ExecutionQueue
execution queue在brpc中已经有相关的文档。就在execution_queue.md中

可以看到这个execution queue最开始是实现多线程向同一个fd写数据。之前我们已经看到过他相关的机制了。就是通过原子交换来获得所有权。
execution queue的任务在另一个单独的线程中执行。并保证执行顺序和提交顺序一致。同时支持多线程并发提交任务。(这里的提交就是插入)
这个execution queue是泛型的,可以创建多个不同类型的execution queue
回忆一下核心原理。MPSC(Multi Producer Single Consumer)队列的插入和执行。插入是通过原子交换把任务换入到链表中。而执行则是让consumer通过反转链表的形式按插入顺序执行任务。
通过API去看一下execution queue是怎么使用的
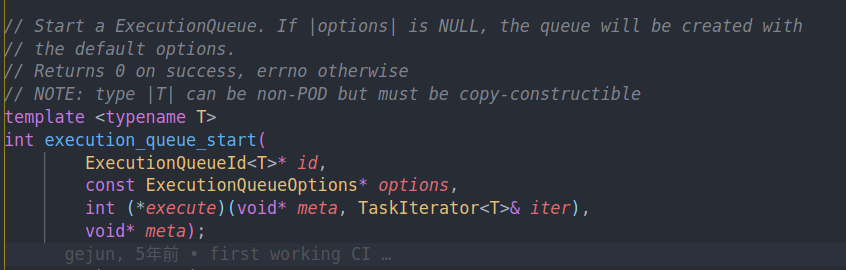
可以看到我们需要传入一个函数execute作为执行逻辑。
task iterator的作用就是去遍历已有的任务
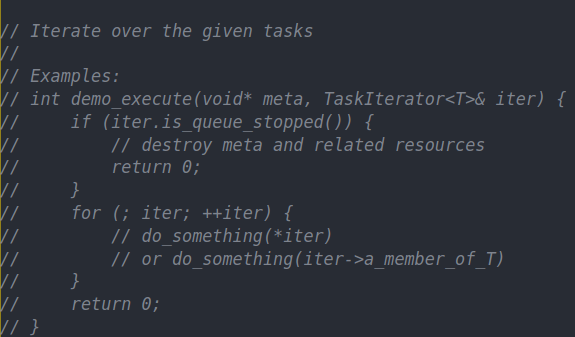
从这里可以看出来他的流程。每当队列发现有新的任务的时候,就调用execute,execute会遍历已有的任务,并处理他们。(可能是反转一次链表调用一次execute,也有可能把反转链表的逻辑藏在iterator中,iterator的任务是尝试pop任务,这就需要仔细看实现了)

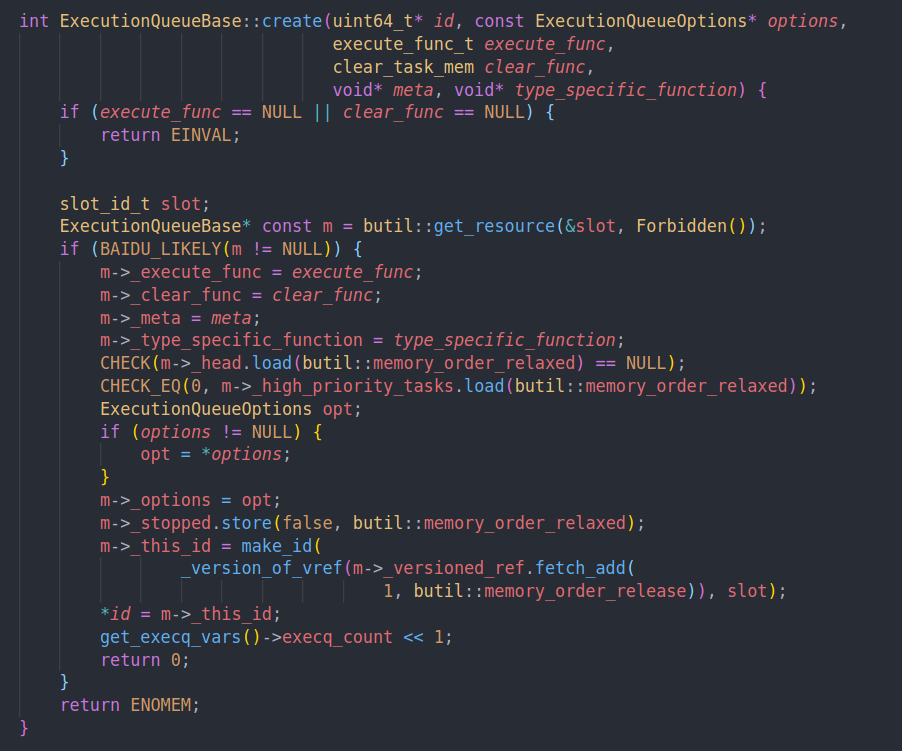
start会最终调用到Base的Create中
可以看到execution queue的id也是slot + version。用来快速索引+防止ABA问题的
核心就是三个function。execute func,clear func,以及type specific function
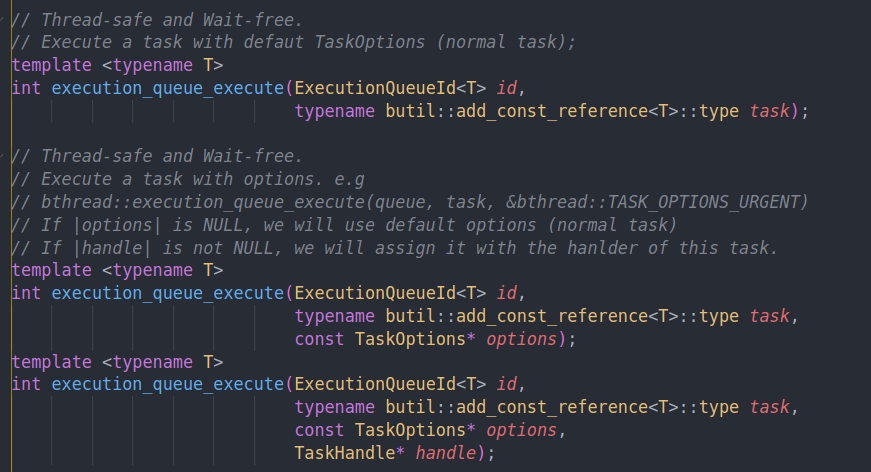
执行函数
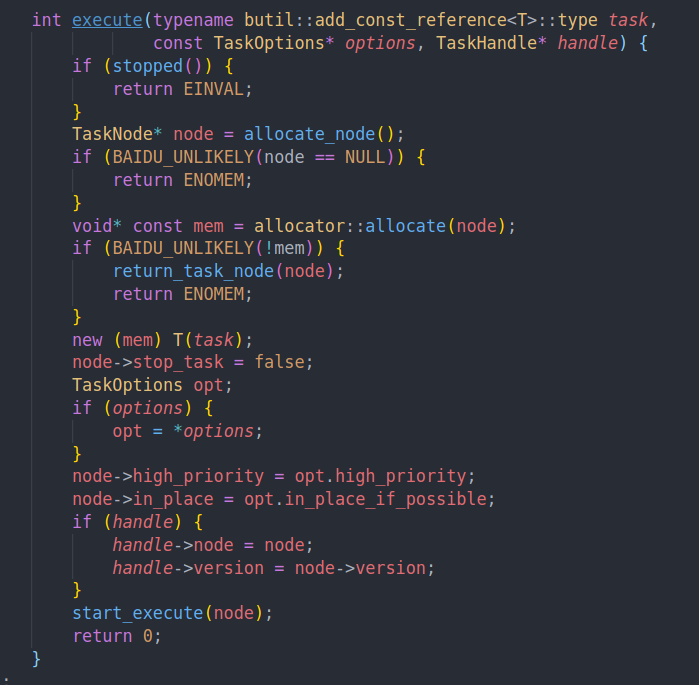
会调用到execution queue的execute中
task node的结构如下
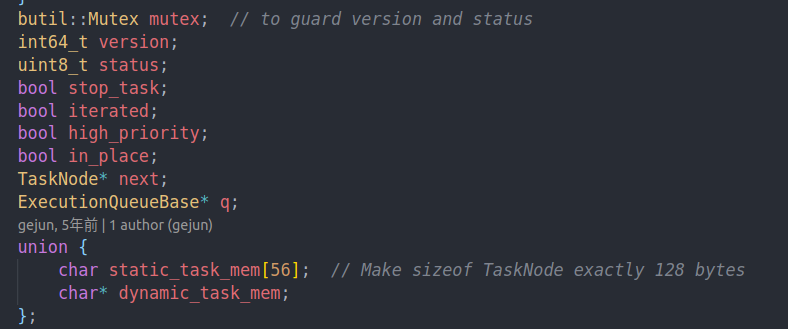
我们的allocate base有两种。
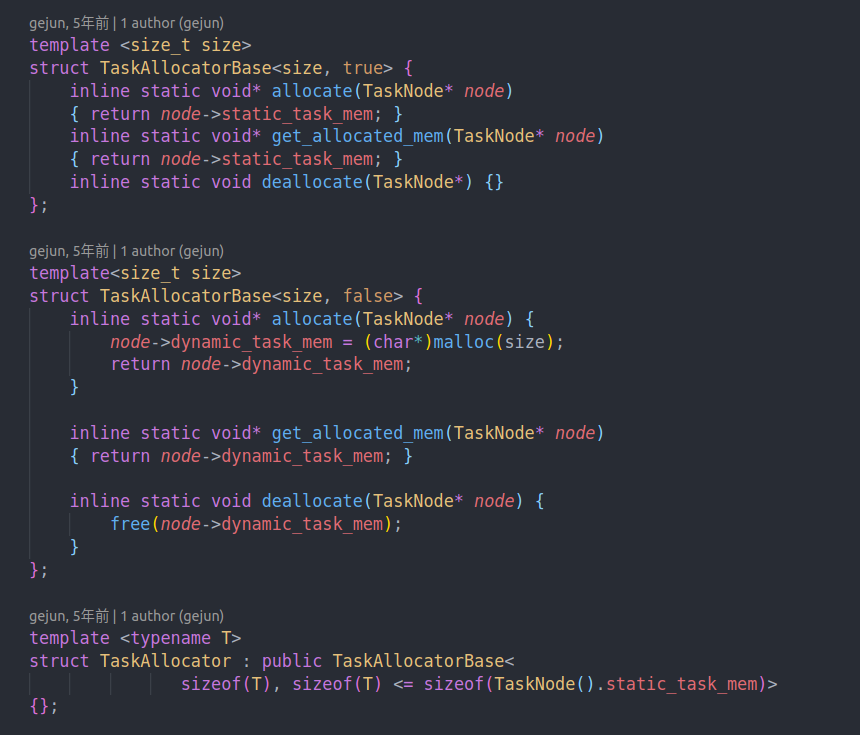
如果这个task的大小可以装入static task mem中,我们就会调用TaskAllocatorBase<size, true>
即直接使用static task mem。否则的话就会通过malloc分配对应大小的空间并赋给dynamic task mem
然后会到start execute执行逻辑
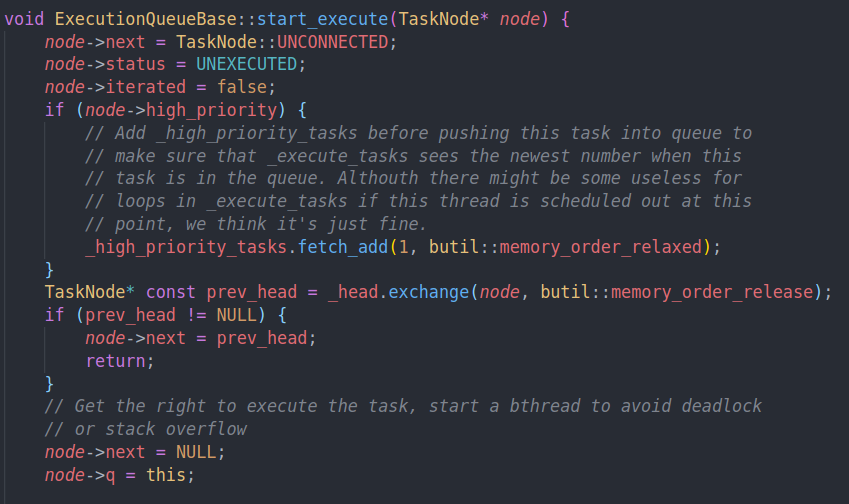
和之前的多线程写fd的操作是相同的。我们先把这个node的next设为null
如果他是高优先级任务就让优先级任务的计数器加1
然后和head进行交换
如果发现prev head不为空,说明已经有任务了,我们把链表接上然后返回即可
如果任务为空,我们则获得执行任务的权利。我们会开启一个bthread去执行新的任务。
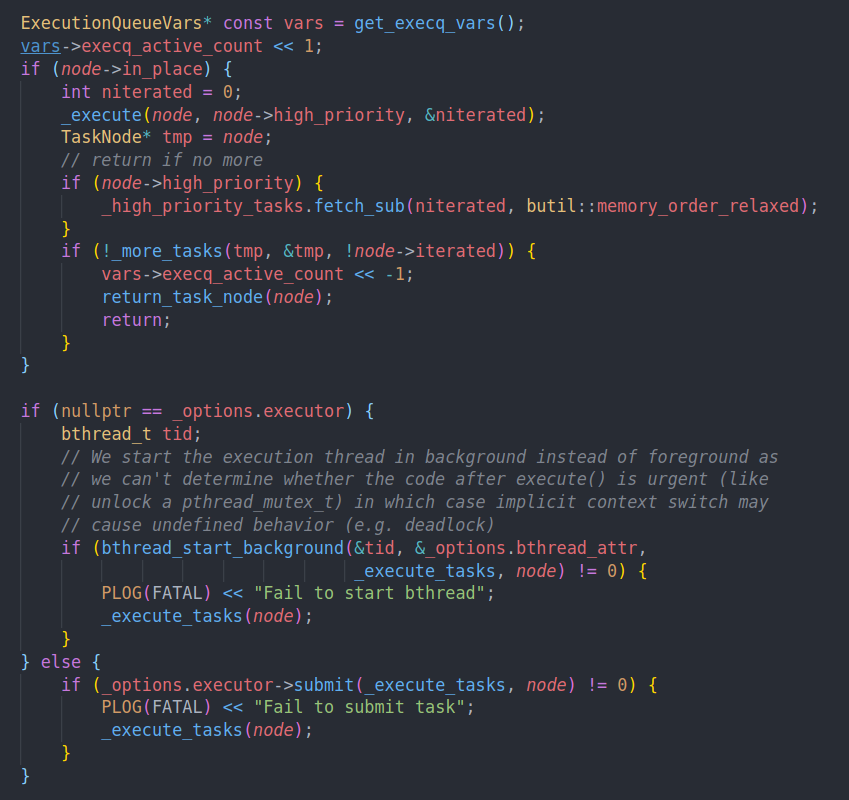
可以看到思路就是如果优先inplace的话我们就本地执行。然后通过more tasks判断是否还有更多任务。如果没有的话就返回
如果有更多任务的话,我们就会通过bthread start background开启一个新的bthread去执行
如果用户指定了executor我们就从executor上执行。否则就去bthread上。
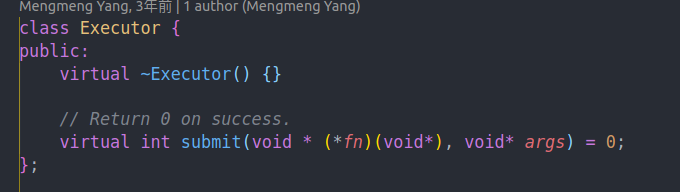
executor就是一个有submit的类。用来提交任务给worker
根据上面的start execute可以看到有3个核心的函数,分别是_execute用来执行任务,_more_tasks用来判断是否还有更多任务,_execute_tasks用来执行剩余的任务
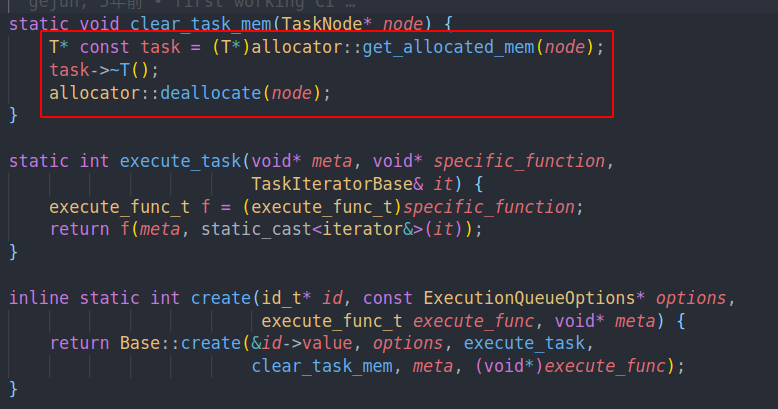
在这之前,看一下之前提到的两个辅助函数。execute task的作用就是执行specific function,并且将iterator base转化成对应类型的iterator。clear task mem则是调用对应类型的allocator然后释放内存。
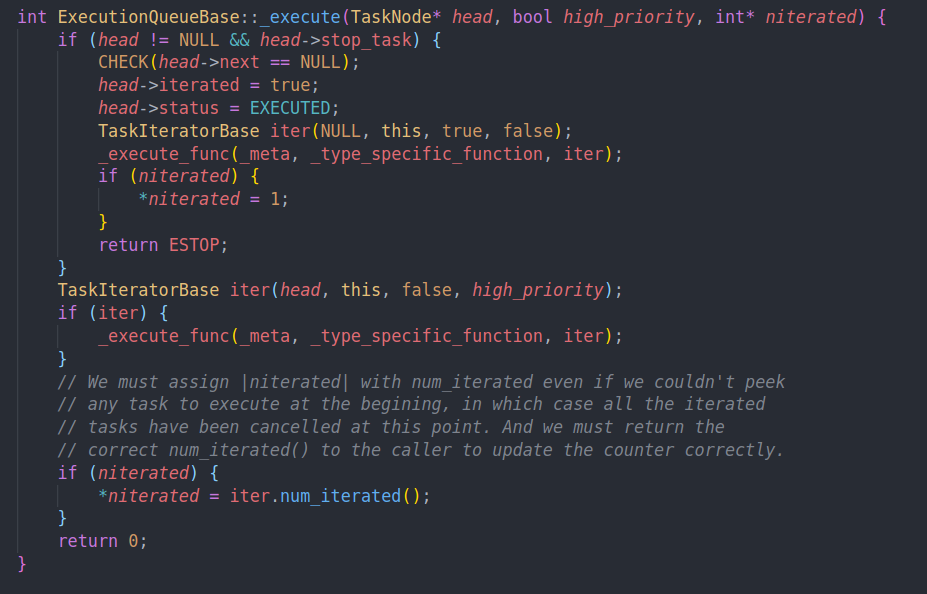
execute中,思路就是创建task iterator,然后执行任务
这里会判断如果有stop task,则表示我们需要停止任务了。我们会返回ESTOP(一个疑问是为什么不直接返回呢)
这里的more tasks和之前提到的多线程写入fd的判断是一样的
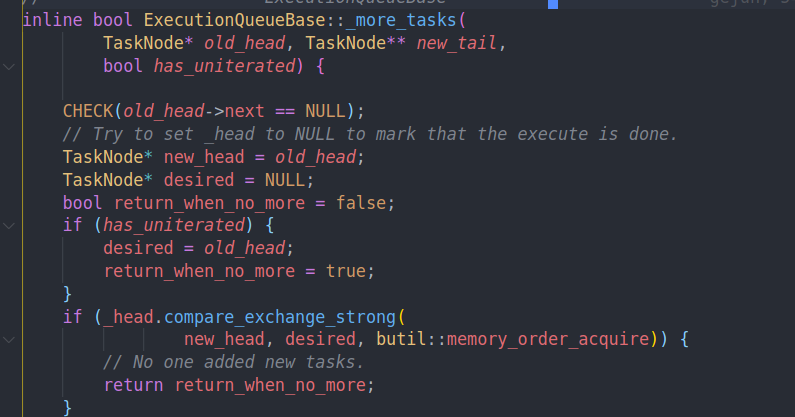
先通过原子交换判断是否有新的任务。如果没有的话就直接返回。否则的话新的head会被存在new head中
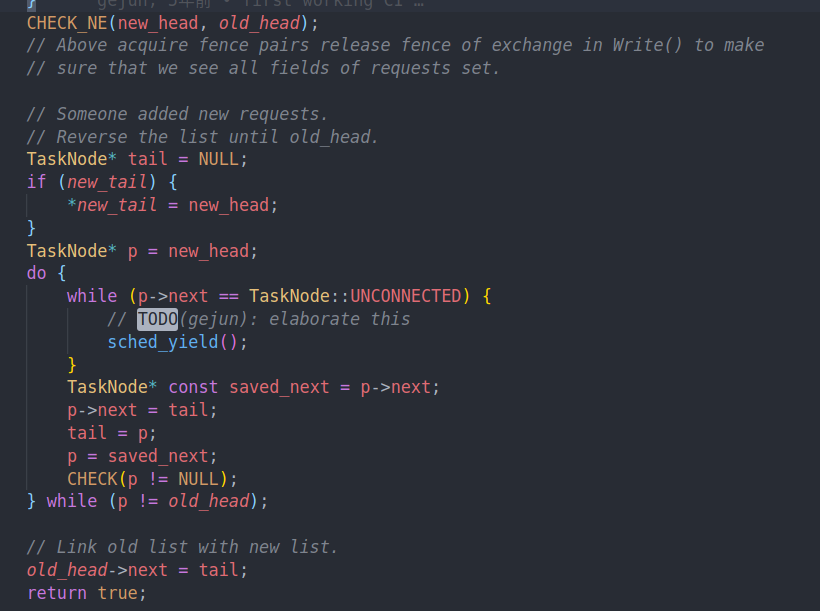
然后我们将新的链表进行反转,并记录tail的位置。目的是下次判断就从tail开始
这里的判断是如果p的next为null的话,说明他已经通过cas把自己换入了,但是还没来得及接入链表。所以我们yield出去等待他完成
直到我们遍历到了old head,才能说明这一段链表已经成功被反转了
最后把old head接到新的链表上
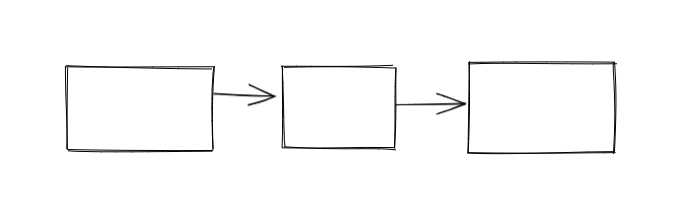
比如我们最开始的链表是这样的
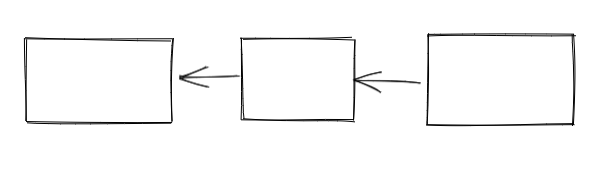
反转后开始执行,在我们反转的过程中或者执行的过程中新的任务插入的话,就会变成这样
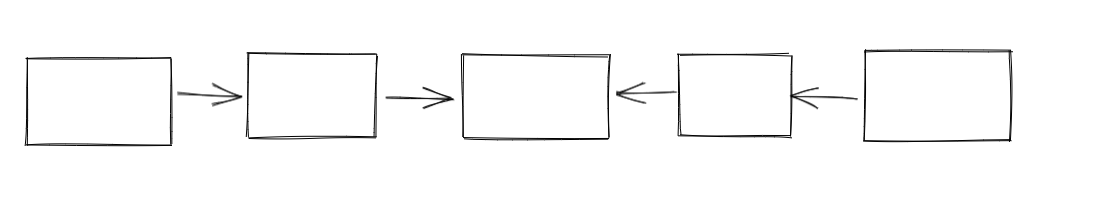
这样我们记录了old tail,就可以反转old tail到新的head这一段的链表

从而按序执行任务
然后就是执行批量任务的函数_execute_tasks
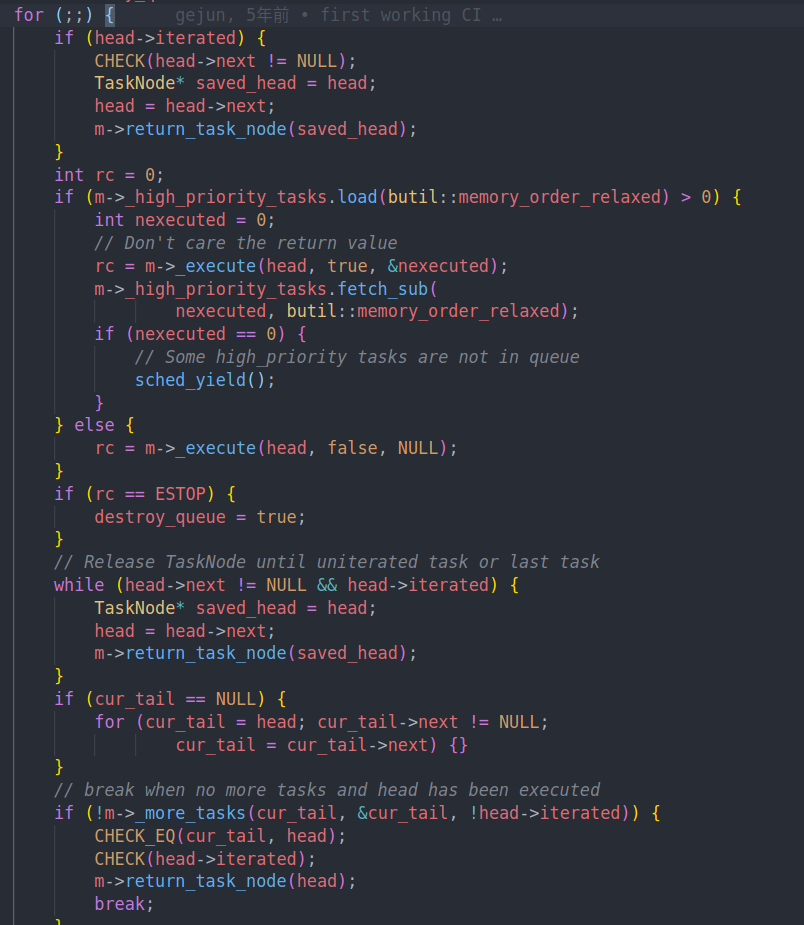
这里就是执行的核心逻辑。
如果head已经被遍历过了。我们释放这个head
如果有高优先级任务则优先执行高优先级任务
然后释放所有的已经被iterated的任务(这些任务在execute中被执行了)
和socket中的逻辑相同,首次我们要记录tail节点并传给more tasks,用来获取最新的尾节点
如果没有更多任务的话,我们就会通过destroy queue释放掉这个队列。(这里只有在我们调用stop的时候才会设置ESTOP,并销毁队列。否则的话当没有任务的时候他会退出这个函数,并不会销毁队列。
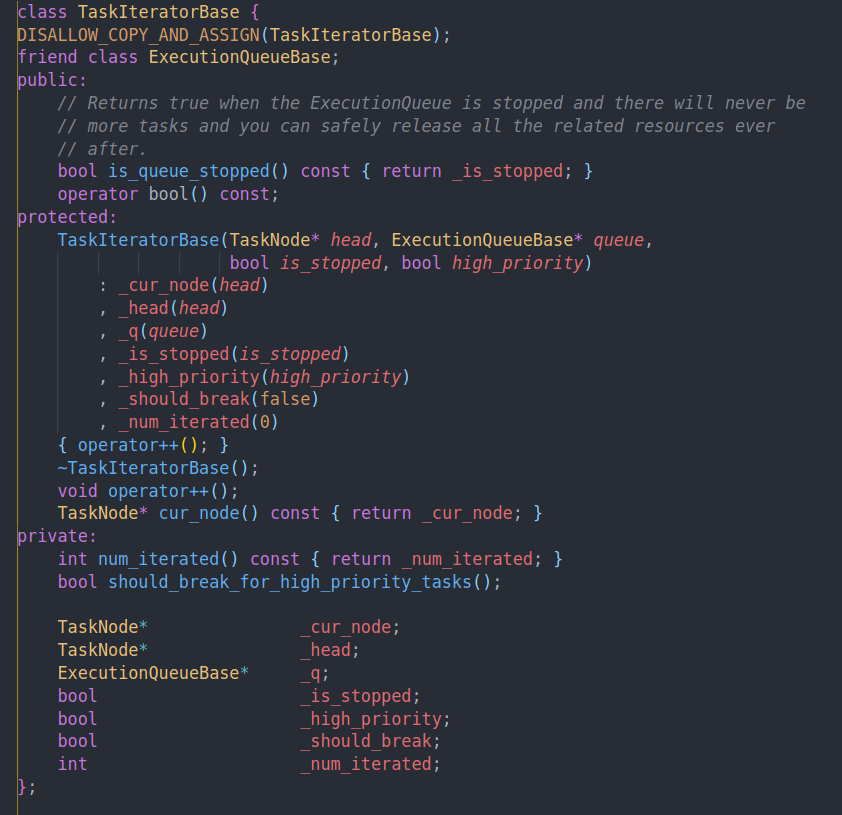
然后看一下task iterator的实现
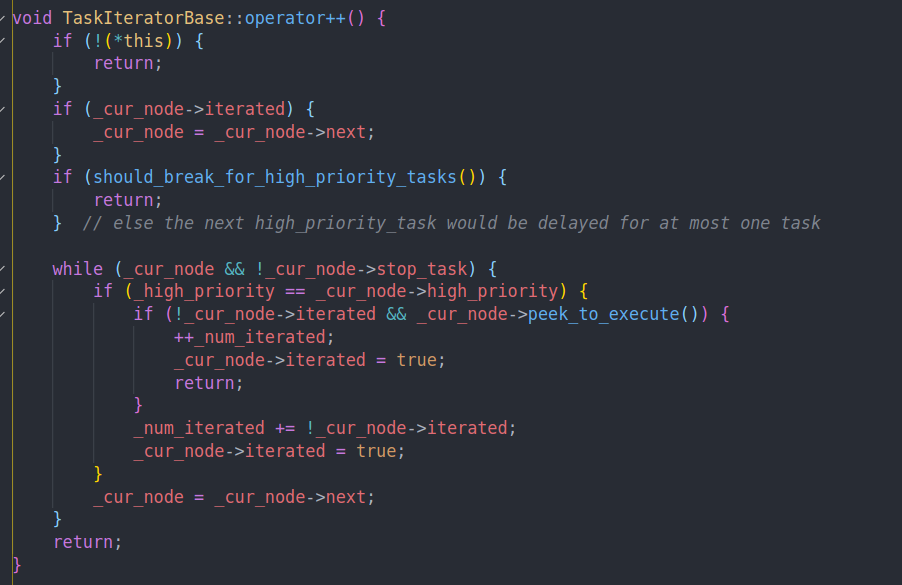
如果我们当前任务不是高优先级任务,并且队列里出现了高优先级任务的时候,我们就会终止本次执行
然后我们会遍历直到找到第一个同级优先级任务,置为已遍历。然后返回
判断是否中止则是通过operator bool实现的。
解引用则是将task node传入到TaskAllocator中,得到对应task的内存区域
大概了解框架后我们可以想这么几个问题:
1. 高优先级任务是怎么实现的?
答案是在执行execute的时候,我们会判断如果有高优先级的任务,则将execute设为high priority的状态。这样他会跳过低优先级的任务。
然后通过num iterated来获取执行任务的数量,并减少高优先任务的数量,直到高优先任务执行完之后。才会正常执行普通的任务。
2. task node中的iterated的作用?
跳过已经被遍历的任务,因为我们高优先级任务和低优先级任务在链表中是交错排列的
3. _execute中为什么head stop了以后不直接退出?
这个我的猜测就是让执行函数执行一下收尾的逻辑,因为进去之后不会调用task.execute,会判断迭代器为空直接退出。
4. task node中的status的作用?
用来设置为executed,从而跳过被cancel的任务
其实execution queue中还有一块没有说明白,就是有关资源的释放。涉及到address,deference,和on recycle这三个函数。不过主要的原理现在已经弄清楚了。之后有机会再去看这块。

文章评论