High-Performance Concurrency Control Mechanisms for Main-Memory Databases
这次换一个记录的方式。点出思考和关键点,而不是类似翻译似的看文章
single version locking works well when transaction are short and contention is low
The multiversion schemes have higher overhead but are much less sensitive to hotspots and the presence of long-running transactions
traditional single-version locking is “fragile”. It works well when all transactions are short and there are no hotspots but performance degrades rapidly under high contention or when the workload includes even a single long transaction.
First, we propose an optimistic MVCC method designed specifically for memory resident data. Second, we redesign two locking-based concurrency control methods, one single-version and one multiversion, to fully exploit a main-memory setting
如果一个txn的读和写逻辑上发生在了同一个时间,那么他就是serializable的。
SI不是serializable的,因为他的读发生在了txn的开头,而写发生在了txn的结尾。
要保证serializability,我们需要保证两点:
1. Read Stability:
说的是读的一个tuple的一个版本在事务提交之前不能发生改变。防止lost update。我们可以在读的时候上读锁。或者是在提交的时候去检查这个版本没有被更新。
2. Phantom Avoidance
也是希望保证view不变,这个的视角主要在phantom上。即相同的scan不会返回不同的结果。我们可以在table或者index上锁。或者是在提交的时候重新scan
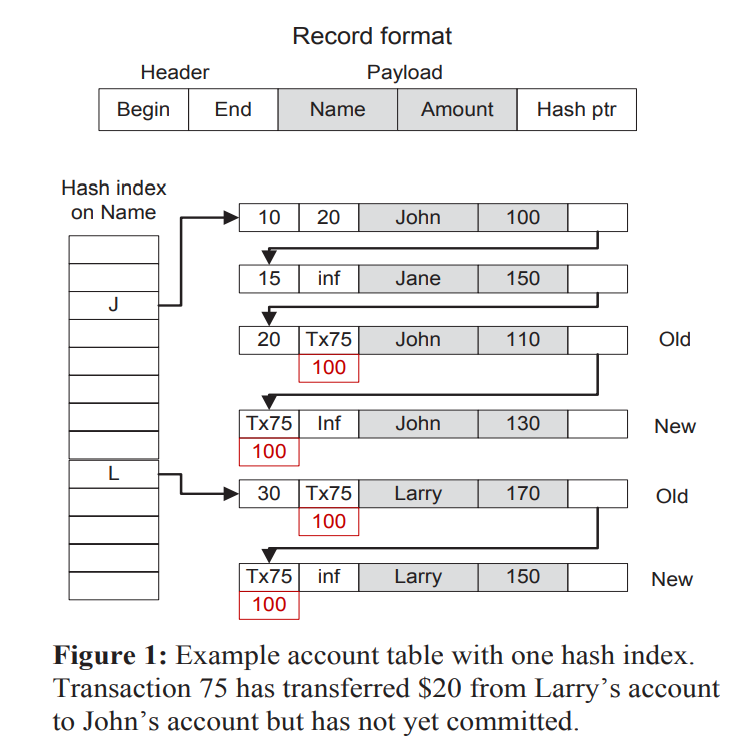
读可以直接遍历版本链。找到覆盖当前read ts的时间段的那个版本,读即可。
写的话则是在老版本的结束时间和新版本的开始时间上写入txn id,表示获得写锁。
提交的时候则将txn id替换成commit timestamp。(用一个bit来区分这个域里的是txn id还是commit ts)
读得时候有这么几种情况:
* begin和end field都是timestsamp,直接检查是否有重合即可。
* begin field是txn id
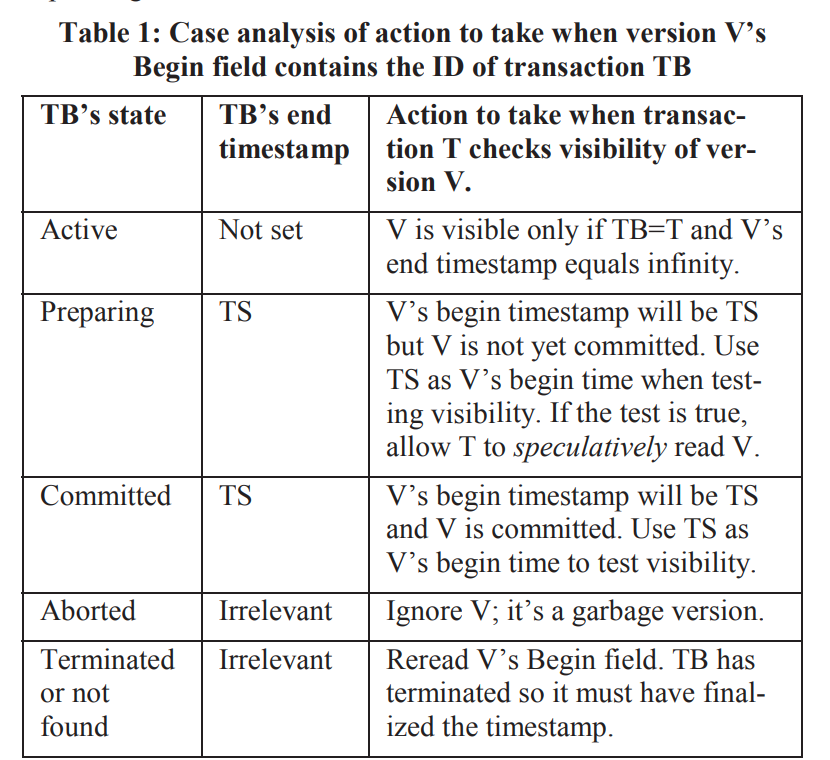
应该是要去事务表里检查txn的状态。根据这个事务的状态来判断当前的动作。
- end field是txn id
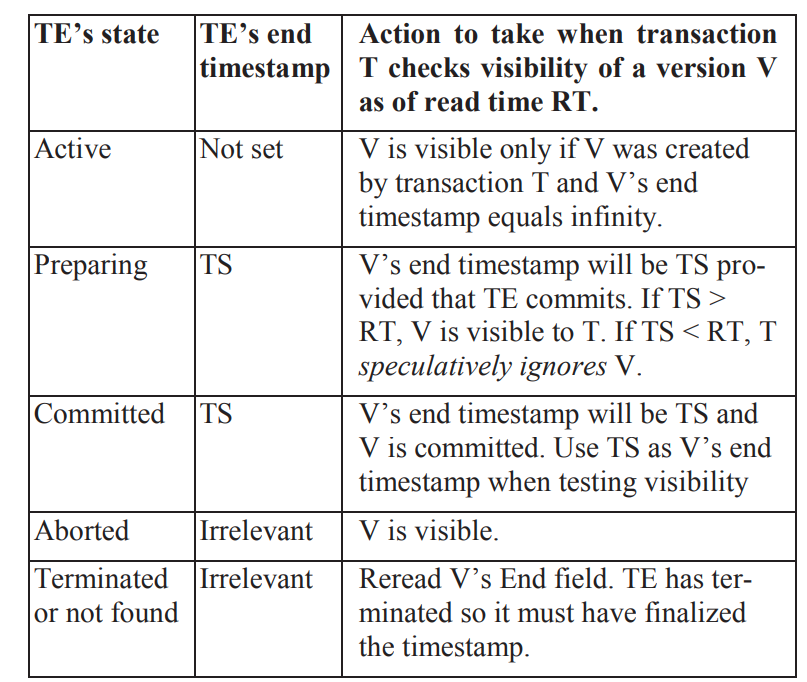
仍然是需要去根据事务的状态来确定
他这个TE为active的时候的判断有个比较反直觉的。就是只处理了同个事务多次更新的情况。而对于其他的事务来说,如果TE是active的话,应该可以直接读到这个版本。
更新的时候先通过CAS把txn id换到end field中。然后再把新的版本安装进来。失败的话则需要abort
commit dependencies通过register and report来实现。注册依赖的时候就在被依赖的事务上面注册一个事件,当被依赖的事务提交或者abort的时候就会通知依赖他的事务。
wait关系只存在于年轻事务去等老事务。所以不会出现死锁。
optimisitic transactions
原始的OCC有两种方案,backward validation和forward validation。这里使用的是forward validation
检查的时候,由于我们已经避免了WW conflict。所以只需要处理读的版本有没有被其他的事务修改。这里检查的方法就是去检查这个版本是否还对于当前事务可见。
只要txn将自己的state设为committed,其他人就可以看到他的版本了,而不需要额外的write phase
读谓词分开成两个,一个Ps是用在索引上的谓词,比如BTree上的range,或者hash index等值谓词。还有一个就是剩下的谓词(下推来的谓词)
只有当一个版本的end ts是inifinity,或者他的txn id是一个aborted的txn的时候我们才能更新。对于start ts来说他可以是一个正在进行commit的事务。这样我们可以做speculative updates
更新的写入成功后就可以将其写入到版本链中了。比如插入到clustered index中。abort也比较容易,修改start ts即可。
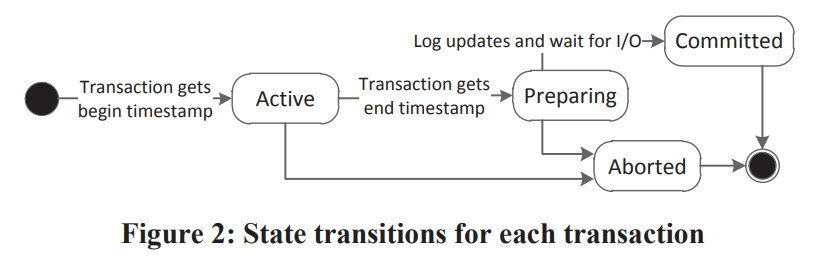
txn的preparation phase有三个步骤。分别是:
* 读检查,即检查读到的版本的可见性,以及phantoms。检查读集的版本,以及重做ScanSet中的scan。
* 等待提交依赖
* logging

version的生命周期。
RR:验证的时候只验证Read Stability。(可以防止部分的write skew)
RC:用当前时间来作为ReadTime,从而保证读到最新版本。
SI:不需要Validation
Pessimistic Transactions
pessimistic txn会在读的时候上锁。
txn维护了三个集合:
* ReadSet
* BucketLockSet(读到的hash bucket,应该类似谓词锁,但是resize要怎么处理?)
* WriteSet
我们有两种锁。record lock和bucket lock
record lock放在version上,用来保证read stability
bucket lock放在has bucket上,用来防止phantom
(因为prototype里实现的是hash index,我们可以使用range lock在sorted index上实现类似的谓词锁)


(等待获得锁要怎么实现呢?如果内嵌这个标志的话可能需要我们忙等待?)
bucket lock中有这两个


为了防止锁带来的blocking,paper中提出了一种机制叫eager updates
在获得锁的时候,我们可以直接获得这个锁,并添加一个依赖。在我们获得end ts之前,要等待所有的依赖都消失才行。这里的依赖说的是比如一个写者要获得写锁,但是这里有读者,他就会先拿到写锁,然后添加对这个version上的依赖。当所有的reader都退出后,他就可以成功获得写锁。
当一个更新事务TU尝试获取写锁的时候,他会判断如果当前的ReadLockCount大于0,他就会获取在这个version上的依赖,并等到version上的ReadLockCount为0的时候才能开始提交。
如果另一个读事务TR来了,他会判断version上是否有写锁,并且他自己是不是第一个读者,如果是的话,他就会让TU在这个version上等待。他会增加TU的WairForCnt。
当TR释放锁的时候,他会判断如果version上有写锁,并且他是最后一个读的人。他就要减少TU的WaitForCnt。TR会原子的将ReadCnt设为0,并将NoMoreReadLocks设为True,防止后续的读者继续阻塞TU,从而让TU继续执行。
(TU更新完之后可以原子的将NoMoreReadLocks以及write lock设为0)
bucket lock的作用不是去阻止有事务添加新的版本,而是为了防止这些新的版本对TR可见。即当TU尝试提交的时候,他必须等TS上的人释放的锁之后,才能获取end ts。从而保证了TS上的事务不会看到TU的更新
其实可以看到这些依赖就是RW依赖。我们允许了对某一个版本的并发的读写,但是就需要追踪起RW依赖,来保证提交的顺序。
在遍历版本链的时候,对于那些我们读不到的version,我们需要添加RW依赖,这些事务必须要等我们提交后才能提交。
有关deadlock,就是构建等待图去判定。
悲观和乐观的并发控制可以并存。当乐观事务尝试更新的时候,如果这里读锁,他就会增加一个RW依赖。当他插入新版本到bucket的时候,他也会在读事务上添加依赖。
这样乐观事务的写就不会影响到悲观事务的读。而对于乐观事务的读,则会在最后去验证,所以不受悲观事务的影响。
说白了就是乐观事务检测RW冲突可以兼容悲观事务,而悲观事务检测RW冲突要求上锁来保证写不会影响读,所以乐观事务的写也需要上锁。

文章评论