ARIES/IM
Tree Architecture
A key in a leaf page is a key-value, record-ID pair.
The leaf pages alone are forward and backward chained.
A high key stored in the nonleaf page for a given child page is always greater than the highest key that is actually stored in that child page.
Basic Index Operations:
- Fetch: Given a key value or a partial key value(prefix), check if it is in the index and fetch the full key.
- Fetch Next: Having opened a range scan with a Fetch call, fetch the next key satisfying the key range specification.
- Insert: Insert the given key(key-value, RID). For a unique index, the search logic is called to look for only the key value since duplicates must be avoided. For a nonunique index, the whole new key is provided as input for search.
- Delete: Delete the given key.
Problems:
- 怎么生成日志
- 怎么保证SMO在恢复后的一致性
- 怎么执行操作以减少对其他并发访问的影响
- 怎么保证事务rollback不会影响SMO
- logical undo
- 仍然是logical undo
- 避免死锁
- 支持不同粒度的锁
- 处理phantom problem
- 唯一索引的处理
- SMO与其他操作的并发执行
ARIES通过dummy CLR来保证SMO不会被回滚。i.e. 在SMO之后加一个PrevLsn在SMO之前的CLR。这样在rollback的时候就不会回滚SMO。
Concurrency Control

ARIES/IM的特点:
- treating as the lock of a key the same lock as the one on the corresponding record data in a data page
- not acquiring commit duration locks on index pages even during SMOs
- allowing key retrievals, inserts, and deletes to go on concurrently with SMOs.
To lock a key, ARIES/IM locks the record whose record ID is present in the key. We call this data-only locking
其他的方法,SystemR和ARIES/KVL中会对KV上锁,DB2和SystemR会做Page Locking。这里称他们为index-specific locking
With data-only locking, the current key is not explicitly locked by the index manager during key deletes and inserts, since the record manager would have already locked the corresponding data with a commit duration X lock during the data page operation.
The explicit locking of the deleted or inserted key by the index manager is needed only if index-specific locking is being done.
During fetch and fetch next calls, the index manager locks the current key, the record manager does not have to lock the corresponding record during the subsequent record retrieval from the data page.
说白了就是index specific locking会在各种操作的时候都在index manager以及record manager中上锁。而index locking则只会在insert/delete的时候在record manager中上锁,在fetch的时候在index manager中上锁。
参考一位前辈的文章,里面有一个index specific lock和data-only lock的示意图
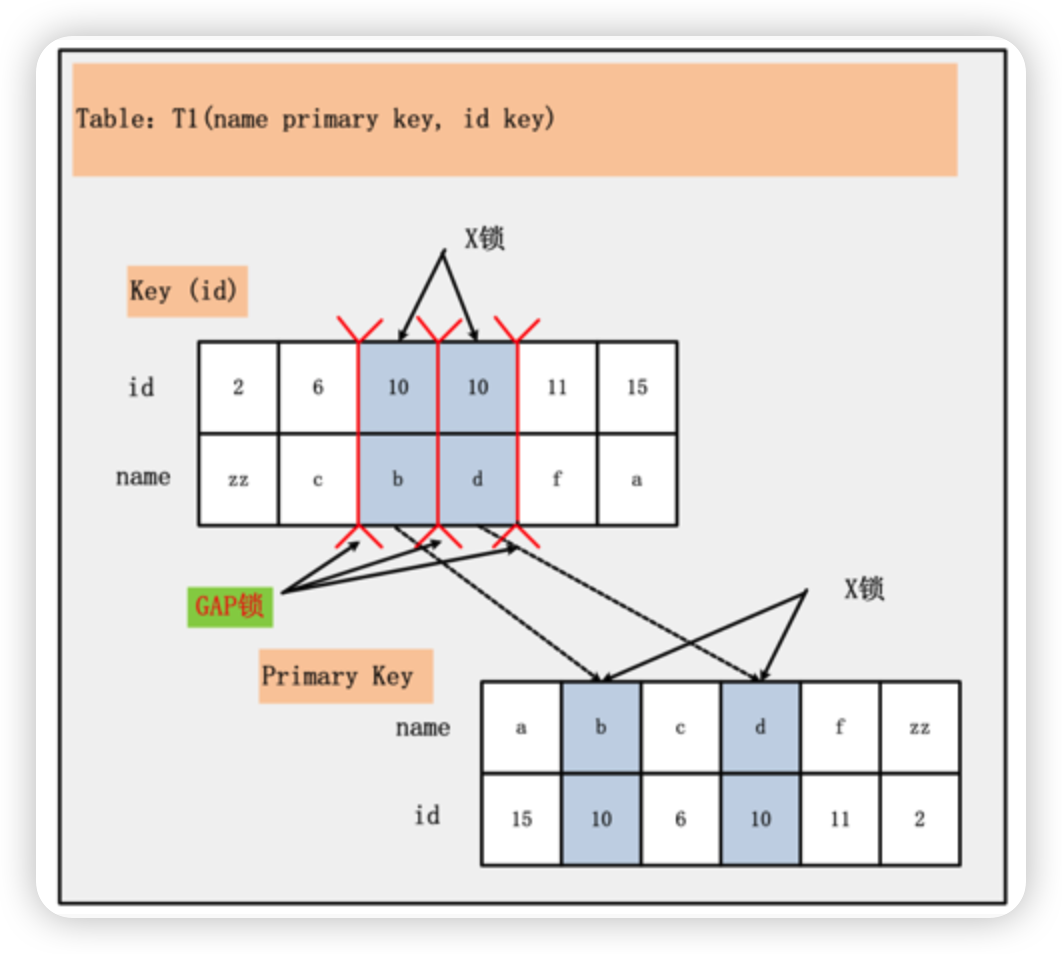
这里是innodb的示意图。index manager说的就是在index上上锁。对应就是二级索引上的gap锁。record manager在这里说的就是在primary key(cluster index)上上锁。对应了索引和数据。
插入和删除会锁住next key。来防止phantom
Latching: Not more that 2 index pages are held latched simultaneously at anytime. In order to improve concurrency and to avoid deadlocks involving latches, even those latches are not held while waiting for a lock which is not immediately grantable.
Latch coupling is used while traversing the tree.
SMO
SMO是bottom-up的。为了避免死锁,会先释放下面的page的锁,再获取父节点的锁。
这样读者可能看到一些不一致的状态。他通过SMO_Bit来标识当前结点正在进行SMO操作。从而让其他人等待。
SMO之间的操作是串行的。Tree-level有一个SMO RwLock。
SMOs within a single index tree are serialized using an X tree latch that is specific to this index
说白了,SMO_bit的作用就是避免我们每次都需要获取SMO的的lock。所以每次只有当发现当前page上标记了smo bit的时候,才会尝试获得S lock,来等待SMO结束。
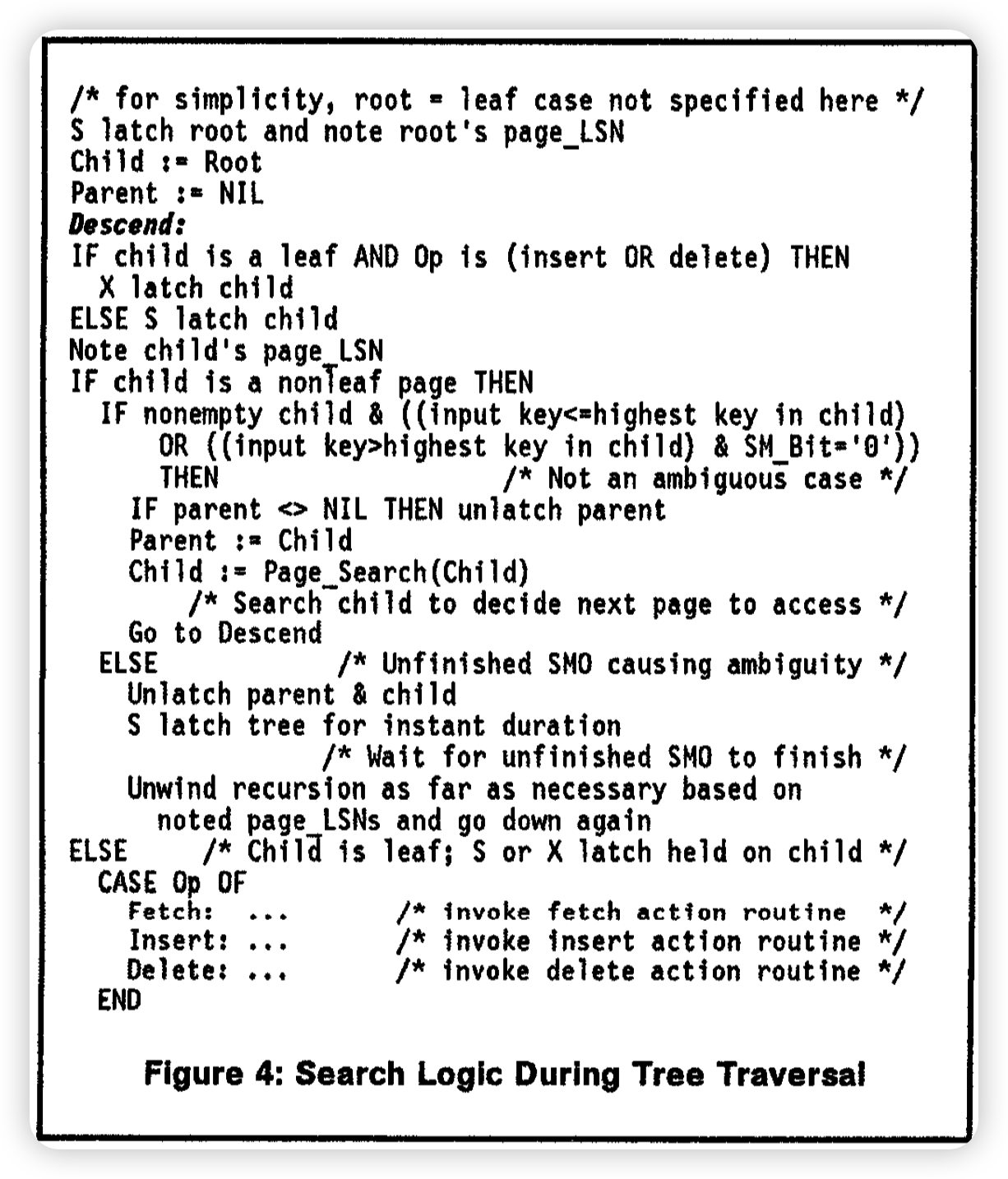
阴间画质...
当child是非叶节点的时候,如果他的high key大于当前输入的key。说明即便有SMO叶不会受到影响。或者输入的key大于child中的high key且当前没有SMO。说明这次操作没有受到SMO的影响,只是我们需要拓展high key而已。那么我们会正常执行。
如果本次受到了SMO的影响,那么我们应该等待SMO结束,先释放锁,然后获取SMO lock的读锁等待他结束。根据记录的LSN找到最早的没有被影响到的page。重新下降。
叶子节点的话,即遍是受到了SMO的影响,我们也可以跟到左右邻居的page上执行操作。但其实感觉叶节点上重做一下上面的逻辑更好一些。即发现SMO的时候重新定位一下。
Fetch

Fetch是单点查。如果没找到的话会找next key。
如果发现当前page上没有就会持有latch并找到下一个page。找到next key并锁住。
如果next key没找到会锁住一个特殊的锁叫EOF。
文章中描述的lock会假设锁会立刻被持有。为了避免死锁并且允许更高的并发度,当我们没能够获取这些锁的时候,会做以下几步:
- all the latches must be released
- the lock must be requested unconditionally
- once the lock is granted, a verification must be performed.
tree latch also should not be requested unconditionally while holding page latches.
这里的conditionally说的应该是try lock。而且注意这里说的是lock。因为lock持有时间较长。而非latch。
之所以要锁住next key是为了防止phantom
在fetch next的时候,返回给User我们就会放锁。回来的时候会重新检查page上的LSN。如果发生了变化,那么next key会通过一次Fetch来重新获取。当有not found的时候同样要获取next key的锁,来防止phantom。(所以可能获取锁的range要大于我们想要的)
Insert

RR通过在next key上获取X lock来防止phantom。x lock是瞬时的。同时也是为了防止有其他事务删除了相同的key,但是还没有提交,我们就需要等待。
non unique的情况下因为锁住的是整个key,所以其实和unique的情况类似。
Delete

删除的时候会获取在next key上的commit duration的x lock。来防止其他事务插入或者删除这个key。同时防止phantom。
当发现删除的Key是最大或者最小的key的时候,即修改了当前page的boundary,他就会获取一下SMO lock
SMO

SMO的时候先捞起page。再X lock住整个tree。
从下到上设置SMO_Bit,然后修改双向链表指针,记录log,在unlatch page。
继续向上并设置SMO_Bit。
写入dummy clr来跳过SMO的undo。
重设SMO_bit为0。
这里不同的是,如果是删除,就先删除,再SMO。如果是插入,则先SMO,再插入。直观的感觉可能是和空间有关。
上面Insert和Delete都有对SMO_bit的处理。所以这里的清空SMO bit是可选的。其他的人来了会用SMO lock互斥一下,然后帮助清理这些bit。
这里delete bit的设置要仔细考虑一下。
为什么insert可以是instant duration,而delete需要是commit duration。
因为我们需要有一个点可以让其他的事务在和我们冲突(materialize conflict?)。对于insert来说,他这个kv本身就可以让其他人看到,就算读也有tuple level的lock。而对于delete来说,如果我们把一个kv删掉了,由于他随时可能回滚,其他人就有可能看不到这个kv对了,所以需要在next key上上锁,这样后续的人就可以通过锁上的词冲突意识到这次删除。
as long as the key is in the uncommitted deleted state, we need to leave behind a strong lock on a still-existing key for other transactions to trip on and realize that there is an uncommitted delete.
The inserted key itself serves as the trpping point, whereas for delete the tripping point has to be another key which must be guaranteed to be a stable one.
Recovery
这一节提到了ARIES/IM的恢复。其实和原本的ARIES没有什么区别。
SMO不能被undo,所以写入结束后会写一个dummy CLR来跳过对SMO的undo
这里比较关键的是说了一下上面的插入删除的算法里面一些步骤的理由。比如为什么删除操作需要一个Delete Bit。
这里提出了一个概念叫a point of structural consistency(POSC),代表的是树的结构是一致的。
在进行SMO的过程中会破坏掉树的结构。
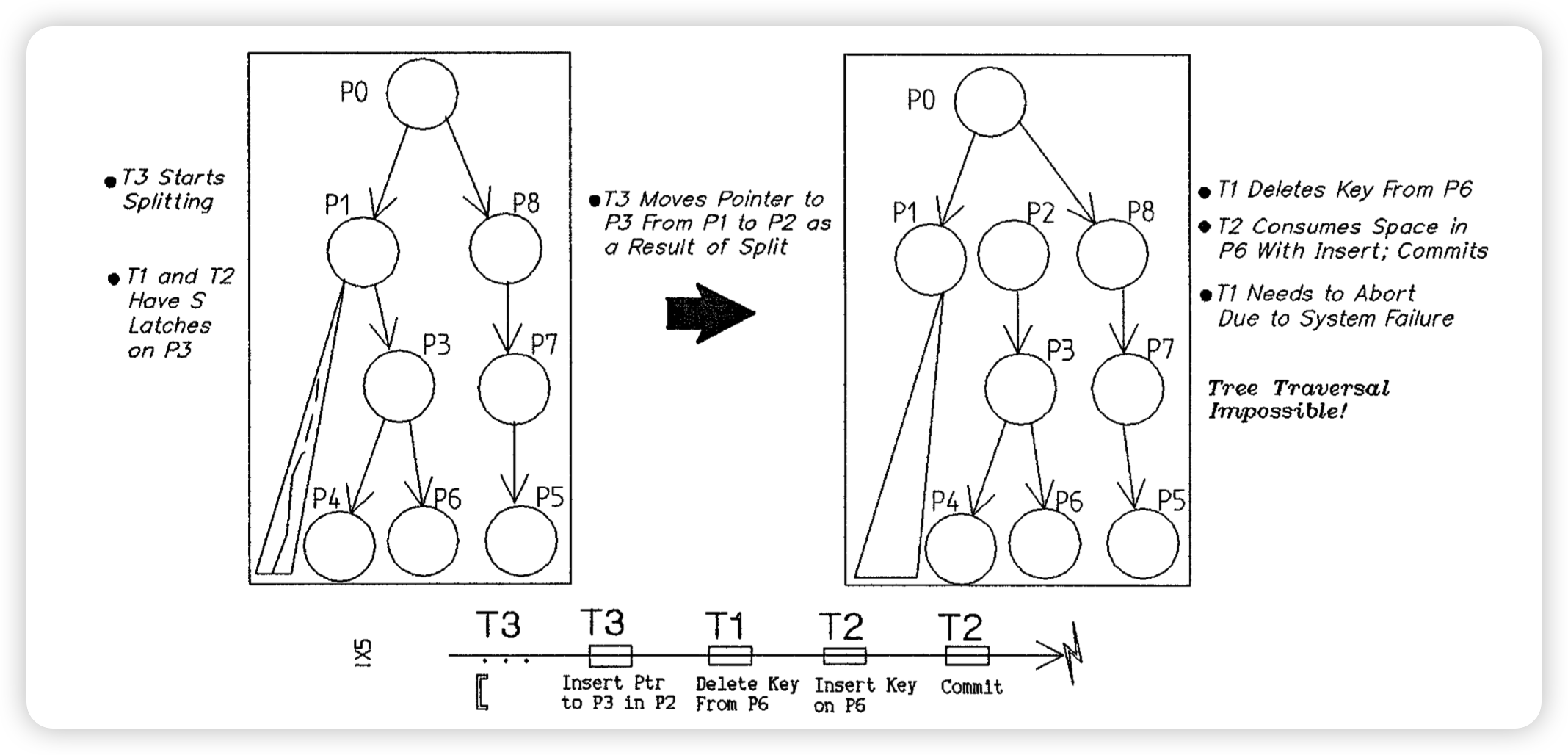
这里应该是在非叶节点没有用到BlinkTree的技术。执行的顺序是T3进行SMO,将P3的指针从P1移动到P2.然后T1删除了P6中的一个元素,T2在P6中插入了一个元素,然后Commit了。这个时候宕机了。那么恢复的时候我们就需要先把T1回滚掉,即把数据从P6中插回来,然后再回滚这个SMO。
但是问题在于,P6可能已经满了插入不进去了,导致我们这次回滚需要做逻辑Undo。但是由于SMO没有被回滚,导致我们没办法从root重新下降。(如果是blink tree 就可以,而且ARIES/IM用的就是类似blink tree,所以感觉是没啥问题的)
解决问题的办法就是在这种可能需要逻辑回滚的情况下,保证树的一致性,也就是POSC
ARIES/IM中列出了这些情况:
If an operation performed originally at time t1 needs to be undone at time t2, then during such an undo, tree traversal is performed only if page-oriented undo cannot be performed due to
- lack of enough free space on the original page to undo a key delete, thereby necessitating a page split SMO
- the key definitely does not belong on the original page anymore: in the undo of a key insert case, the key is not on the page anymore (caused by interleaving page split SMO)
- it is ambigious whether the key belongs on the original page or not: undo of a key delete case - the original page is still a leaf page but the key to be put back is not bound on the page
- the undo causes the original page to become empty, thereby necessitating a page delete SMO: undo of a key insert case - since at the time of the original insert there must have been at least one other key on the page. it means that there must have been a delete of a boundary key in the time between t1 and t2
翻译一下,undo的时候做插入导致SMO,由于中间的SMO操作导致key不在这个page上了,或者undo的时候做删除导致需要SMO
所以要undo就必须做逻辑undo(其实第四点我感觉可以先删除,再做SMO,但是这个SMO可能作用于一个不一致的树上,所以不行)
那么为了保证做逻辑undo时树的一致性,我们在执行上述操作的时候必须保证POSC
第一点就是通过delete bit来保证的。如果有其他的插入请求遇到的并发的删除请求的话,他就会先要求POSC,来保证后续对于delete的undo会看到一个一致的树。
第二点则不会有任何问题,因为这个SMO一定被回滚了,或者完成了。所以我们看到的一定是一个一致的树,只不过由于SMO导致page-oriented log失效了而已。
第三点,我们需要保证在修改boundary key的时候要满足POSC。所以在删除操作发现要修改boundary key的时候,要获取SMO lock保证POSC
第四点也不会有任何问题,因为如果这里undo需要触发SMO,中途一定出现了boundary key deletion。所以在t1到t2之间一定有POSC。
而对于算法中的SMO bit来说,是为了防止在SMO结束之前有人操作的SMO相关的page。由于SMO不是原子的,所以后续的Undo就会很难做。所以我个人感觉是为了简化undo。否则如果SMO是原子的话(MTR),那么上面的逻辑都可以省略掉,因为任何时刻树都是一致的。

文章评论