An Analysis of Concurrency Control Protocols for In-Memory Databases with CCBench
本文就是总结了一下之前比较经典的CC protocol,以及他们使用的优化。并将他们集成到了一个统一的CCBench中来做测试。
但是作为读者来说我们读的核心不在于他的bench,而是他所提炼出的这些cc protocol的关键点
Preliminaries
先回顾一下这几个协议
Silo
Silo的核心有两个,一个是避免读对内存造成影响(比如TO会在读的时候更新tuple的read timestamp)。另一个是通过基于Epoch的提交来实现parallel logging,以及实现pre-commit(其实这个地方严谨的说法应该是可以让事务读到pre-commit的状态)。
(从OCC的角度来看,原始的OCC也不需要我们更新读集。所以Silo高性能的关键其实在于他的pre-commit)
这种不会更改内存状态的读叫做InvisibleReads
TicToc
tictoc通过data-driven timestamp management,根据事务的读写集合计算出一个ts。从而避免的TSO的瓶颈问题,同时获得了更大的调度空间。
然而相对于Silo来说的话,则是tictoc会更新读集,从而可能引发大量的Cache Invalidation
MOCC
MOCC我没有看过,根据论文介绍是结合了悲观和乐观的并发控制。还不太清楚和Hekaton的区别
Cicada
Cicada用本地时钟来分发时间戳,将start ts作为事务在serial order中的位置。并且不会处理写写冲突。write intent可以根据txn ts的顺序插入到版本链中
Cicada应用了很多的优化。比如读的过程中可以提前abort。随着时间推进,会最终将最新的版本内联到main table中,从而避免indirection。
Cicada的GC则是worker thread做协助性的GC。每次事务结束都会尝试GC。从而尽可能的减少内存的开销。
AdaptiveBackOff会适应性的修改回退的时间大小,从而减少高竞争情况下事务的abort率
Cicada根据他的时间戳机制,会在提交阶段写入write intent的时候,根据他的ts来排序。(他认为ts较高的元组更容易受到冲突,从而提前发现,并abort事务)
SSN
据说是去检测dangerous structures来abort事务。不太清楚和PG的SSI的区别是什么
CCBench
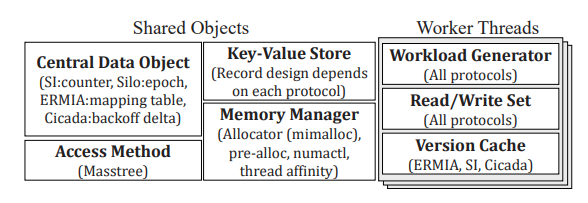

这个table是CCBench提供的优化以及原文所使用的。比如Cicada的GC就可以应用到其他的MVCC系统中。

这里是对于上面优化的一个解释。其中AssertiveVersionReuse和ReadPhaseExtension是CCBench单独提出来的。
Analysis
说一下他的结论
cahce line conflict,这个结论比较常见了,多核架构下同步缓存需要时间
cache line replacement,当数据多的时候,memory footprint会变大,从而导致缓存命中率低
跨越socket的读写会导致L3 miss。所以InvisibleRead是一个比较关键的特性。即避免读操作写元数据,进而导致缓存失效
不能说Wait和NoWait那个更好,而是应该区分情况。当txn size变大的时候,Abort开销变大,这时候Wait会变得更好。而由于某些未知的原因,Silo的NoWait表现的比Wait更好。(并且在2PL的情况下,Wait要求对上锁有一个全序关系来防止死锁)
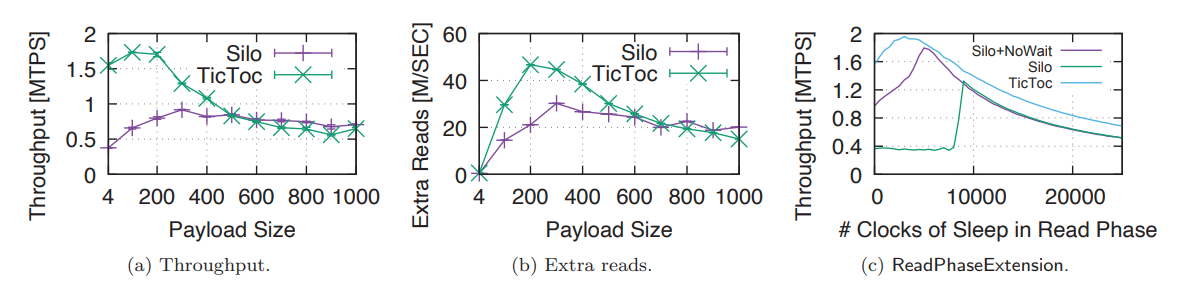
这个图表示的意思是Payload size变大的时候,性能可能提高。原因是较大的payload size导致read phase会变长。从而导致了并发的进入validation阶段的事务变少,进而减少了abort。(作者原文说的是read validation failures decreases,但是我感觉增长read phase不会减少failure,反而会增加,因为我们更有可能读旧数据。如果说论点是减少了由于上锁导致的abort可能还更好一点)
有关Version maintaince的结论。即便是使用了RapidGC,长事务也会很大程度上影响性能。TNM的那个Scalable GC貌似解决了这个问题,用更细粒度的GC。
文章中也提到了一个idea是可以利用Thomas写规则来减少version的数量。(但是不清楚效果,并且需要追踪ReadTS。貌似被generialized了以后叫做non-visible write。有点Immotal write的感觉?)

文章评论