bthread_id
这里的bthread id不是标识bthread的identifier,而是用于同步的一种数据结构
我们之前在channel中看到过他,用来做同步的brpc
brpc中也有相关的文档

这么看他的名字叫rpc id更合适一些
这里粘一下文档的东西
bthread_id包括两部分,一个是用户可见的64位id,另一个是对应的不可见的bthread::Id结构体。用户接口都是操作id的。从id映射到结构体的方式和brpc中的其他结构类似:32位是内存池的位移,32位是version。前者O(1)时间定位,后者防止ABA问题。
bthread_id的接口不太简洁,有不少API:
- create
- lock
- unlock
- unlock_and_destroy
- join
- error
这么多接口是为了满足不同的使用流程。
- 发送request的流程:bthread_id_create -> bthread_id_lock -> ... register timer and send RPC ... -> bthread_id_unlock
- 接收response的流程:bthread_id_lock -> ..process response -> bthread_id_unlock_and_destroy
- 异常处理流程:timeout/socket fail -> bthread_id_error -> 执行on_error回调(这里会加锁),分两种情况
- 请求重试/backup request: 重新register timer and send RPC -> bthread_id_unlock
- 无法重试,最终失败:bthread_id_unlock_and_destroy
- 同步等待RPC结束:bthread_id_join
为了减少等待,bthread_id做了一些优化的机制:
- error发生的时候,如果bthread_id已经被锁住,会把error信息放到一个pending queue中,bthread_id_error函数立即返回。当bthread_id_unlock的时候,如果pending queue里面有任务就取出来执行。
- RPC结束的时候,如果存在用户回调,先执行一个bthread_id_about_to_destroy,让正在等待的bthread_id_lock操作立即失败,再执行用户回调(这个可能耗时较长,不可控),最后再执行bthread_id_unlock_and_destroy
通过上面使用的例子我们可以看出来,我们通过lock和unlock来做互斥。在发送或者接受数据的时候,先lock住bthread id,然后执行逻辑。这样可以防止出现数据竞争的问题。(看起来就像一个mutex,加上了错误处理以及join的功能)
然后我们看代码他是怎么实现的
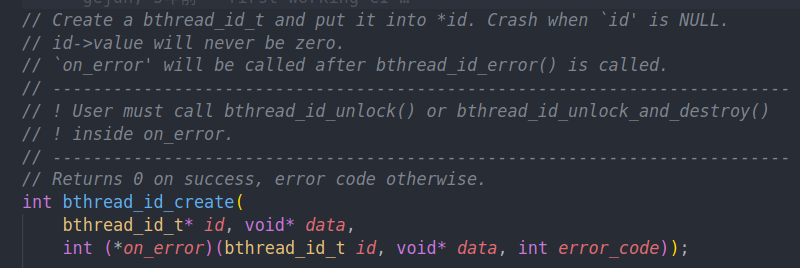
最基础的bthread id create
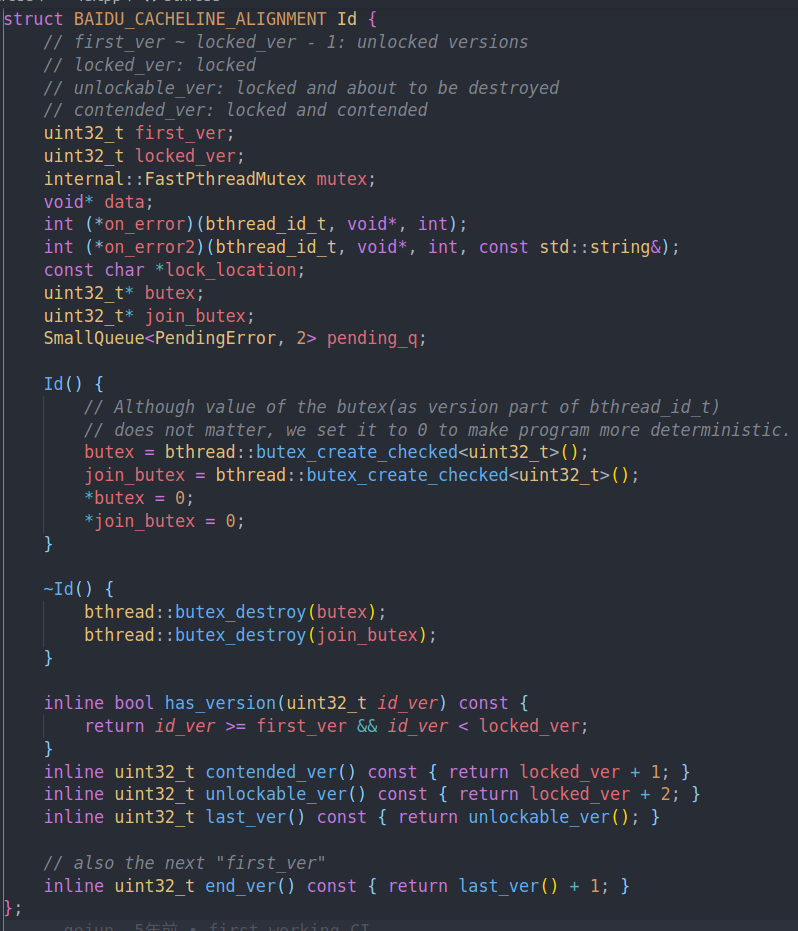
内部的Id结构。我们在外面索引的就是这个结构。
注释里写的比较清楚。从first version到locked version - 1是unlocked versions。
mutex应该是用来保护内部的变量,之后我们仔细看用法。然后两个用来处理错误的函数。
构造函数用来初始化两个butex,析构函数则是释放这两个butex。因为我们有阻塞,所以需要butex来帮我们做阻塞和唤醒
然后下面三个,contended ver,unlockable ver以及last ver在上面有注释。我们之后仔细看他们的含义
回到create中
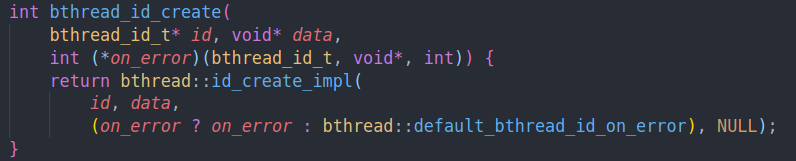
error2为null,error1如果为空的话,则设为default,default的作用就是调用unlock + destroy
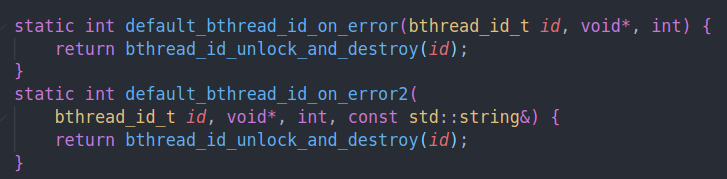
即归还资源
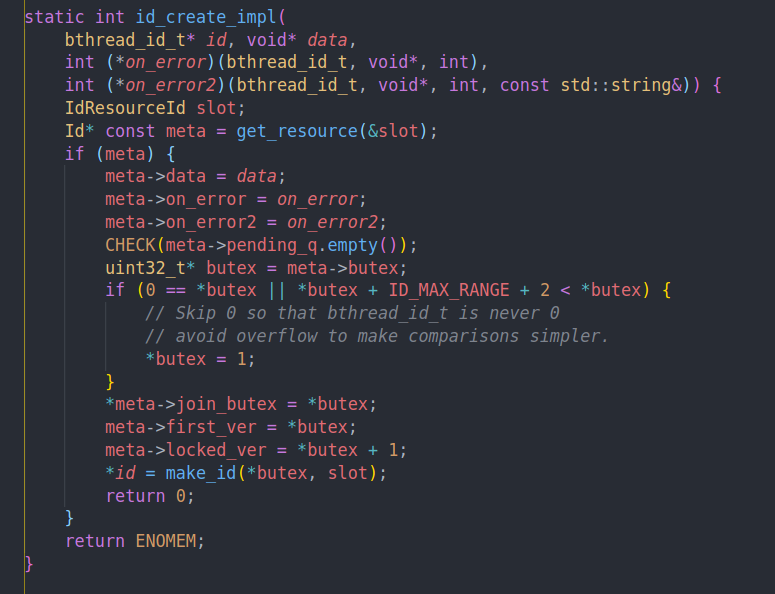
然后将传入的参数赋给Id这个结构
跳过0号版本,以及处理overflow的情况,因为bthread id可以通过range初始化,所以为了防止不断的使用导致butex溢出。我们最开始判断的时候就排除掉这种情况。
根据这个最初的版本构造id。并初始化first ver,locked ver,以及join butex
在去看ranged之前,先看看他是怎么用的
即lock以及unlock
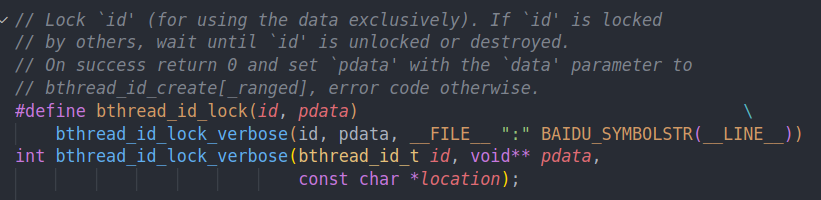
lock id,并将pdata置为data
他会调用对应的range版本,只不过range为0
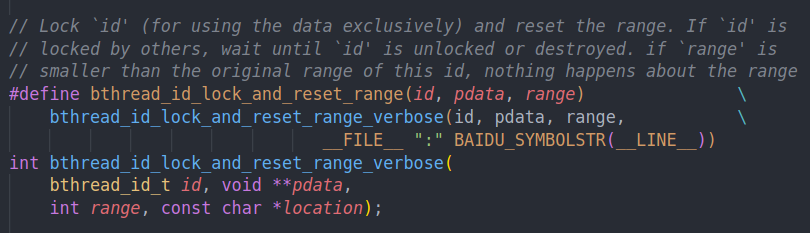

通过mutex保护临界区
这是一个整体的大锁。所以文档中有说bthread id可能比mutex慢一些
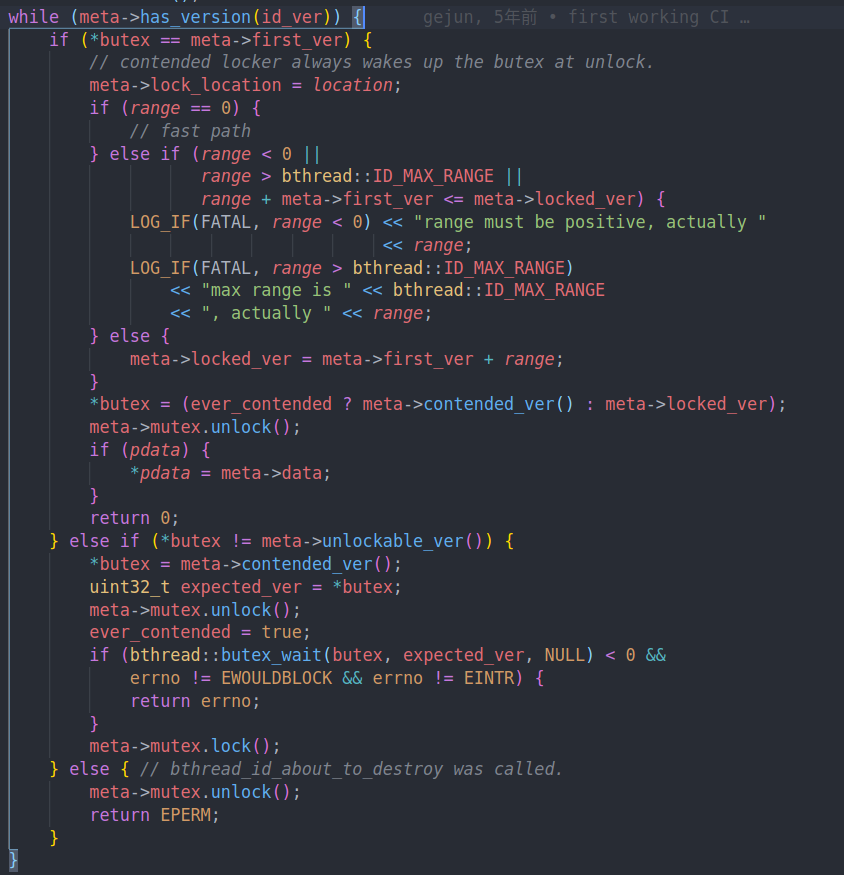
通过has version判断我们当前的版本是否有效,因为has version判断的是version的版本是否在first ver到locked ver - 1之间。表示unlocked的状态。
判断如果当前版本是初始版本的话,我们会更新locked ver,也就是更新被锁住的版本。并且中间会判断锁住的版本只能向前移动
然后更新butex,也就是当前版本。如果有过冲突,则更新为contended ver,也就是locked ver + 1,否则则更新为locked ver
如果butex不为unlockable ver,说明出现了竞争,有人已经上了锁。我们会通过butex的原语去等待。然后再回去重新判断。
可以看到能够成功锁住的情况只有在版本为first ver的时候才可以。
我们结合unlock去看一下他的作用

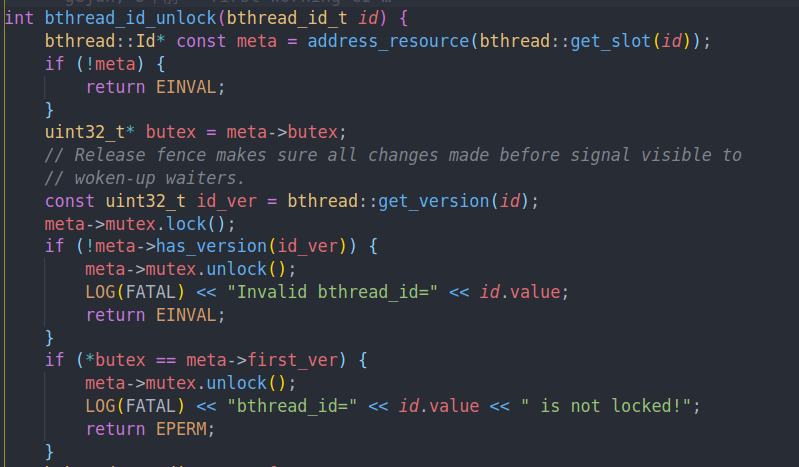
判断一下错误的情况。has version中是有效的版本。并且first ver表示unlocked
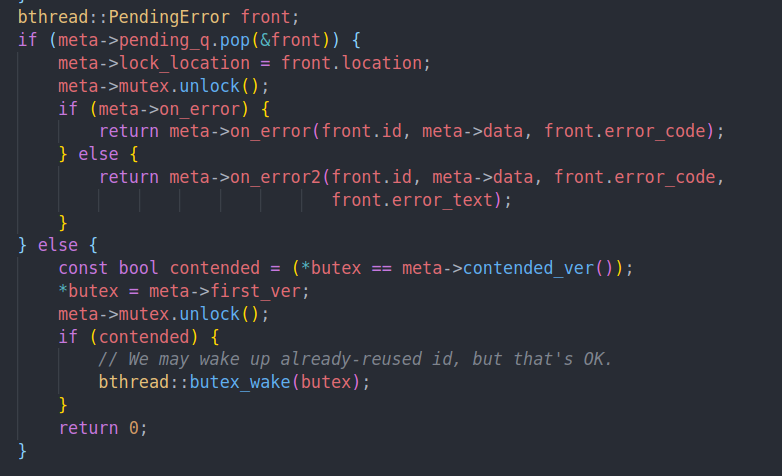
之前提过,如果有error的时候我们需要锁住id,但是如果这时候id上锁了,我们就需要把它放到pending queue中,等待解锁的时候去处理。
这里就会尝试从queue中pop一个error然后处理。如果有后续的error,在on error内部会调用unlock处理后续的error
如果没有error的话,就将butex设置为first ver,并判断如果存在contend的话就唤醒其他的线程。
从这里可以看出来锁定的基本过程。我们会确定locked version,然后锁定在这个版本上面。如果有冲突的话,就锁定到contended version中。
然后后续调用unlock的时候就会判断,如果锁定到了contended version中就调用butex wake。否则就只是简单的放锁。其实就是通过一个额外的版本来省略了减少无意义的butex wake
回过去看ranged bthread id的话就可以看到,唯一不同的就是初始化locked ver不是butex + 1,而是butex + range了
所以对于普通的版本来说,我们只有first ver,即未锁住,locked ver,表示锁住。contended ver,表示有竞争时候的锁住,还有unlocked ver,表示即将destroy的bthread id
try lock的思路也很简单,就是没有了butex wait而已。

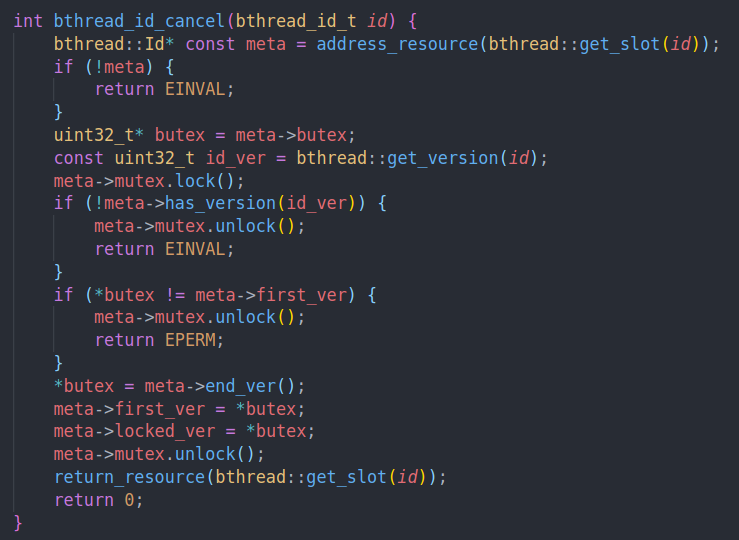
cancel的作用是销毁一个bthread id
销毁的作用就是将版本设置为end ver,即为locked ver + 3。同时这也是下一个bthread id的初始版本。
我们只能cancel未上锁的版本。
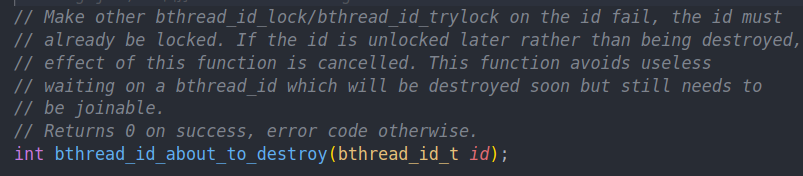
about destroy的作用是阻止新来的lock。如果后续我们调用了unlock,那么abort destroy的效果会消失。
这里的实现其实可以根据前面的代码推导出来,就是将butex版本设置为unlockable ver
然后是我们比较期待的join,同步rpc就是通过join实现的

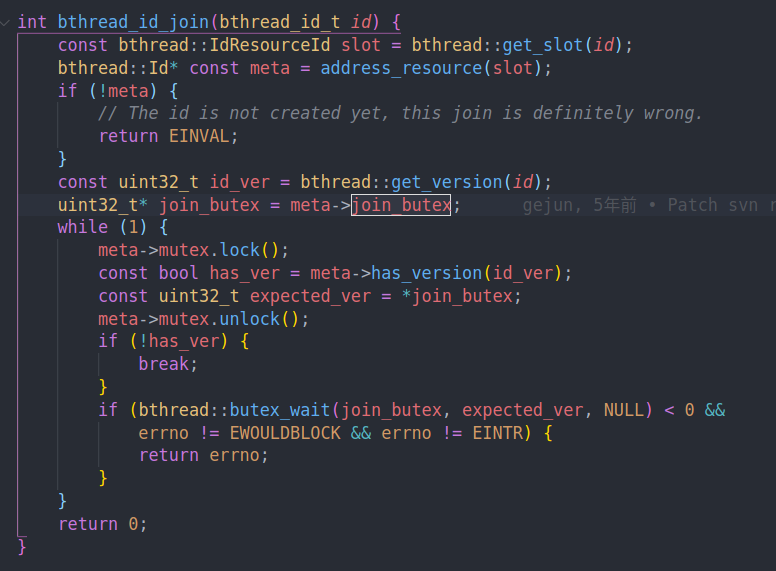
只要has version为真,即id version在first ver和locked ver之间,我们就一直等待。直到bthread id被销毁,这时候他会更新Id中的first ver以及locked ver,从而让判断失败,退出join
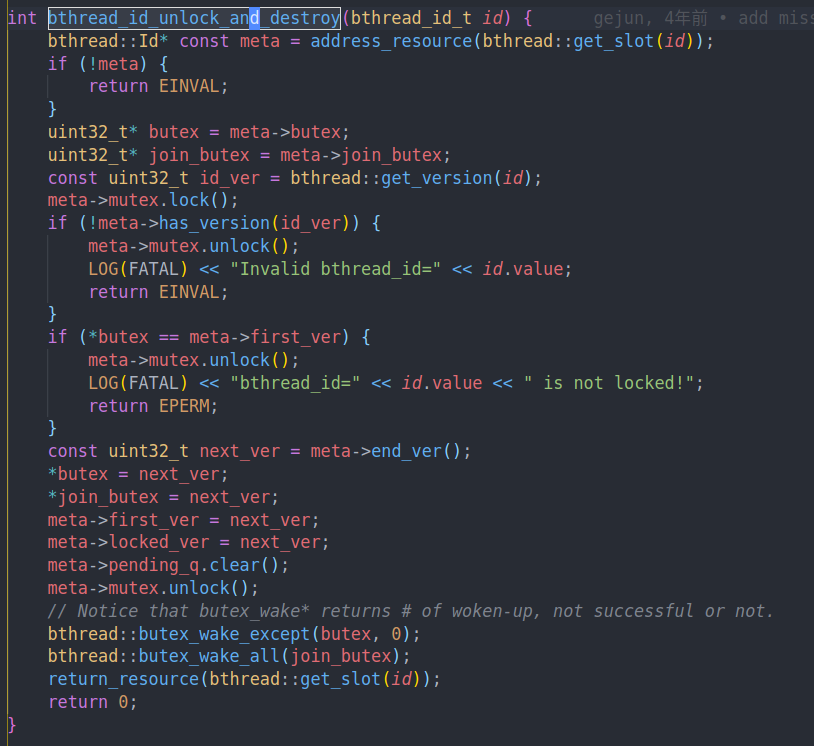
unlock destroy的实现和cancel非常相似,只不过我们会先尝试调用unlock,并且唤醒其他等待的worker。唤醒butex上的worker目的是让他们结束等待,因为bthread id已经销毁了。唤醒join butex的目的是唤醒调用join的线程。
所以从这里也可以看到butex和join butex分开的目的。一个是为了阻塞join的线程。一个是为了阻塞lock的线程。
最后还有一个error的处理
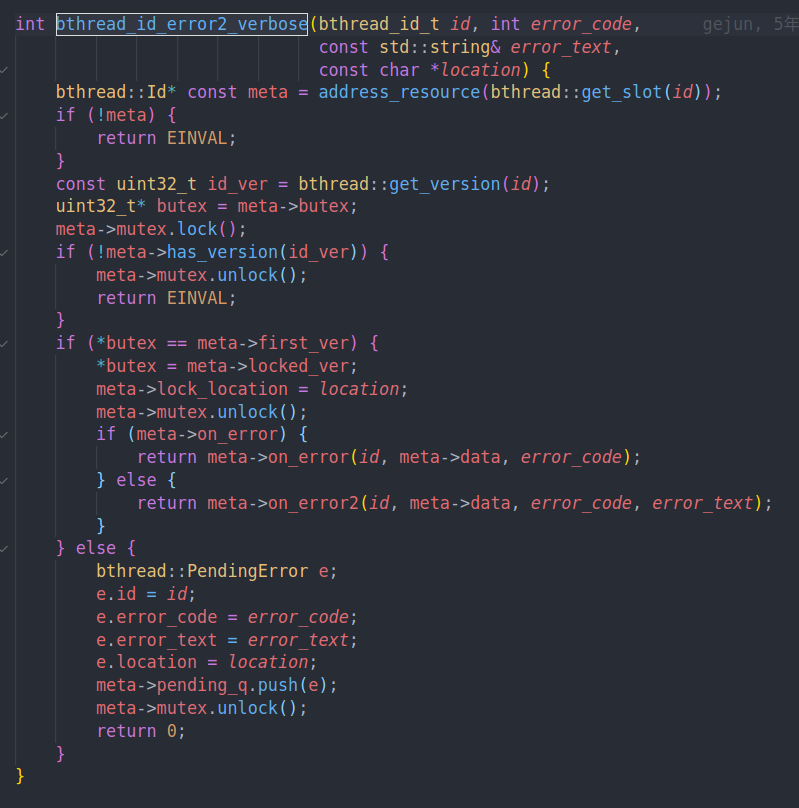
先判断版本是否合理。然后判断如果bthread id未上锁的话就上锁。并调用用户的回调。
否则的话我们不能获得bthread id的独占权,则我们进入到pending queue,等待unlock的时候再去处理。
bthread id的核心思路就是一种同步手段。核心还是一个butex。不同的是他的几个额外的处理。一个是通过join butex来实现join。一个是通过contended ver来判断是否冲突,减少butex wake的调用。
还有就是通过unlockable ver来阻止后续的lock操作,他的目的是在rpc结束的时候处理用户回调,这个回调可能时间比较长,为了防止阻塞其他的lock操作,调用about to quit来让其他的lock失败,这样我们可以正常执行回调。最后再调用unlock destroy
核心版本就是就是未上锁版本,上锁未竞争版本,即将退出版本。未上锁版本可以用来cancel rpc,上锁版本可以用来发送rpc以及处理返回值。即将退出版本则是处理回调。可以看到bthread id就是专门为rpc做同步的结构。

文章评论
全网把brpc bthread id讲得最容易理解的文章