关注的是工业界实现的GraphRAG,学术界也有一些其他的GraphRAG相关的研究:
- Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
- REASONING ON GRAPHS : FAITHFUL AND INTER PRETABLE LARGE LANGUAGE MODEL REASONING
- 这些因为看起来比较像是Agent做的事情,我也没有很细的关注了。
Reference
https://www.cnblogs.com/fanzhidongyzby/p/18252630/graphrag
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Seven Failure Points When Engineering a Retrieval Augmented Generation System
https://gradientflow.com/graphrag-design-patterns-challenges-recommendations/

文章评论