Introduction
WAS对外提供的接口:
* Blob,用户文件,比如存视频/图片什么的
* Table,存储结构化的数据
* Queue,用来传递消息
一些关键的feature:
* Strong Consistency,这里他主要是说一些分层的思想,后面具体讨论
* Global and Scalable Namespace/Storage,全局的Namespace,WAS是为了global scale而设计的,所以不只是考虑了单AZ/Region
* Disaster Recovery,跨越DC的数据存储,这个目前看是比较常见了
* Multi-tenancy and Cost of Storage,多租户的好处:
WAS combines the workloads of many different customers with varying resource needs together so that significantly less storage needs to be provisioned at any one point in time than if those services were run on their own dedicated hardware.
Global Partitioned Namespace
感觉有关元数据这块,大家都是希望搞一些Scalable的设计,避免出现Master的瓶颈。
* Workload产生了变化,早期GFS没有这样搞是因为一个Master足够简单且够用
这里介绍了WAS访问一个文件的URI:
http(s)://AccountName.<service>1 .core.windows.net/PartitionNa me/ObjectName
* AccountName是用来定位Primary storage cluster的,是一个DC内的集群
* PartitionName是用来做分片的,这里的API个人感觉有点暴露细节了
* ObjectName是在确定了Partition后,每一个具体的数据对象。WAS提供一个Partition下的事务
- Blob,实际上只有Partition这一层,没有更加细分的Object了。说明不存在Blob/Blob的事务,以及Blob本身没有什么聚合规则,是Account下铺平的一层
- Table,每一行数据的PrimaryKey都有PartitionName和ObjectName,有点Table-SubTable-Row的感觉
- Queue,队列本身的名字是PartitionName,然后每一个Message都有一个ObjectName
High level Architecture
- Windows Azure Fabric Controller,是Azure Cloud platform下的一个统一的资源管理平台,负责资源分配,部署/升级,以及管理云服务。这里他们的物理机应该也是用的这个平台。会给WAS提供network topology, physical layout以及hardware configuration。(这个physical layout是啥,感觉和network topology是一个东西)
- WAS则负责在Fabric Controller之上,管理数据在磁盘之间的放置以及复制,以及load balance

* Storage Stamp:
* 由若干个Rack组成的集群,每个Rack都是有冗余的network/power的独立的故障域。
* Storage Stamp的使用率一般会被控制到70%,避免在其他rack跪掉的时候没有空间做复制。并且磁盘的outer track有更好的吞吐和寻道时间(具体我也不是很清楚)
* 使用率比较高的时候,会使用Inter-stamp replication来控制水位。(没有无限扩容storage stamp的原因可能是有什么瓶颈)
* Location Service
* Location Service负责管理account到storage stamp的映射。是storage stamp级别的master,不过account的数量应该比较多,不知道localtion service有没有做一些拓展的设计。
* Location Service也负责storage stamp之间的local balance
* 在Location Service移动account之后,会更新DNS来把请求路由到新的Stamp的位置上
Storage Stamp内的3层:
* Stream Layer
* 是分布式文件系统层,对标的是GFS。每一个文件被称为stream,内部是由chunk组成的列表。
* Partition Layer
* 对标BigTable
* 负责理解高层数据抽象(Blob,Table,Queue),并将他们转化成对Stream Layer的请求
* 提供object namespace
* 处理事务语意,以及缓存数据
* 对stamp内的数据对象根据PartitionName做Range partition
* 还有一点特殊的是他说PartitionLayer和StreamLayer是Colocate的,看起来并没有做的那么存算分离。存储节点的机器也有PartitionLayer来提供服务。
* Front-End Layer
* 负责做一些鉴权,路由请求到PartitionLayer的工作
* 也可以直接访问StreamLayer,(猜测是缓存一些stream layer的路由信息,直接访问storage node),以及缓存一些经常访问的数据(感觉用处不大,一致性还不好保证)
两个复制引擎:
* Intra-stamp replication(stream layer):保证数据在一个stamp内是持久的,只要这个stamp不挂,数据就还存在。面向的故障主要是磁盘/节点/Rack故障。Intra-stamp replication在写入的关键路径上,即写3副本都成功后才会返回成功
* Inter-stamp replication(partition layer):这一层是用来做stamp之间的数据复制的,是异步复制,用来保证stamp挂掉后数据不会丢失,并且也会用来处理Account在stamp之间的迁移。复制的粒度是object level。
* 使用两层复制的原因:
* Intra-stamp replication用来对抗硬件的故障,在大规模的分布式系统中是比较常见的。而Inter-stamp replication是用来对抗区域级别的故障的,一般并不常见。所以一个是同步,一个是异步复制
* Intra-stamp replication在写入的关键路径上,需要尽可能的做到低延迟。而Inter-stamp replication则是异步复制,需要在网络带宽和复制Lag之间做权衡
* intra-stamp replication可以让元信息限制在一个storage stamp的级别上,从而可以让元信息被缓存到内存中
StreamLayer
stream layer是最关键的地方了,提供了类似GFS的接口,写入是AppendOnly的,用户操作的是一个一个的stream(即append only file)。一个stream是由extent组成的列表,而一个extent则是一系列的block。

* 图中是stream的组成,其中只有最后一个extent是unsealed,其他的都是sealed,所以只有最后一个extent是可以写入的
- Block:block是最小的读写单元,最大是4MB。每次读取的时候要按照block来做整块的读取来做checksum的校验
- Extent:extent是stream layer中复制的单元,即是一个单机/分布式的概念。每个独立的存储节点对外暴露的应该是读写extent的接口,extent内部到磁盘这一层,是block的概念。这里他说一个extent是存储到了一个NTFS的文件中。一般的extent的大小是1G。
- Streams:stream是由extent组成的列表,可以支持stream之间的concatenate。
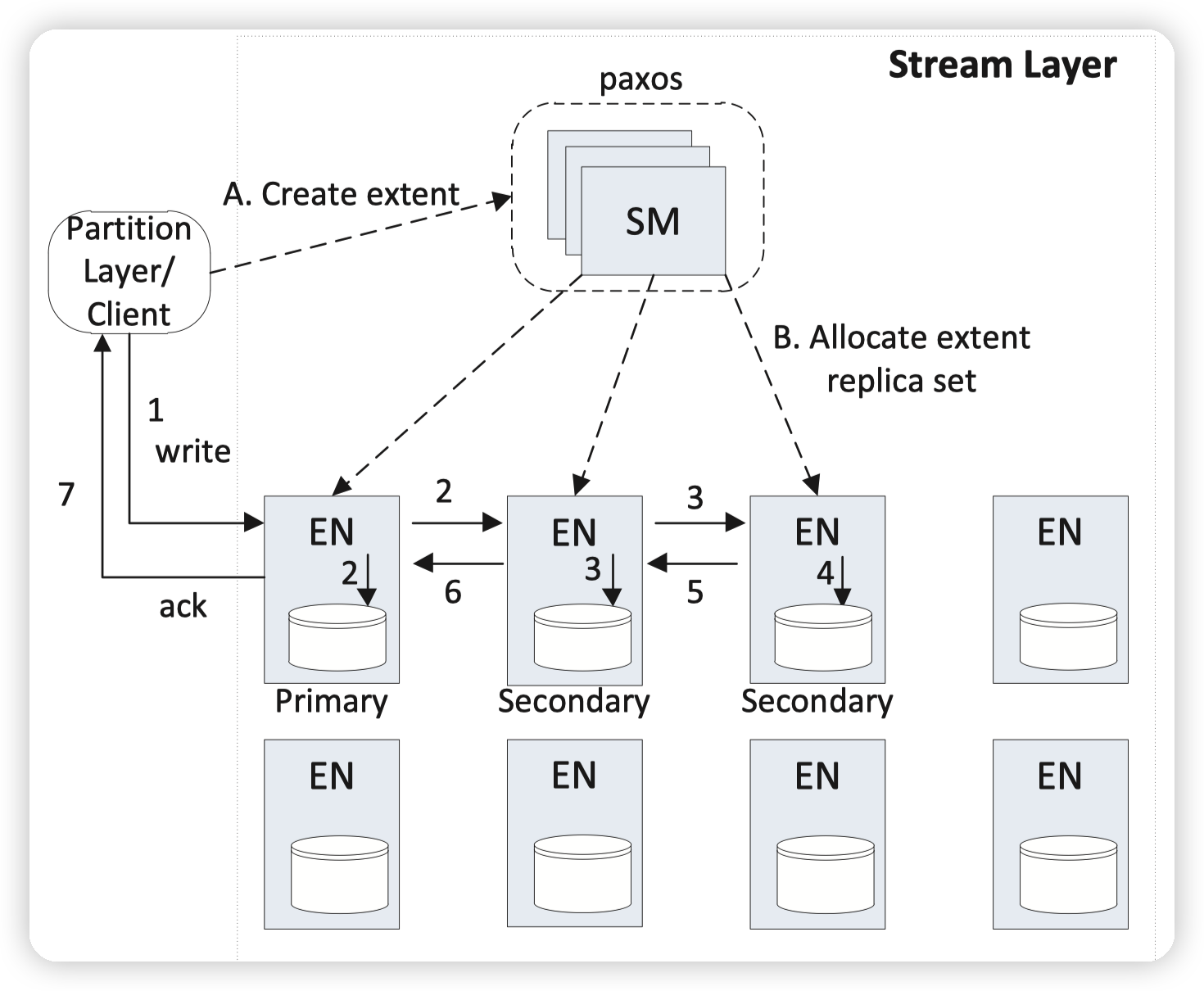
SM是StreamManager,就是这一层的Master,负责:
* 维护Stream的Namespace
* 监控EN(Extent Node)的状态
* 分配Extent
* 做re-replication,即补齐副本,以及GC不需要的数据
* SM会周期性拉取EN的extent列表,并决策是否要做补齐副本或者删除无效数据
* 触发后台EC的任务
Stream支持一些原子写入的能力,但是对于一些超时的情况来说,client要么执行重试,要么是将extent做seal。
* 所以如果用户做重试的话,需要能够处理重复的数据。
* 有一个额外的点是WAS需要能够保证多台机器的原子写入,而不只是单机的原子写,这实际上隐含了一种复制状态机的感觉——写leader,复制到其他的从节点上。
* 与之对应的是pangu等系统,直接从SDK侧写入,写失败就需要做seal + create
对于stream layer,对上层提供的语意是:
* 一旦一次写入回复成功了,那么后续去任意一个replica上做的读取都会读到相同的数据
* 一旦一个extent被seal了,后续读取任何seal的replica都会读取到相同的数据。
Replication Flow
根据图上的内容,在创建Stream的时候,会给第一个extent分配3个replica,并且还会从这3个replica中选择一个primary出来。primary EN是用来负责协调对两个secondary EN的写入。当一个extent是unsealed的时候,他的3个副本的位置,以及primary的位置都是不会有改变的,所以Primary不需要有lease。
* 这里primary不会改变的设计对于处理上面的复制的问题就容易了许多。每次都写primary,然后让primary做一次复制就可以。
* primary负责:决定本次写入的数据在extent中的offset,处理并发的写入请求,将数据和确定的offset发送给secondary replica,并且在3副本都成功后再返回成功。
* 并发的写入会根据offset的顺序做返回。这里并发应该不是多个用户的写入,而是重试的请求/io depth > 1的情况
client会缓存EN的位置,这样后续进行读写的时候就不需要再和SM交互了。
如果在写入的时候,出现了节点的异常,会给client返回失败,此时client会和SM交互,seal住当前的extent,SM再分配新的extent给client。
* 这里的关键在于,当出现节点故障的时候,client只要切换一个extent就可以继续写入了,不会受到影响。
* 对比共识类型的fs,如果有一个节点宕机,还可以提供服务,并且需要增加新的member。如果有两个节点的话,就跪了。这么看这种类型的系统的可用性更好一些?
Seal:
* Seal的流程是,SM会询问3个EN的当前长度,SM会选择他能联系到EN中的最小的commit length,避免因为无法和EN通信导致Seal失败。
* 如果出现了非对称的网络分区呢,比如seal了一个大一点的commit length,此时client去读会发现有一个节点没有数据。此时并没有违法上面说的stream layer的语意,后续应该在seal剩余副本的时候,会给他补齐剩下的数据
* 这里可以体现,他们定义出来的这个语意才是最关键的,划分清楚上下层的职责
* 不过对于上面说的这个case,在iterate stream的情况下,有可能出现问题。(即前后两次iterate的数据不同),这里的解决方法是在读取的时候,client发送一个"check for commit length"的请求给primary EN,来检查3副本的数据是否是一样的,如果不一样,那么就会做seal,并且读取只会读取seal的extent(保证读取到提交的数据)
EC:
* 对于seal的extent,WAS会给这些extent做EC,在提供相同的持久性的情况下,降低空间放大
* EC能够提供更强的持久性的原因在于“不把鸡蛋放在同一个篮子里”,所以当出现一台机器故障的时候,只是相当于丢失了总数据的一个fragment,通过其他的数据就可以恢复回来。这里的核心在于集群中机器同时发生故障的概率是非常低的。
部分读取操作,是可以通过前台做reconstruction,来避免部分机器出现长尾IO的情况
- Journaling
- 每一个EN上都会有一个单独用来写入journal的盘。
- 在写入单个EN的时候,会先把数据按序写入journal的盘,然后再排队写对应数据所在的盘。任意一个操作成功了都会返回成功。
- 这里虽然Extent本身的写入就是sequential write了,还使用journal的原因不是为了提高写入的性能,而是可以避免读流量和写流量出现影响。单独有一个journal盘的好处是可以保证写入的延迟更稳定。不过带来的问题是额外的写放大。
PartitionLayer
- Object Table
- PartitionLayer内部的一个统一使用的结构,叫做ObjectTable,ObjectTable会被动态的划分为RangePartition,并分布在不同的Partition Server上。
- RangePartition就是一段sort key连续的行
- Object Table的实例
- Account Table负责存储在这个stamp内的每个account的元数据
- Blob Table负责存储所有的blob
- Message Table负责存储队列中的所有Message
- Schema Table负责存储所有Object Table的schema
- Partition Map Table负责存储每一个OT中的RangePartition到Partition Server的映射
对于Blob Table, Message Table, Entity Table,他们的primary key是由AccountName, PartitionName和ObjectName组成的
OT的schema支持一些常见的类型,也支持了特殊的类型如BlobType。在存储上,为了避免写放大,会把BlobType的数据单独放到一个blob data stream中,而对于普通的row来说,则是放到row data stream里

PartitionLayer的架构如图:
* Partition Manager,负责切分Partition,以及管理RangePartition到PartitionServer的路由
* Partition Server,负责服务一些RangePartition的请求。所有持久化的数据都被存储到了Stream Layer中。这里处理的就是从上层语意到底层存储的转化,以及一些事务相关的。
* Lock Service,和Chubby一样,负责选主的

因为每个PartitionServer对外提供服务的单位是RangePartition,这里看一下RangePartition的组织形式:
* RangePartition用LSMT来维护持久化的数据
* Metadata Stream负责维护一个RangePartition的元信息,PM只需要提供给PS一个Metadata Stream的名字,PS就可以通过这个Metadata Stream把RangePartition拉起来。里面存储的应该是类似VersionEdit的元信息
* Commit Log Stream就是MemTable的WAL
* Row Data Stream是用来存储row data/index的checkpoint,即SST
* Blob Data Stream用来存储Blob类型的数据
* 后面的是一些常见的LSM的结构,不过在当时11年应该算是比较新的东西了,毕竟甚至LevelDB还没开源
* 然后对于BlobTable来说,commit log stream会存储Blob Data(为了避免多次IO,毕竟是前台写入),在SST中不会存储blob data,而是单独放到了blob data stream中
因为RangePartition是调度服务的单元,为了保证Load Balance,所以需要做一些Merge/Split的操作。
* Split是在单个RangePartition负载过高的时候,可以将其分裂到不同的PS上
* Merge则是为了保证总体的RangePartition的数量不会过多。
* 一般来说,RangePartition的数量要维持在PS数量的10倍左右。
* 过多的话,会导致元数据开销过大,无法fit in memory
* 过少的话,则会导致在PS故障的时候,无法快速的把流量均摊给其他的PS
- Load Balance
- WAS会追踪PS的,txn/s,pending txn count,throttling rate,CPU usage,network usage,request latency以及RangePartition的数据大小
- 如果PS的负载过高,会选择做RangePartition的调度。而如果RangePartition的负载过高,则会触发分裂
- Split
- 分裂会有根据Size分裂,以及根据Load分裂。对于Load分裂的情况,PS会通过Adaptive Range Profiling来选择分裂的Key
- PS在做分裂的时候,比如B -> C, D,会通过StreamLayer提供的特殊命令,浅复制一份B的各份数据给C和D,然后再给C/D的metadata stream上记录他们对应的partition key range
- Merge
- 首先会把需要做Merge的Partition放到一个PS下,比如C/D -> E
- PS会先给C/D打一个ckpt,然后会停流量
- PS把C/D的log stream和data stream连接到一起。这里感觉Log的Layout需要特殊设计一下
- 然后PS在构建E的meta data stream,记录新的partition range,新的log stream的名字,以及新的commit log stream的有效的range。
- 其实感觉比较简单的做法是ckpt的时候就停流量,然后直接concatenate SST
上面也提过了Partition Layer的Inter-stamp replication。用户的写入是有一个primary stamp,以及若干个secondary stamp。
* 在Primary stamp写入并提交后,会做一下异步的inter-stamp replication,把请求发送给另一个region的stamp。(这里没说他们的复制粒度,感觉是基于commit log的位置分配一个id,然后做有序复制容易一些)
* WAS提到他们一般的lag是30s
Workload Profiles
这里给了他们的一些workload,可以看一看:
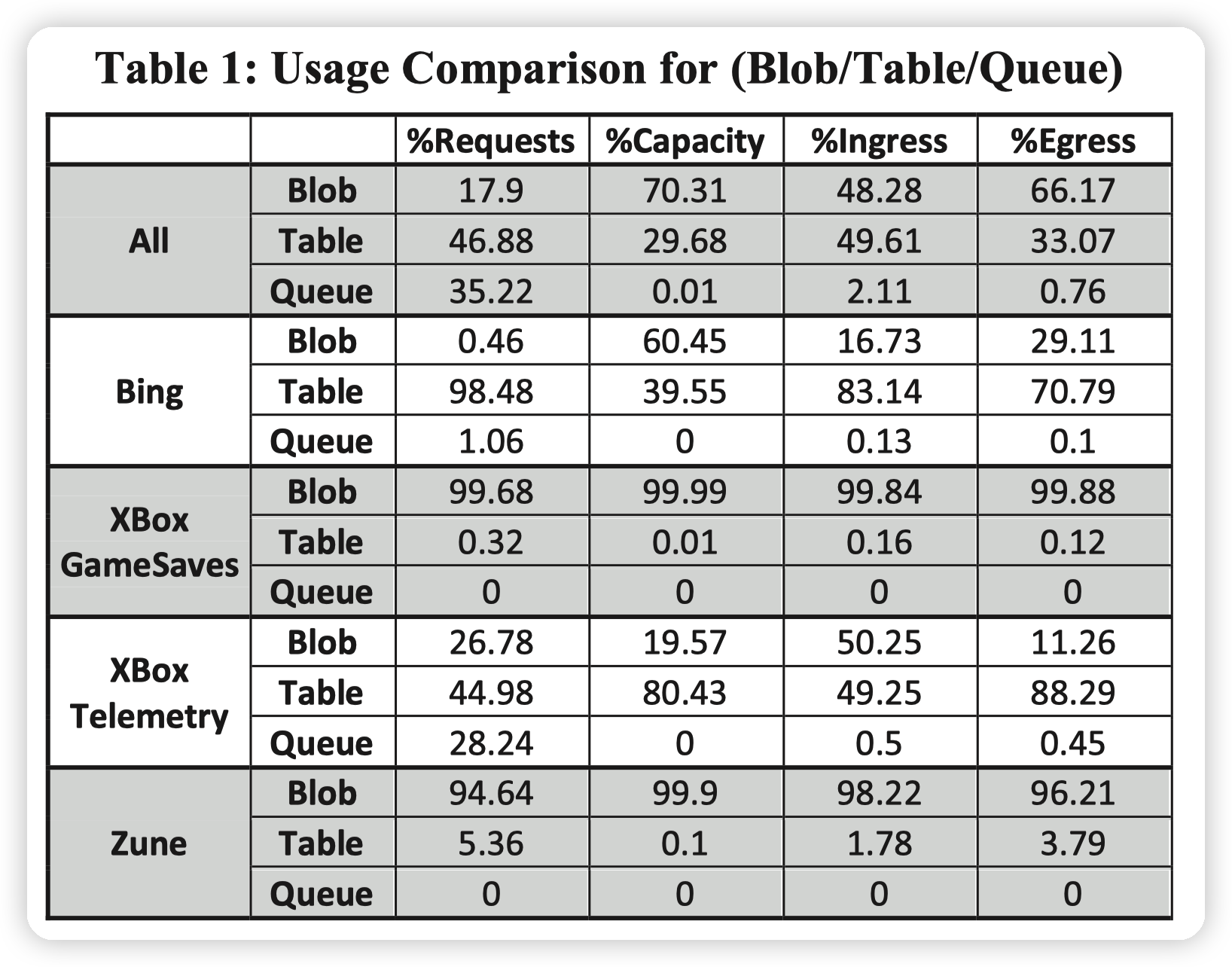
* Bing大多数是结构化的数据,应该是存一些索引什么的
* XBox GameSaves都是用户的云存档,都是不感知格式的各个游戏的存档,所以都是blob
* XBox Telemetry,遥测,不太清楚具体是干啥的,文件主要在Blob中,table里存的是元数据(感觉比例也不太对劲,table有点多)
* Zune是Windows Azure for media file,所以都是blob存储
Design Choices and Lessons Learned
- 存算分离,这里主要说的是ECS和WAS这种的分离,还没到具体WAS内部的分离呢。不过这里已经提出来了resource disaggregation的关键在于bandwidth,所以他们搞了新一代的DC内的网络架构
- Range Partition / Hashing,这里主要是觉得Range Partition对Account级别的隔离做的比较好一些,并且也有更好的局部性。
- 不过Range partition对于顺序写的workload无法很好的做打散。这块就需要用户自己做一些内部的hash了
- Throttling/Isolation,通过Sample-Hold algorithm跟踪topN的AccountName和PartitionName。在PS负载过高的时候可以通过这个值来做限流
- Load Balance,负载均衡的规则比较复杂,WAS引入了一个scripting language来配置负载均衡的逻辑,input是system metrics,output就是做split/merge的决策
- 对于每个Range Partition,用独立的Log stream,而不是像BigTable一样一个PS用一个LogStream。从而可以保证加载Log的时间是隔离的,不会多余的加载其他的Log。坏处自然就是聚合能力差了一些
- Journaling,每个EN有一个单独的Journal Drive,上面也说了,就是为了避免读影响写入。而BigTable为了避免写入尖刺,用了两个Journal log。(写放大都存在,但是在上层用两个Journal感觉整体处理的逻辑会更复杂)
- Append-only System的好处:
- 简化replication protocol,以及失败处理的逻辑。即数据不会被覆盖写,并且一旦发生异常就可以seal extent
- 因为历史数据都保留了,所以提供snapshot更方便,debug更加容易,并且恢复到历史的一致的状态也更加容易
- 使用EC更方便
- Append only的坏处是需要做GC。不过在目前SSD的环境下,底层都是append only了,这一点也就没有劣势了。
> When operating a system at this scale, we cannot emphasize enough the benefit we have seen from using an append-only system for diagnostics and recovery. - End-to-end Checksum,每一步都有checksum,避免硬件故障。并且可以更容易的识别出有问题的硬件
- System-defined Object Tables,使用一个OT来构建其他的组件,可以更好的隔离组件之间的变化,并且对于组件的维护和升级也更加容易。
- 比如内部一个地方的优化,通过优化ObjectTable就可以应用到所有的Table上
- 而用户数据抽象层的变化也不会对内部的结构有影响
- CAP Theorem,这里他说他们通过分层的方式,让StreamLayer支持HA,然后让PartitionLayer支持Consistency,解决的CAP问题。
- 实际上我感觉没有,在出现极端的network partition的时候,首先StreamLayer就无法支持HA了。
- 不过这种分层的思路是比较好用的,因为极端情况的network partition不太可能,但是一般的系统故障是可以通过分层来单独解决的。这样PartitionLayer不用担心数据的持久性,而StreamLayer也不需要关心用户的处理方式来保证强一致
- High-performance Debug Logging
- 高性能的debug log在分布式系统中是非常关键的,可以避免部署特殊的代码或者尝试复现问题。在有详细的日志的情况下,追踪一个bug会变的简单很多。
- Stress-point,就是注入一些错误/延迟,可以尽可能的提前暴露问题
Thinking
一些引出的思考:
* 根据(我自己瞎jb提的)软件演进依赖于硬件演进或负载变化,这里WAS的演进应该属于大类下的从单机到分布式的演进。细节上说,是从GFS提出Append only的后,针对GFS的问题做的优化,即主要是一致性的提升。这里应该算是workload的变化,从不一致变成了强一致,从而简化了上层系统的实现
* 接着上一条说,WAS给出了append-only这套系统是如何提供强一致的语意的。划分清楚一个强一致append only系统要提供什么样的保证。感觉是接口制定的学问。
* 和pangu的对比上,pangu选择了没有leader,那么错误处理的逻辑也就只有seal extent这一个选择,带来的优势是更低的延迟
* 针对问题做tradeoff:
* inter-stamp replication/intra-stamp replication,针对的是不同的问题,自然有不同的解法
* 底层软件栈,IO的稳定性。相较于thoughput,latency是非常重要的一环
* append only的趋势,可能以前是SSD FTL这一层做了append only -> update inplace的转化,既然上层认为append only有优势(或者是为了性能考虑),就可以把这个抽象暴露出去。直到不需要append only的语意的那一层为止。比如这里的PartitionLayer,就不需要依赖append only的特性做什么事情。
* 合流/分流的好处:
* bigtable把所有的partition放到一个流中
* 这里WAS是每个range partition自己来
* OB也做了4.0的log stream合流。目的是减少分布式组件带来的开销
* 从这个趋势上看,可能类似OB这样选择一个中间状态比较好,不过就是又要额外引入一层抽象,其他地方的逻辑也就都需要修改。可能也是一种tradeoff了

文章评论