The Design and Implementation of Modern Column-Oriented Database Systems 笔记
刚刚入门AP相关的技术,很多地方不是很懂,所以读一读这本册子来获取一个大概的overview
Introduction
一些背景介绍什么的就不贴在这里了。这篇文章主要就是结合MonetDB,C-Store以及VectoeWise这三个系统讲述了列存数据库的大体架构以及一些主要使用的技术。不过要注意的是这里面说的技术虽然整体方向仍然是不变的,但是很多技术的细节以及选择都有所改变。所以我的感觉是通过这篇文章去把握列存数据库的基本思路,然后看看在2000-2010这段时间列存数据库的这些设计决策,再看看新的系统(duckdb/Umbra)的这些设计决策,并且理解这些变化。
开头提到了Access Pattern/Data Layout的trade off,基本意思就是:如果workload访问的数据比较少,那么对于ColumnStore来说,就需要多次的Seek(随机IO),而Transfer时间比较少。而对于RowStore来说,尽管可能多访问了一些数据,但是占比较小,所以更优。随着访问的数据逐渐增加,Transfer的时间占大头,这时候选择ColumnStore的优势则会变大,因为需要访问的数据量整体变少了,Transfer时间更短。
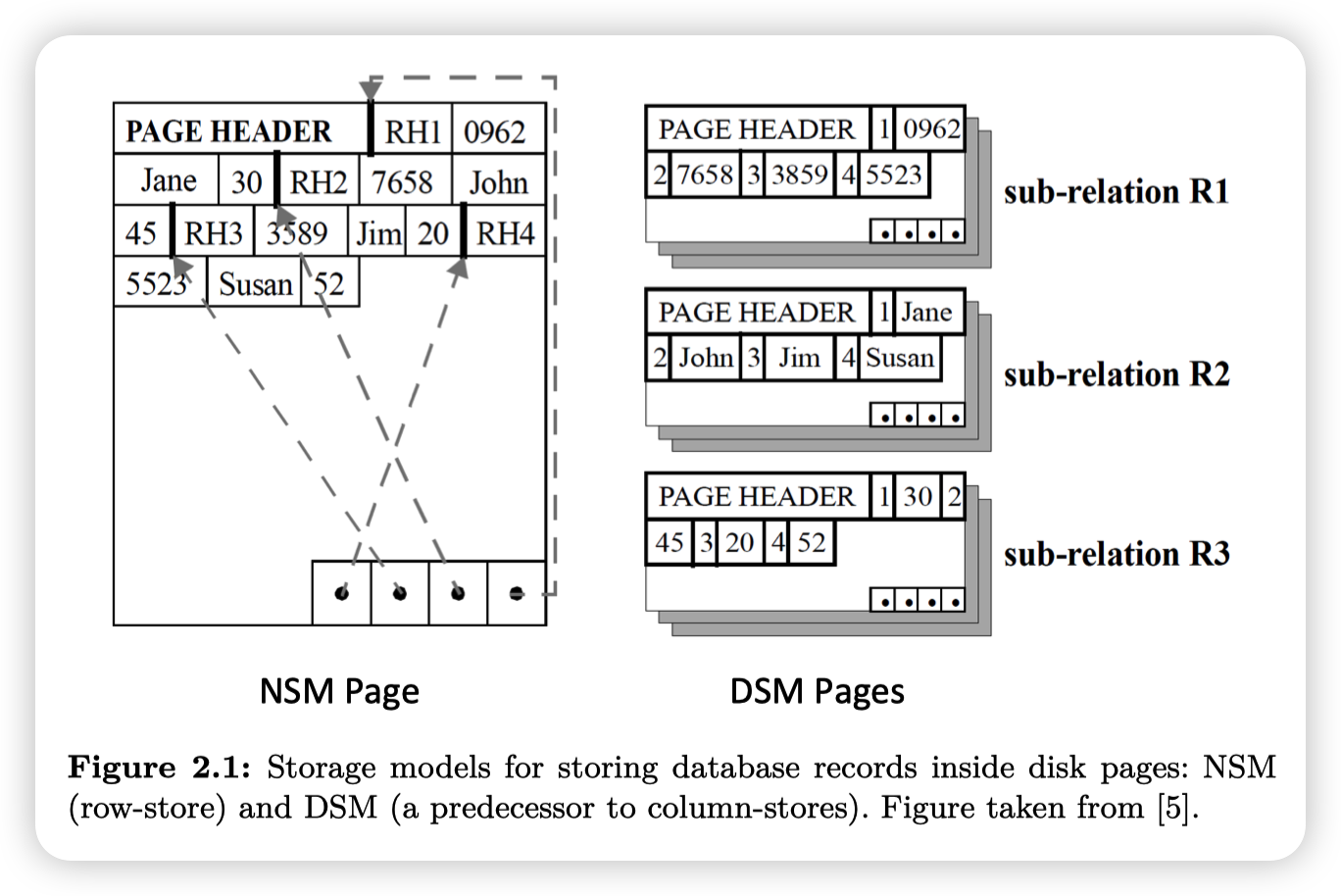
数据库存储数据的格式大概可以分为3种(15721有一节课专门讲这个):
- N-ary Storage Model(NSM):就是行存
- Decomposition Storage Model(DSM):就是列存
- Hybrid Storage Model:混合版,PAX,比如一个block内还是存若干个Tuple的所有数据,只不过是block内部是按列划分的
从NSM到DSM之间混合版的存储格式就有很多种了,除了上面说的PAX,还有一些别的存储方式,也有的格式并不是完全持久化的,而是一些中间结果的格式,在后面会提到
Technology and Application Trends
这里列了一下磁盘规格随着时间发展的变化,得出的结论是(直接贴原文了):
- the transfer bandwidth per available byte (assuming the entire disk is used), which has been reduced over the years by two orders of magnitude
- the ratio of sequential access speed over random access speed, which has increased one order of magnitude.
进一步导出:DBMSs need to not only avoid random disk I/Os whenever possible, but, most importantly, preserve disk bandwidth.
还有一点是,在1980s,执行CPU指令和访存延迟基本上是一样的,而随着技术的发展,执行CPU指令的速度越来越快,访存延迟和CPU指令执行延迟比例越来越大,所以1990s有一波研究in-memory data layout的热潮来解决这个问题。
The original motivation behind MonetDB, which was initially developed as a main-memory only system, was to address the memory-bandwidth problem and also improve computational e"ciency by avoiding an expression interpreter
从这里也可以看到,列存数据库并不是简单的通过列存减少读取数据的数量来获得优势的。还有这些针对现代硬件(超标量处理器,缓存层级的比例)来做的优化。
对于Application Trends来说,就是随着互联网发展,数据规模变大,用户希望搞一些分析bulabula这种。我没有这块相关背景,就不多说了。
然后后面列了列一些工业界的数据库在列存方面的发展,现在来看(由于Snowflake的成功?)是到处都是,回到10年前看的话,貌似也是到处都是?(e.g., Vertica, Ingres VectorWise, Paraccel, Infobright, Kickfire, and many others)。大公司的话,IBM Blink project,SAP HANA,SQL Server都搞了列存相关的技术集成到他们已有的数据库中。
Column-store Architectures
这一节是讲一下C-Store,MonetDB以及VectorWise的架构
C-Store
In C-Store, the primary representation of data on disk is as a set of column files. Each column-file contains data from one column, compressed using a column-specific compression method, and sorted according to some attribute in the table that the column belongs to
上面这段说的是C-Store的ROS(Read Optimized Store),他还有一个WOS用来优化写入,是行存/不压缩的。具体数据结构不清楚,应该类似MemTable,C-Store会周期性的将数据批量从WOS移动到ROS,用来均摊开销。
C-Store的特点:
Each column in C-Store may be stored several times in several different sort orders. Groups of columns sorted on the same attribute are referred to as “projections”. Typically there is at least one projection containing all columns that can be used to answer any query.
DBA去针对workload来定义Projection,C-Store会根据请求来选择Projection。并且看这句话的意思,C-Store应该是不会跨越Projection来读取数据的。至于具体选择Projection的逻辑,我脑补的一个可能的算法就是优先选择请求中“选择率”低的列为主排序键的Projection,这样可以提前prune掉很多数据。
Each column in C-Store is compressed and for each column a different compression method may be used. The choice of a compression method for each column depends on a) whether the column is sorted or not, b) on the data type and c) on the number of distinct values in the column.
C-Store不支持二级索引,但是支持一些在主排序键上的稀疏索引。
A sparse index is a small tree-based index that stores the first value contained on each physical page of a column.
A similar sparse index is stored on tuple position
可以根据排序键/Tuple Position快速定位Page。C-Store Page的大小是MB级别,所以索引还是非常稀疏的
MonetDB and VectorWise
MonetDB通过MMAP来避免维护BufferPool
MonetDB是PushBased,full materialize模式。每个算子的输入和输出都是BAT(Binary Association Table),即<VirtualD, Value>。这里的VirtualD就是TupleID,或者是Tuple的Array index。这里存VirtualID也表明了MonetDB希望尽可能推迟Tuple Reconstruction
MonetDB会将用户的请求(可以是SQL/SPARQL等各种模型)转化成BAT algebra。MonetDB hard-coded这些BAT algebra的算子,在执行的时候,复杂的用户请求会被转化为多个BAT algebra算子。他们称这里的思路为:the RISC approach to database query languages
感觉我描述的不是很清楚,还是来点图示和原文吧
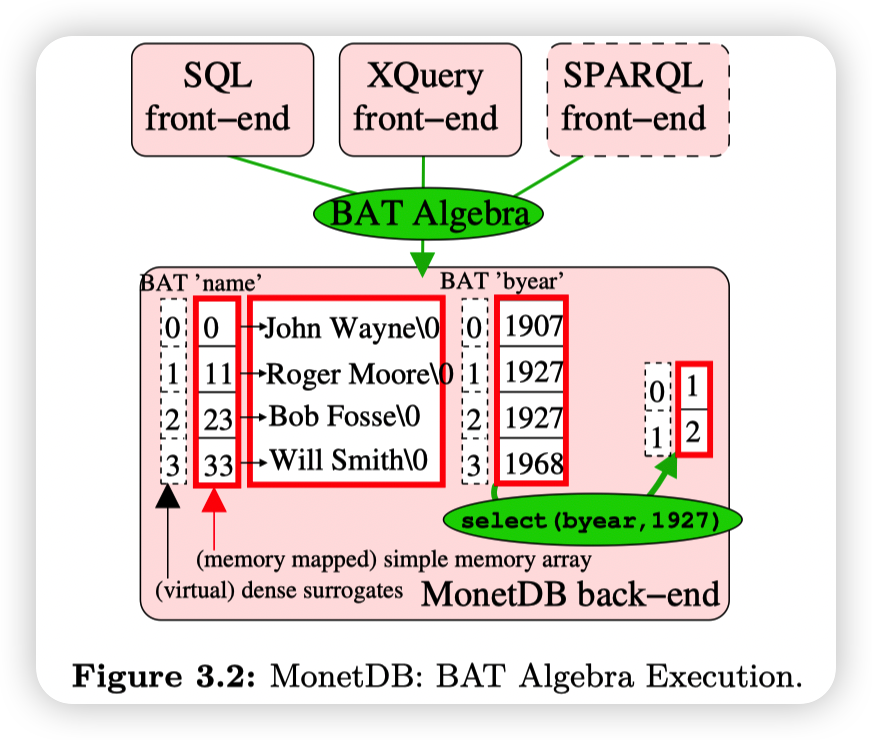
The reason behind the e"ciency of the BAT Algebra is its hardcoded semantics, causing all operators to be predicate-less.
all BAT algebra operators perform a fixed hard-coded action on a simple array. As such, complex expressions in a query must be mapped into multiple subsequent BAT Algebra operators.
Expression interpretation in MonetDB e!ectively occurs on the granularity of whole column-at-a-time BAT Algebra operators, which much better amortizes interpretation overhead
MonetDB的缺点主要是full materialize中间结果,导致开销比较严重。(还有一些别的小点,比如MMAP,数据未压缩等)。后续CWI构建了VectorWise来解决这些缺点。核心点主要是选择了Vectorized execution model,即每个算子的输入是一个block/vector of column,从而避免了全量物化中间结果的开销。
Other Implementations
这一节讲了一下工业界的一些列存的实现
最简单的一些是只把数据按照列式来存储,但执行引擎仍然使用的是row-based。好处是实现简单,架构不需要有大的改动。
然后是一些Native Column-Store:
- IBM BLU/BLINK:这个是和DB2的行存引擎放到了一起,然后optimizer负责决定哪个引擎负责哪些查询。他们还引入了一种叫做
Frequency partitioning的技术。大概思路是每个Page有自己独立的dictionary encoding,使得他们有更紧凑的数据存储格式,并且他们会以列为粒度重新组织数据,从而提高压缩率。 - SQL Server:微软为SQL Server支持了列存以及列式执行引擎。用户可以通过使用“Column indexes”作为二级索引来提高扫描某一列的性能,或者是将Column storage作为Primary storage来支持一些更nb的AP场景
Column-store internals and advanced techniques
这一节会描述一下前面那些系统所提到的列存相关的技术细节
Vectorized Processing
Volcano-style iterator model是tuple-at-a-time pipelining执行,与之对应的是full materialization,即每个算子都会一次消费全量的数据输入,然后将全量结果输出。
Vectorized Processing则是在这两种模型之间的平衡版本:
This model separates query progress control logic from data processing logic.
Regarding control flow, the operators in vectorized processing are similar to those in tuple pipelining, with the sole distinction that the next() method of each operator returns a vector of N tuples as opposed to only a single tuple.
Regarding data processing, the so-called primitive functions that operators use to do actual work (e.g., adding or comparing data values) look much like MonetDB’s BAT Algebra, processing data vector-at-a-time
控制流类似于iterator model,每个operator都有Next用来返回N个tuple。而数据处理则是通过tight loop处理vector,从而允许编译器(或者手写)来进行更好的优化(SIMD等)
一般列存数据库每个算子都是一次处理一个vector,所以vector大小的设置可以通过保证输入数据,输出数据以及辅助数据结构可以fit in L1 Cache来确定。
Vectorized Processing的好处:
- Reduced interpretation overhead:Next call的开销被均摊了
- Better cache locality:vector的大小根据缓存大小设置,可以提供更好的数据局部性(相比于full materialization)。同时因为控制流会循环vector size次,所以也有更好的指令局部性(相比于tuple at a time)
- Compiler optimization opportunities:处理vector的算子也是tight loop,并且编译器可以生成SIMD指令
- Block algorithms:算子的处理逻辑可以利用batch这个特性来优化一些东西。比较简单的可以想象成从
output.reserve(1)变成output.reserve(n)这样 - Parallel memory access:这个是说相比于tuple-at-a-time的架构,每次cache miss的时候CPU没办法向后执行太多指令(有很多间接跳转)。而对于vector-at-a-time来说,在tight loop中CPU有更好的机会可以发出多个load指令,从而打高memory bandwidth,并且重叠访存延迟。说白了就是现代CPU这种out of order execution更偏向tight loop,而非各种if else的控制流。我直观感觉这个比较关键,但具体不知道是什么情况。
- Profiling:这个意思是vector-at-a-time可以批量更新一些统计/profile的信息,比tuple-at-a-time开销低
- Adaptive execution:VectorWise在执行的时候可以根据统计信息来计算选择率,对于选择率低的请求,就会走branch较多的算子实现,而对于选择率高的请求,则会走branch-less的算子实现。文章中提到,在执行的时候可以尝试每种算子的不同实现,并选择性能最高的作为后续算子的执行方式,这种方法的好处是具体的方案不需要依赖cost-model以及统计信息的维护,并且不会收到数据分布等因素的影响,还可以根据不同硬件进行适配。(首先我不知道他说的这个方法VectorWise到底用没有,然后就是对于一些算子感觉确实这种方法用起来比较好,但是我认为他不能完全替代cost-model,因为这种自适应执行是算子级别的)
最后这篇文章提到了,因为Vectorized Execution这种方式处理行存和列存都比较方便(都是通过block表示),再加上某些算子更偏向列存,而某些算子偏向行存(他说hash join,但我感觉列存也没啥问题)。所以Vectorized Execution可以提供一个新方向就是query layout planning,在执行的时候动态切换数据的layout。这个我不太清楚目前比较新的系统有没有做这个,或者说列存对于所有算子来说足够有效了。
Compression
首先列存对于压缩最直观的优势就是压缩率会变高,因为相同的列放在一起,数据类型和模式都是相同的,不过不太清楚对于一些通用的数据压缩算法来说是否有比较大的提升。
压缩的目的可以减少空间占用,减少所需要IO的数据数量,并且还可以减少从内存到CPU传输的数据数量,进而减少内存带宽占用。大概思路就是反正CPU这么快,瓶颈都在访存,那不如让多余的这些cycle去解压数据,通过CPU cycle换内存带宽。
一些最优化编码手段(比如哈夫曼编码)虽然压缩率高,但是对于计算来说效果却不太好。而所以列存数据库一般使用一些轻量级的,定长的压缩技术,这样可以利用现代CPU的SIMD指令实现数据级并行。这里的SIMD指令有两个作用,一个是可以通过SIMD做解压缩,另一个则是直接在未解压的数据上通过SIMD做计算。比如bit vector,或者dictionary encoding
然后说一下压缩的算法:
- RLE:基本思路就是把数据表达成一个三元组(value,start position,runLength)。在有排序并且基数比较小的场景下应该可以有很高的压缩率。在列存数据库中因为相同列存到了一起,这时候RLE的效果才能发挥出来。而在行存数据库中,RLE可能只能用来去压缩一些有大量重复字符串/空白的blob列。有个缺点就是这个编码方式是变长的,在tuple reconstruction处理会稍微复杂一点,并且也不能用SIMD加速。
- BIt-Vector Encoding:和bitmap index是一个东西,对于基数比较小的列效果比较好。好处是数据定长并且紧凑,可以利用SIMD指令,还有一些工作是去压缩这些bit-strings。这里举个bit vector的例子:

- Dictionary:Dictionary Encoding的思路就是通过一个映射(字典)来把值映射成一些紧凑的编码。Dictionary的粒度可以是整个Table,也可以是类似IBM BLINK那样的per-page dictionary。这种压缩方式可以把变长的string映射成定长的字段(当然要string有重复的时候才能用,否则还不如存offset)。通过Dictionary把column转化成定长的数组,我们就可以直接在编码后的数据上进行操作,这样就可以应用一些上面提到过的技术,比如SIMD,以及避免存储TupleID等。
- Frame Of Reference:这个其实类似Delta Encoding,要求数据分布具有"value locality",比如存储温度的时候,可以先存一个Base,然后后面存Delta,那么Delta所需要的存储空间就比较小。(我个人脑补这种差分数组的存储方式其实还可以支持高效的区间加减,但感觉用处不大)。
- The Patching Technique:这个主要是和其他的压缩方法配合使用的,比如Dictionary Encoding,在数据的基数比较大的情况下其实效果不好,但数据分布大概率是幂律分布/正态分布(我不确定),所以只需要压缩哪些频率比较高的数据,对于频率比较低的数据,可以直接存原始值/或者offset之类的东西。
上面大多提到的东西都是一句话带过,实际上文章内还有一些相关的引用,感兴趣的话可以去看看这些引用,或者直接去看15721 Database Compression这一节也行
Operating Directly on Compressed Data
这里是让Executor直接操作压缩的数据,从而获得性能提升。比较直观的例子有:
- 如果数据是通过RLE压缩的,那么在一些聚合操作,比如SUM上,就可以不用一个一个遍历数据,而是通过
value * run length计算即可 - 如果Dictionary Encoding是保序的,即如果
A < B, Encode(A) < Encode(B)(这里不是很严谨哈)这种。那么在一些谓词的操作上,比如select * from A where value > 100 & value < 200就可以把这里的100和200转化成编码之后的值来进行比较。好处自然是可以利用SIMD以及编码紧凑这种特性来提高数据级并行度。
文章中还提到了,说希望通过一层抽象来避免让Executor直接感知数据的压缩方法,这样可维护性太差。大概思路就是Executor操作Compression Block,然后Compression Block提供一些数据访问的方法,还有一些高级的元信息(比如GetSize)。这块我感觉说的比较抽象,而且不太确定这里的实现是否现在还有使用,所以这里就跳过了,之后参考一下duckdb是怎么做的。
Late Materialization
这里的核心思路就是希望尽可能的推迟Tuple Reconstruction的时机,尽可能的通过一些轻量级的表示来存储中间结果,从而减少物化中间结果的开销。比如一个带谓词的Table Scan,因为我们并不是iterator model(无物化中间结果),所以还是需要输出一些内容到Vector/Block中的。那么这里我们肯定是希望存储TupleID/Offset之类的东西作为中间结果,而非Tuple本身。
中间结果其实就是"list of positions",他的表示有很多种,比如之前提到的MonetDB的BAT,就是column value + virtual id。取决于选择率,我们可以将中间结果表示为:
- simple array
- bit string
- set of ranges
这里他给出了一个例子表达Late Materialization的思路

后面这里还说了一些Late Materialization的优点和缺点,值得关注的有:
- 对于使用RLE等压缩技术的数据,在tuple reconstruction的时候需要进行解压,从而丧失了直接操作压缩数据的优势,而Late Materialization可以推迟tuple reconstruction的时机,从而推迟解压时机
- 在一些场景下,early materialization可能更有优势,比如谓词非常多的场景下,我们需要对很多的中间结果做intersection。以及上述例子中可以看到的,reconstruction需要涉及到对列数据的随机读取,性能不佳。解决的方法就是用类似PAX的思路,将中间结果存储成行列混合的形式,一个Block中存储有多个和本次query相关的列,从而减少tuple reconstruction开销。(其实这里我感觉也和持久化的data layout边界有点模糊,很具体的还得再去读读duckdb)
Joins
这里没有介绍join算法,而是说了说Join配合Late Materialization出现的一些问题。比如Hash Join的时候,对于进行Probe的那个表,他的position list是顺序的,而用来构建哈希表的那个表得到的position list则是乱序的。所以在tuple reconstruction的时候,对于乱序的position list会产生很多随机IO,导致性能问题。
一个方法是通过两次重映射来把随机读取数据改成顺序读取,但是开销是两次Sort。
更细化一点的,可以不需要全局有序,因为虽然随机IO比较慢,但是在block内还是比较快的,所以可以根据block排序,block按序读取,block内随机读取。这样可以节省一点排序的开销。
另一种方案就是提前物化部分的列,比如这里需要随机IO的表,我们可以在build hash table的时候就直接把后续需要用到的column读上来,而不是只放hash value和tuple id。这样后续的probe阶段在匹配成功后可以直接把对应的column value取出来。
Group-by, Aggregation and Arithmetic Operations
- Group-by可以通过只物化需要的column来加速,一般的group by实现都是通过哈希表,这里的优化思路就和hash join中的哈希表相同了。
- Aggregation,之前提到过可以通过压缩数据来做。比如distinct可以通过直接计算dictionary的大小来得到等。
- Arithmetic operations,他的意思是可以通过提前物化需要的列来避免表达式树中间结果的生成,思路也类似于上面的Join优化了。这块我看的也比较迷惑,需要读读代码
Inserts/updates/deletes
列存数据库的更新难点主要在:
- Row是分开的,每次写入都会涉及到多个位置的随机写。像C-Store这种存多个projection的,性能会更差一些
- 数据有压缩,写入的时候处理会复杂一些
所以一般的方法都是区分开ReadStore和WriteStore,然后读取的时候去做合并。
实现WriteStore比较简单的方案是通过一些内存中的结构存储最近的变更(insert/delete/update):
- MonetDB就是使用了简单的column。对于每一个用户的column,他都有两个column来存储最近的insert/deletes
- C-Store的Write optimized store使用了行格式存储近期写入的数据(这个我不太确定),然后读取的时候需要合并WOS和ROS的结果,处理起来会麻烦点
- 一些额外的优化可以做,比如通过bitmap来存储tuple是否被删除,然后通过一些压缩技术来压缩这个bitmap(这个我也不是很确定现在主流的做法,还需要再去看看)
- VectorWise提出了一个叫Positional Delta Trees(PDTs)的数据结构。大概思路就是里面存了Position相关的diff,而非通过sort key去索引,从而避免每次都读取sort key列。PDT这种differential data structure的好处就是提供快照比较简单,其思路类似OCC,新的事务写入可以先放到一个小的PDT中,最后在合并到共享的PDT中来提交写入。
Indexing, Adaptive Indexing and Database Cracking
列存数据库的索引大多是那种紧凑的数据结构。(与之对应的就是一些平衡树等复杂度有保障的数据结构,但是需要大量的指针跳转)比如bitmap等
另一种索引则是概率数据结构(不清楚skeches是不是他们的统称,但貌似有个库是收集这些数据结构的),比如布隆过滤器,或者一些记录统计信息的结构,比如zonemap
Database Cracking其实和Adaptive Indexing是一个意思,就是通过记录一些用户请求的统计信息,来自适应的调整数据/索引的结构。近期有很多相关的AI for DB的工作应该和这个有关,比如为用户请求建模,然后对于更新多的地方调整为行存,读取多的地方调整为列存,以及一些扫描比较少的地方可以不构建索引,减少空间开销等。
The main idea is that the system autonomously creates only the indexes it needs. Indexes are created (a) adaptively, i.e., only when needed, (b) partially, i.e., only the pieces of an index needed are created and (c) continuously, i.e., the system continuously adapts.
Summary
最后贴一张总结,虽然我感觉他上面的Row-store/Column-store的划分没啥道理
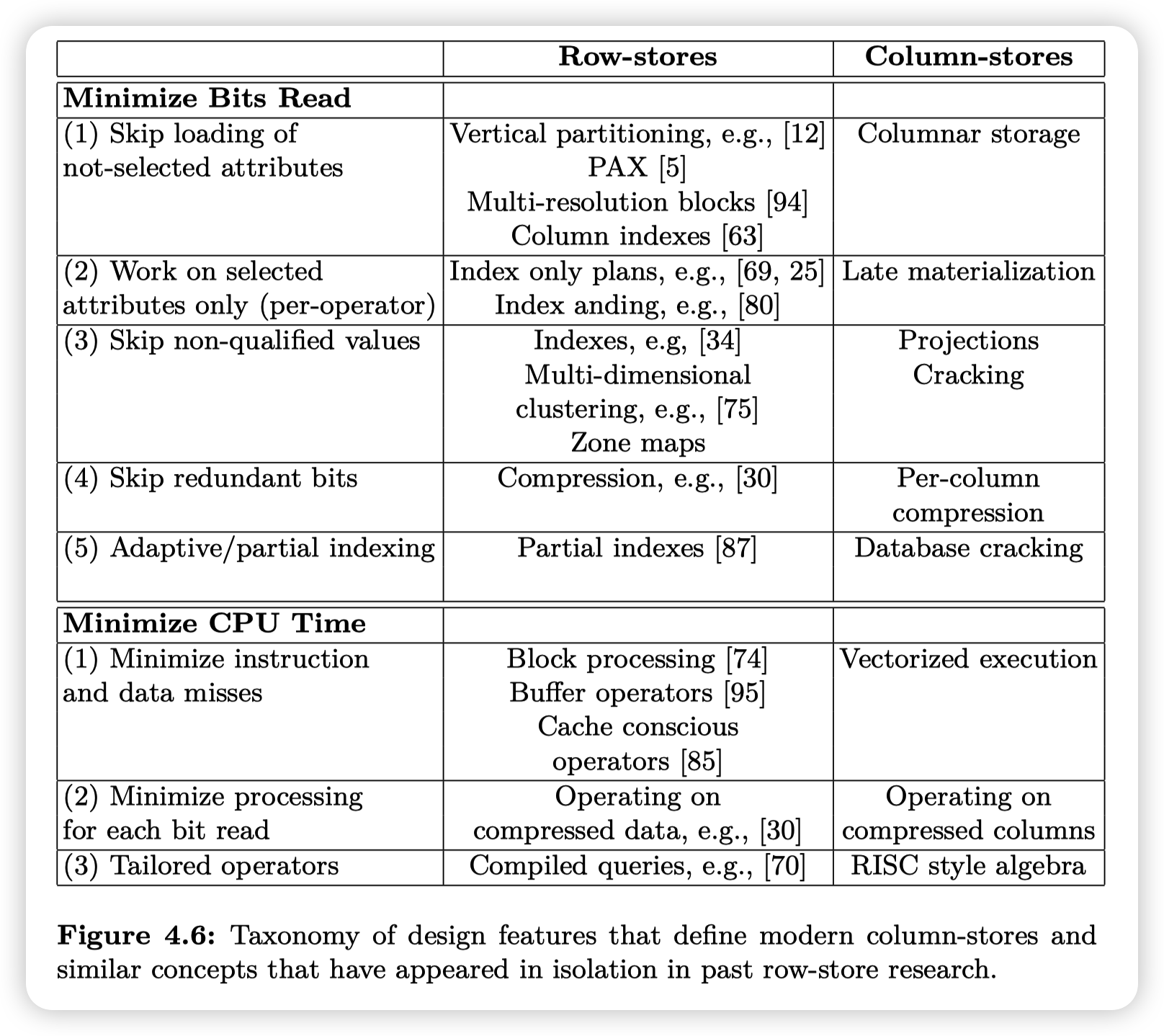
As it is evident by the plethora of those features, modern columnstores go beyond simply storing data one column-at-a-time; they provide a completely new database architecture and execution engine tailored for modern hardware and data analytics.

文章评论
一整个牛逼住了