这篇文章介绍下MongoDB的存储引擎WiredTiger,主要关注WiredTiger作为存储引擎自身的提供的能力。和MySQL Server和Innodb的交互不同的是,WiredTiger针对MongoDB做了很多定制化的功能,导致他本身提供的接口看起来非常的奇怪,所以后面也会有一篇文章来介绍一下MongoDB和WiredTiger交互的逻辑。
因为我看的时间并不算长,有些也是结合文档一起理解的,不免出现一些错误,如果出现,还请大佬们帮忙指正。
Overview
WiredTiger是一个高性能,多核拓展性强,支持事务的存储引擎。有一些本篇文章会比较关注的设计点:
- 通过MVCC支持读写不阻塞的事务,支持到最高SI隔离级别
-
支持checkpoint-level以及commit-level持久性,并且始终可以保证数据的一致性(快照语意)
-
Multi-core Scalability, 通过各种技术实现多核可拓展性(Hazard ptr,lock free的读写,Pointer Swizzling等),在内存内的读取不需要任何同步手段,写只需要一次Read Lock
-
变长数据页,从而避免Btree Page的空洞导致的空间放大以及带宽放大
-
Named Checkpoint,显示的创建全局一致的快照,以供长事务的使用
还有一些本篇文章不会特别关注的设计点,主要是各种功能上的支持:
- 通过溢出页来支持超大KV的存储(最高4G)
-
Transactional Fast-Truncate,WiredTiger支持事务语意的Range Delete,并且对于完全包含在Range内的Btree Page,会做Fast Delete
-
不同数据源的支持,WiredTiger支持各种云上存储,如S3, Azure FileSystem
-
LSM Tree,WiredTiger还支持使用LSMT来存储数据
-
Column Storage,支持在Btree的内部以列存的方式组织数据,对外通过Column Group来定义列存的存储方式
-
Backup,支持全量Backup/Block Based增量Backup/Log Based增量Backup
-
Bulkload,批量写入
-
各种细化的调优,如Mutex的选择,Memory Allocator的选择,Compressor/Encryptor
-
支持application-level timestamp,整个系统可以通过上层设置的timestamp来驱动(这也是WiredTiger复杂且特殊的一点)
Interface
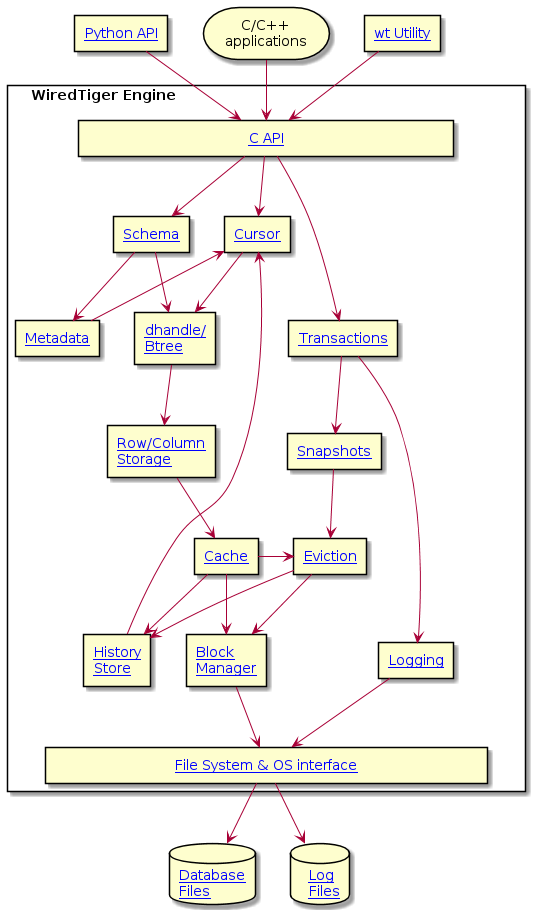
WiredTiger是C编写的存储引擎,对外的接口自然也是通过C来暴露
WiredTiger的数据库整体是通过WT_CONNECTION来表示的,每个访问数据库的线程都需要显示的创建一个WT_SESSION,在Session的上下文下,可以修改数据库的元数据,创建cursor进行读写,创建和提交事务,以及创建checkpoint等。
这种所有访问数据库的操作都通过显示创建Session来表示的好处就是我们很容易就可以知道其他Session在干什么,比如是在访问那个数据/事务ID是多少,从而可以完成一些去中心化的操作

- 比如在尝试换出一个Page的时候,为了避免中心化的buffer pool带来的开销,这里会检查其他Session pin住的page是否有当前Page
-
再比如,在开始事务的时候,不是将自己的事务ID加入到全局的状态表中,来维护ReadView。而是直接将事务ID保存到Session上下文中,其他事务在获取快照时就可以遍历一遍所有的Session上下文来构建ReadView
这篇文章我们主要关注有关WiredTiger的2个点:
- 看WiredTiger的写入/落盘流程,看和ARIES的不同之处
-
看WiredTiger高性能的读写基石,如何做内存中的无锁读写,PointerSwizzling,以及EBR/Hazard ptr等技术的应用
Transaction
WiredTiger和一些其他存储引擎不同的是,并没有使用ARIES来作为恢复的算法,而是对事务系统有比较深的依赖。
WiredTiger在最初也是通过ReadView做可见性判断的,每个事务有自己的事务ID,事务开启的时候会读取当前所有活跃事务ID构建Snapshot。
后面在作为MongoDB的存储引擎后,为了满足Global Consistent Snapshot等需求,WiredTiger也支持基于Timestamp进行可见性判断。Timestamp,以及WiredTiger和MongoDB的交互这一块后面会单独讲到,目前我们先只关注WiredTiger自身的逻辑。
简单介绍下WiredTiger的写入流程:

WiredTiger的日志是逻辑日志,在事务执行过程中,对于Page的修改是直接写内存,并且不会写Page级别的RedoLog。而是将本次变更缓存到事务粒度的Buffer中。在提交的时候,一把将本次事务写入的所有变更都写入到日志中。
这种逻辑日志就对Btree的Checkpoint本身有一定的要求,否则就可能出现重复重放/漏重放的问题。WiredTiger的做法Checkpoint会作为一个事务,持久化一份带有快照语意的数据到磁盘上。恢复的时候按照日志的顺序从这个快照上回放日志即可保证不重不漏。
Btree
WiredTiger的数据可以由Btree组织,也可以由LSMT来组织,目前我们主要关注Btree。其Btree的特点主要有:
- 支持不同类型的页内数据组织形式,RowStore和ColumnStore
-
支持Fast Truncate,给定Range可以快速从Btree中删除这个Range的数据
-
内存中页的结构和磁盘上页结构不同(对比于Innodb),有显示的序列化/反序列化过程
-
Btree只有分裂,没有合并,并且分裂是会延迟到刷盘时再分裂
-
不存在单层Btree,创建出来的时候RootPage都是InternalPage
-
组织形式是B+Tree,但是不存在兄弟之间的指针
-
每个子节点也维护了其父亲节点的指针
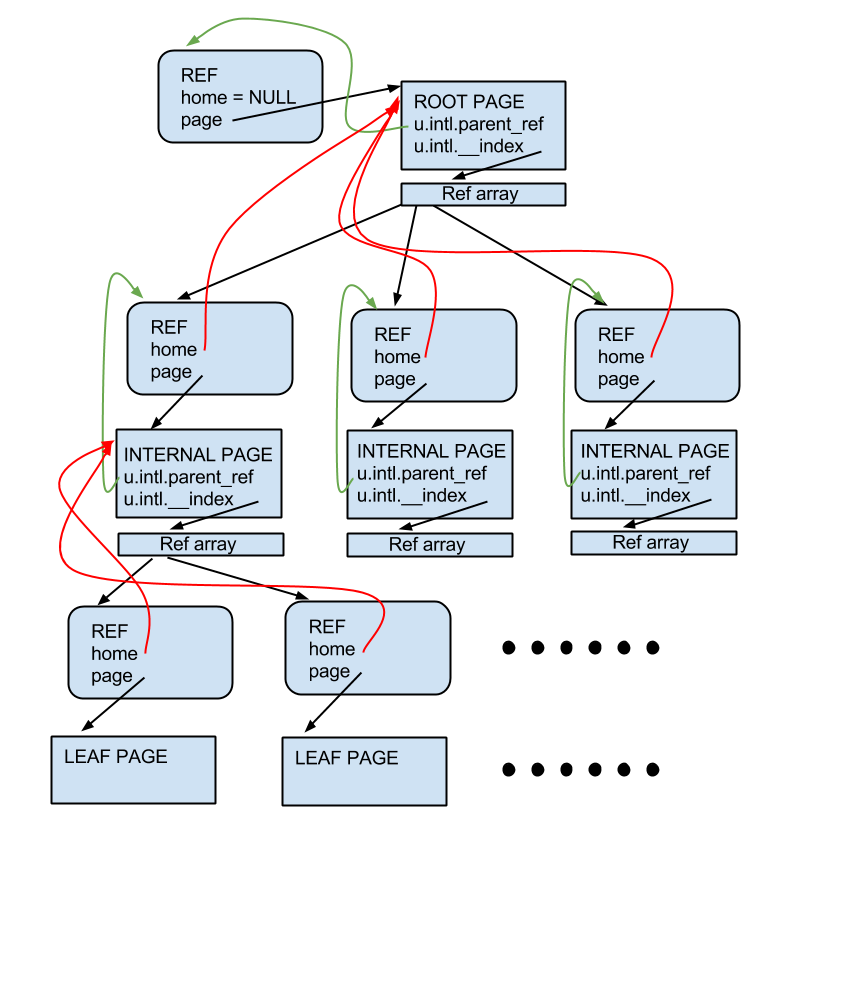
Page
WiredTiger的InternalPage和LeafPage在内存中的组织方式是不同的:

对于InternalPage来说,存储的是由WT_REF结构构成的数组,每个WT_REF都指向一个子节点。WT_REF有两个最基本的状态,分别表示当前指向的这个子节点是在内存中,或者是在磁盘上,对应的会记录这个子节点的裸指针,或者是磁盘上的地址。这里WT_REF就是WiredTiger实现PointerSwizzling的核心结构。
在做Btree下降的时候:
- 如果发现目标的子节点的状态是不在内存中,就会做把具体的Page从磁盘上捞上来,然后将对应的
WT_REF的状态修改,并记录内存中的指针。 -
如果目标的子节点在内存中,则会直接跟着裸指针访问到子节点,没有BufferPool等组件带来的同步开销。
WT_REF这里还有一些额外的状态,是用来做SingleFlight的逻辑,避免重复IO
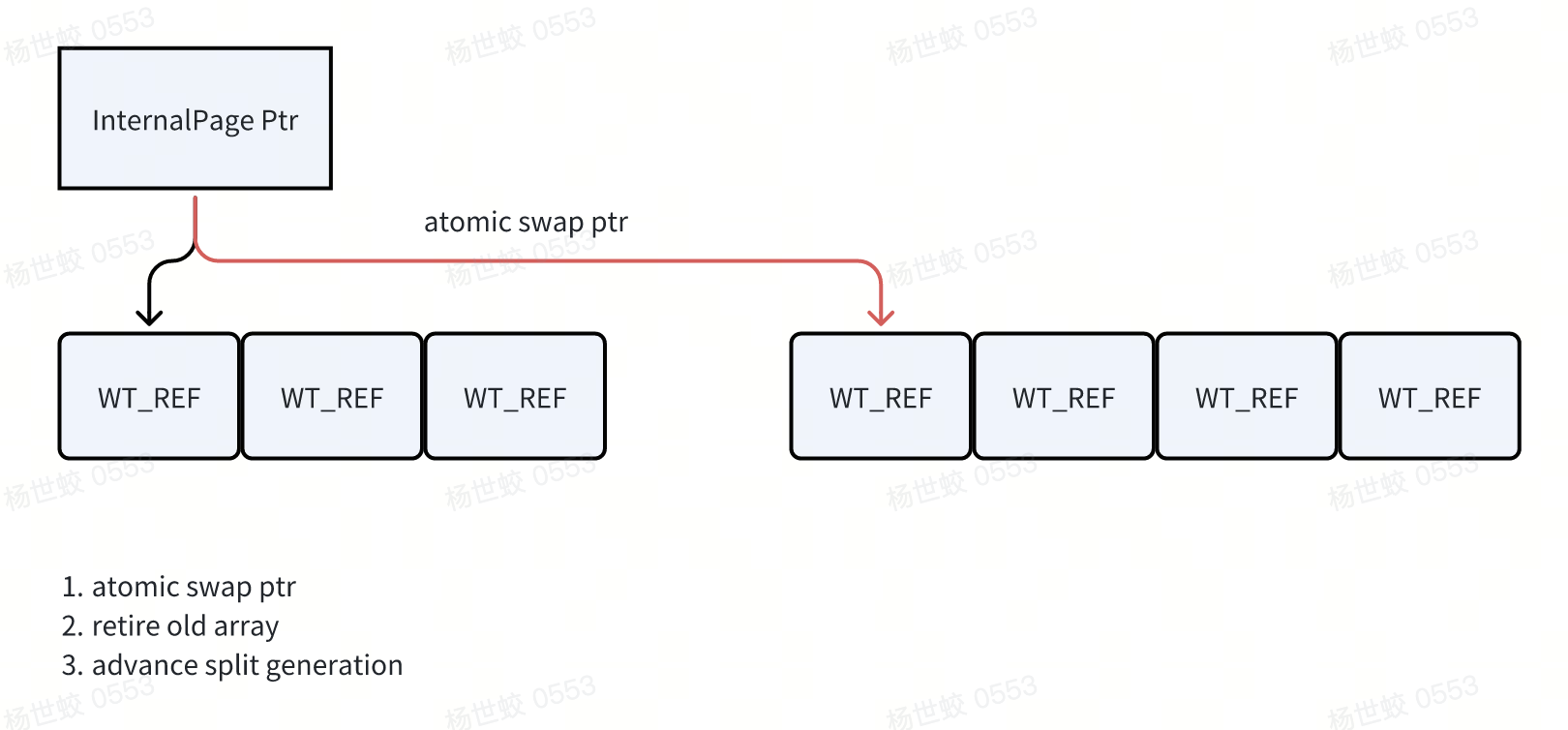
对于InternalPage的修改,都是来源于是Btree的分裂操作,相对低频。所以WiredTiger用了类似COW的方式来修改InternalPage,他会先拷贝一份相同的WT_REF数组出来,将修改应用上去,然后通过一个指针原子的将新的WT_REF数组换进去,对于老的数组,则会走EBR的方式删除。

LeafPage的结构稍微复杂点,主要就是两块:
- 反序列化出来的磁盘上的数据,保存在
pg_row和disk image这里,就是简单的KV结构,一个key指向一个value -
page被修改后创建的modify结构,WiredTiger实现Page内无锁读写的关键就在这里:
- modify内包含两个结构,update list和磁盘上的Row的数量是一样的,磁盘上的每一行都会对应update list中的一个槽位,每个槽位都包含了一个由
WT_UPDATE组成的链表。WT_UPDATE的链表就是版本链,包含每个版本的数据,以及对应的时间戳/TxnID -
Insert list则包含了新插入的数据,由磁盘上的Row所划分出来的每个Range都会由一个SkipList负责,每个SkipList的节点保存的就是对应的新插入的数据,也是有一个
WT_UPDATE组成的链表构成版本链
- modify内包含两个结构,update list和磁盘上的Row的数量是一样的,磁盘上的每一行都会对应update list中的一个槽位,每个槽位都包含了一个由
读流程:
- 如果不存在modify结构,直接读pg_row即可
-
如果存在modify结构,则会交叉遍历insert list和update list的每一项,找到对应的版本链,并根据事务的可见性判断规则找到可见的那个版本
写流程:
- 如果当前写入的key存在于
pg_row中,直接从update list里找到对应的槽位,添加一个新版本即可 -
如果当前写入的key不在
pg_row中,则会尝试在skiplist中找,并在不存在的时候插入新的项到skiplist中,最后也是添加一个新版本
然后看一下Btree在内存和磁盘中的表示,以及状态变换
Evict
Evict说的是将内存中的Page换出,之所以要拿出来单独说,是因为WiredTiger没有传统数据库中的BufferPoolManager的组件(一般实现是一个LRU + 哈希表,当Page没有人引用并且过久没有访问的话,就会从内存中换出,给其他的Page留出位置),而是使用了Pointer Swizzling的设计。

选择PointerSwizzling最直观的好处就是去掉了BufferPoolManager这一中心化组件,让访问Page变得非常轻量化。比较知名的相关系统就是TUM组的LeanStore/Umbra,其核心设计点就是引入了PointerSwizzling。
PointerSwizzling这个设计带来的挑战是:
- 不再有中心化的组件管理Page的换入换出,也没有办法在内存不够用的时候快速得知那些Page是需要换出的,那些不是
-
为了配合PointerSwizzling的去中心化/无锁设计,相关链路上的设计也必须是无锁/去中心化的,否则PointerSwizzling带来的优势会被削弱。给工程实现带来了复杂度

这里大概介绍一下WiredTiger的Evict的实现:
WiredTiger有若干个后台线程作为Eviction Thread,其中一个作为Eviction Walker,剩下的是Eviction Worker。
Eviction Walker会周期性的遍历Btree,尝试找到那些需要被换出的Page,将其分发给Eviction Worker,做真正的Eviction。(这里,因为没有中心化的LRU List,所以只能是遍历整个Btree来定位需要被换出的Page,LeanStore的实现方式也是如此)
在内存压力比较大的时候,前台线程也会参与主动的Eviction,避免后台Eviction跟不上。
不过和LeanStore实现方式不太一样的是,LeanStore遍历Btree时是随机换出,WiredTiger会额外维护一个generation,随着时间逐渐增加,读取的时候则会更新page上的read generation。在换出时会根据page上的read generation来判断当前page是否很久没有访问过了。
WiredTiger换出的激进程度也和目前的脏页率等数据有关,具体的策略就不在这里细讲了,基本思路是根据page上的各个信息,比如read generation,占用的内存大小,以及全局的一些信息,如脏页率,换出的频率等来决定一个分数,从而决定是否换出一个page。
有一个比较直观的逻辑是,感知Btree的结构进行Eviction,WiredTiger不会释放一个具有活跃子节点的父节点,所以Page的释放一定是自下而上的。

释放Page的流程也比较简单:
- 先锁住
WT_REF,避免有后续的线程进来读写。 -
检查refcnt,为0的时候才能释放
-
释放page
WiredTiger没有显式的FlushList/DirtyList,他的持久化操作是在Evict的时候进行的,具体来说,就是在锁住WT_REF,检查了HazardPtr之后,保证了当前线程的独占访问时,才可以将Page上的数据都序列化到磁盘上,从而释放掉脏页占用的内存。这个过程就叫做Reconcile
Reconcile
Reconcile这个名字大概表达的感觉是在磁盘格式和内存格式中有一次显示的序列化过程,与之对应的则是类似Innodb中,磁盘和内存中的Page都是完全一样的格式。
与内存中的Page格式不同的是,磁盘上就是简单的序列化后的KV结构。WiredTiger每个Page是变长的,但是会对齐到某个具体的值,比如4K。那么一个磁盘的Page就可以是4K,8K,12K,但不能是10K。每次持久化的Page都会在磁盘上分配一块新的位置,而不会覆盖写原本的位置(因为是变长的,原本的那块可能已经放不下了),持久化后,新的位置会被更新到WT_REF指针中,并等待父亲节点继续刷盘。
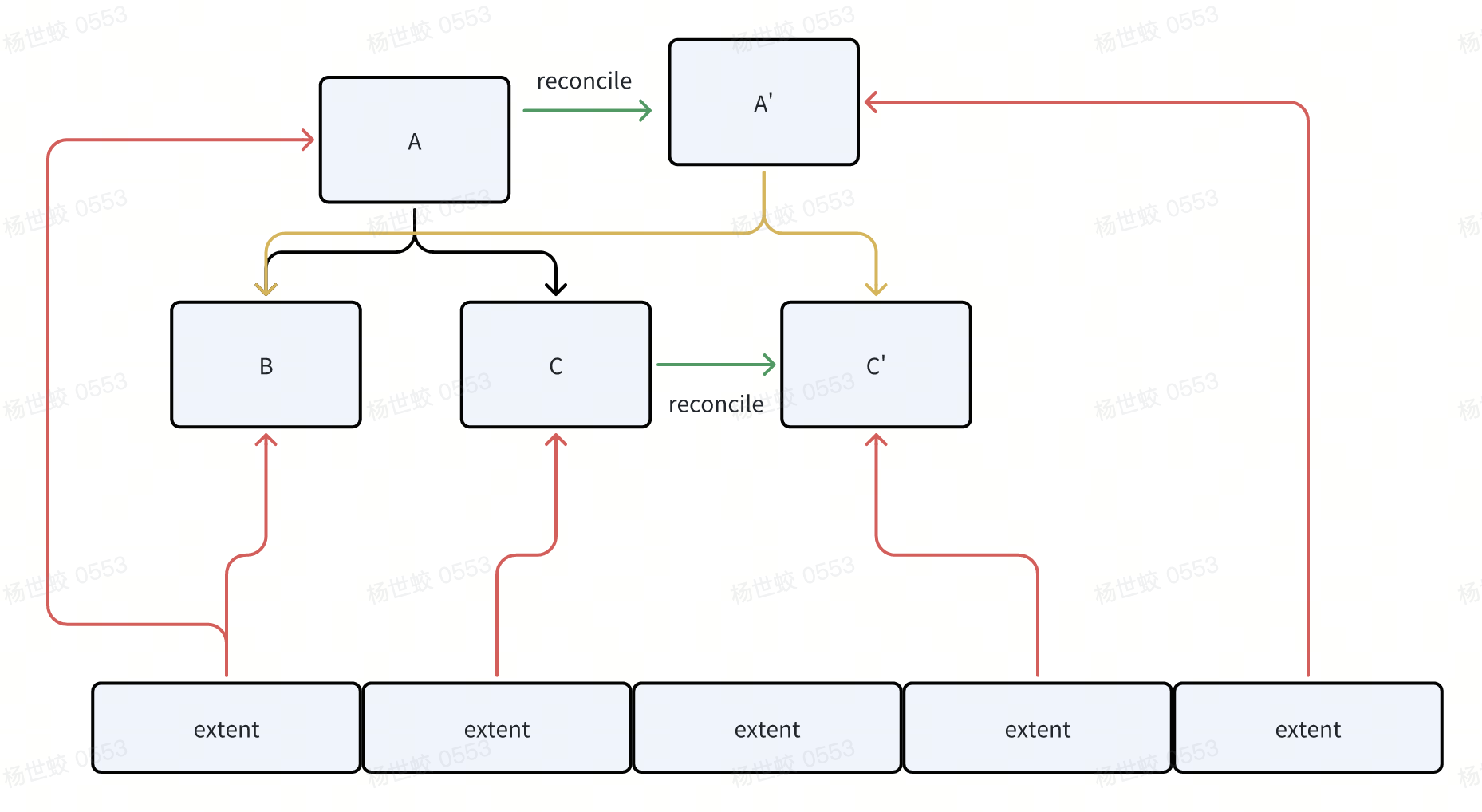
- 一个例子,比如C被修改后,Reconcile会分配一段新的地址出来,存放C',然后会修改父亲节点中的磁盘地址,接着父亲节点会再次做Reconcile,形成A'。所以整体看上去是一个COW Btree的感觉
Reconcile/Evict还处理了Btree的Split,以及内存版本链的GC:
对于Split来说,因为WiredTiger没有限制内存中的Page的大小,所以可以做延迟的SMO,WiredTiger将Split的流程延迟到了Reconcile阶段:
- 在进行Reconcile时,WiredTiger会遍历Page中的所有数据,当发现超出分裂阈值的时候,则会将数据进行分裂,写入到磁盘上。此时内存中仍然是一个比较大的Page
-
在写入磁盘结束后,会将新写入的若干个磁盘块的地址记录到Page->modify的结构中。此时内存中的Page还没有分裂
-
在Reconcile的收尾阶段,会发现本次Reconcile触发了Split,则会构建新的In-memory page,并将新的内存/磁盘地址写入到父亲节点上。然后再递归的向上进行Split。
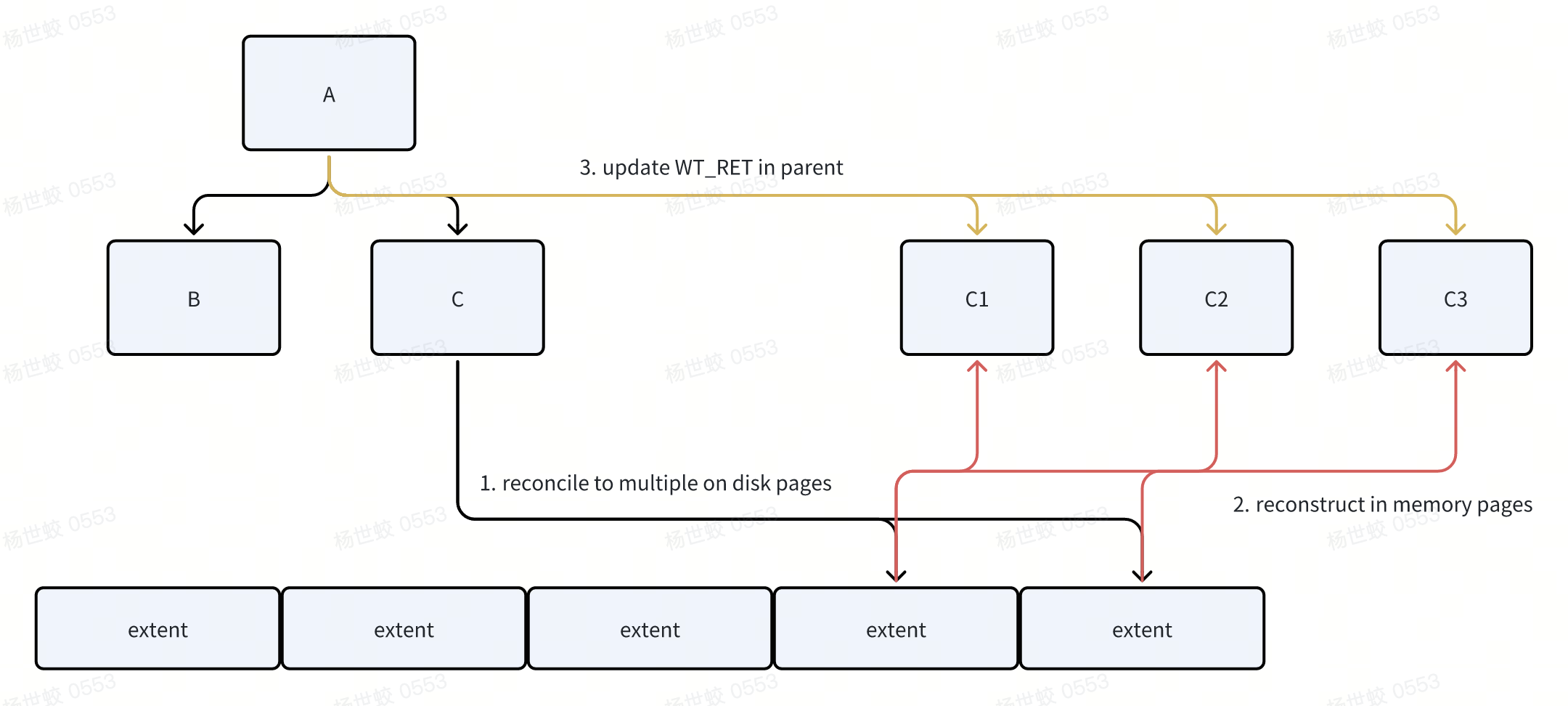
Reconcile并不是唯一一个触发Split的位置:
- WiredTiger之所以选择在Reconcile的时候触发Split,是因为他的LeafPage内的无锁结构和磁盘上的数据是绑定的,所以没有直接搞一个在磁盘上不存在的数据页出来。不过这个限制也只来自于和磁盘数据有关联的部分。
-
在Evict的时候,WiredTiger会判断,如果一个页的最后面一截Skiplist过大,则会触发In-memory split。会直接把最后一个Skiplist中的内容拿出去做分裂,这样并不会影响当前Page本身的结构。也是针对最右插入Workload的优化了,可以不用每次落盘后再做分裂,提高插入性能。
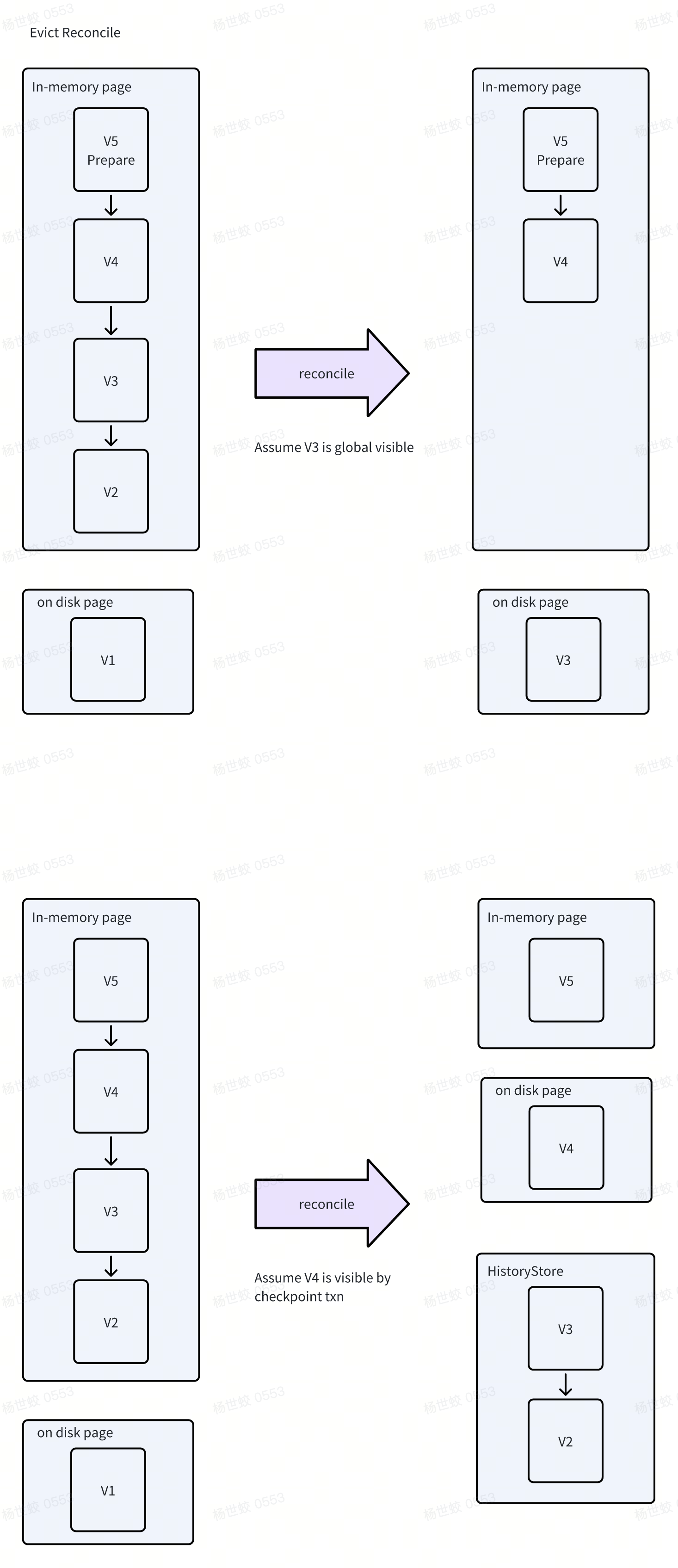
- 对于Evict触发的Reconcile来说,WiredTiger会将所有事务都可见的版本写入到磁盘中,并且磁盘上只会保留一个版本。
-
对于Checkpoint触发的Reconcile来说,WiredTiger刷盘的数据是通过Checkpoint的快照来决定的,最新的版本会被放到磁盘上,那些旧的可能被其他的事务所引用的版本则会被保留到HistoryStore中
-
WiredTiger在Reconcile的时候不会保存未提交的版本到磁盘上。
- 这里的未提交不包含分布式事务。对于分布式事务的Prepare来说,为了保证Checkpoint正常推进,也会正常落盘,那么磁盘上就会包含一个Intent,所有提交的数据都会放到History Store中
需要注意的是,WiredTiger每次Reconcile后,都是会根据磁盘上的Page去重建内存中的Page。对于上面的例子来说,本次写入到磁盘上的是V3,这时候就需要将V5和V4保存起来,在重建内存中Page的时候,会将V5和V4重放回去,保证新老Page数据的一致性。
这里HistoryStore就是用来保存历史版本的一个内部的表,也是由Btree组织的。HistoryStore的Key是由<BtreeID,用户Key,start ts, counter>所组成的
HistoryStore的操作和上述的Btree完全相同,也有相同的Evict/Reconcile逻辑。
Checkpoint
Checkpoint的核心思路是将一个结构一致的,数据具有快照语意的Btree刷到磁盘上,以降低Recover所需要重放的WAL的数量。
Checkpoint的基本流程就是遍历Btree,将所有的脏页都进行Reconcile,这里和Evict不同的是,由Checkpoint进行的Reconcile不会将最新的数据都下刷到磁盘上,而是根据一个快照来选择那些数据应该被放到盘上。
Checkpoint在开始的时候,会获取一个快照,作为本次Checkpoint的快照。那么本次Checkpoint提供的语意是将这个快照持久化到磁盘上,保证后续在读取的时候,这个快照一定是有效的。
在获取Checkpoint快照的时候,会写一条Prepare log record,并且上一把锁,来构建一个Barrier,保证在这个Log之前的事务,一定能被快照读到,进而被持久化到盘上。在这个Log之后的事务,则不会被快照读到,会在后续Recover的时候被重放。

Checkpoint在数据层面的一致性解决之后,需要保证下刷下去的Btree也是正确的,比如如果出现并发的Split和Checkpoint,可能导致Checkpoint写下去错误的Btree。
在Checkpoint开始的时候,会通过Evict Generation来等待所有并发的Evict结束,然后将Btree的状态改为Sync,表示正在进行Checkpoint,后续的Eviction在发现有并发的Checkpoint的时候,会跳过。也就是说一个Btree不会出现并发的Checkpoint和Evict。
核心原因是,Evict会涉及到对磁盘的修改,而Checkpoint希望写下一个结构正确的Btree下去。如果发生了并发的Split和Checkpoint,可能Leaf没写下去,但是Root被Checkpoint了,就会导致数据错误。大概可以看成是Split和Checkpoint有一个大锁。

如果Checkpoint的过程中宕机了,部分数据写下去了,部分数据没有。怎么保证恢复的时候数据是正确的呢?
每次Checkpoint都对应了一个meta,会记录那些block是有效的。在一次Checkpoint中,所有的Data都被写下去后,此时如果发生宕机,因为meta中的数据还未持久化,恢复起来只会看到前一次的Meta,相当于这段时间的所有Flush操作都是失效的。只有当meta被持久化后,Btree的Checkpoint才算完成。这样恢复起来后,就可以看到新写下去的所有的Block,也就包含了本次Checkpoint写入的Btree了。
- 这里是可以理解成,写了一堆新的Page,然后通过类似VersionSet的东西让他们原子提交的。
得益于Checkpoint的一致性快照语意和HistoryStore持久化的特性,用户可以指定名称创建一个只读的Checkpoint,用来服务一些长事务(比如一些分析类查询),其内部的实现原理就是保留这个Checkpoint所依赖的那些Page,因为Checkpoint本身就是一个快照,而不用依赖Redo log的重放。并且这里还有一点细粒度GC的意思,因为这个Checkpoint不会影响前台新写入的数据的GC,他只是pin住了一些数据页而已。
WiredTiger And MongoDB
最后值得一提的是,虽然WiredTiger提供了比较标准的存储引擎相关的接口,MongoDB的使用方式并不是那么的“正规”。其主要原因来自于MongoDB的事务逻辑大多数在上层,但是事务本身又是一个很偏存储引擎的概念,所以在WiredTiger身上开了很多口子,让WiredTiger维护了一些没那么闭环的概念。比如在Timestamp的世界里,数据何时持久化,持久化什么,以及何时GC都是由上层传入的Timestamp来控制的。
在阅读代码的过程中可能会收到这些Timestamp的影响,认为逻辑非常混乱。其实将Timestamp相关的逻辑剥离开和MongoDB这块的逻辑结合起来看就会容易理解很多,后面也会再单独出一篇讲MongoDB和WiredTiger在事务着一层交互的逻辑。

文章评论