bthread
bthread很关键的一点和协程的不同就是当bthread被阻塞的时候,同一个pthread下的其他bthread不会被阻塞,而是会被其他的pthread偷走运行。
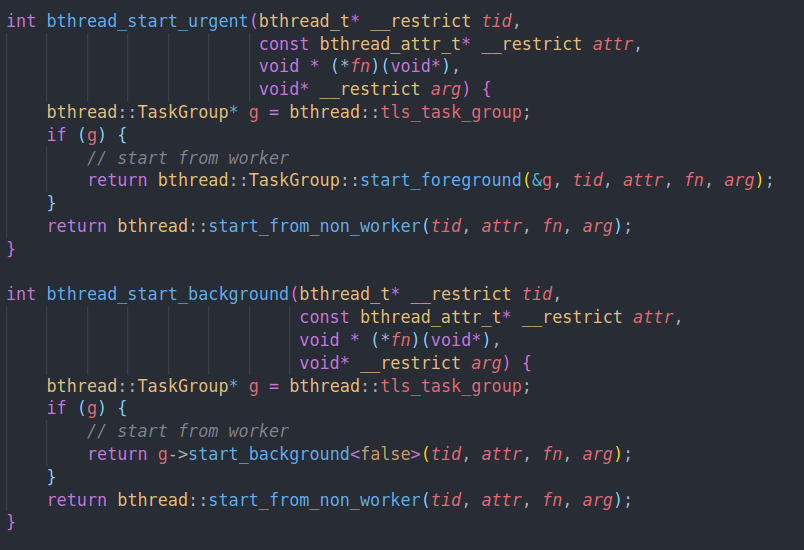
bthread的启动函数
bthread中的一个task group对应了一个worker,可以看到他是从tls中取task group的,所以可以想到是一个pthread对应一个task group
如果没有task group的话,说明当前的pthread不是bthread worker。所以我们就调用start from non worker
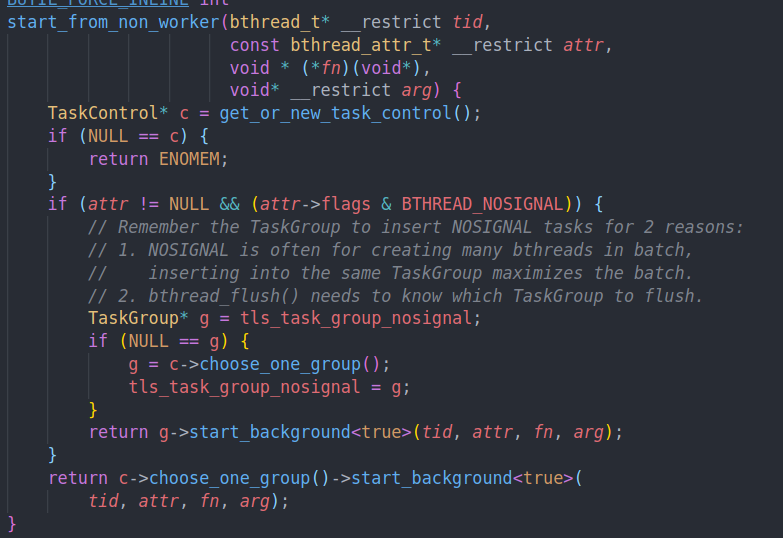
start from non worker这里首先拿到一个全局的task control。
get_or_new_task_control是一个懒汉式单例。但是由于我们可能是多线程访问task control,所以需要进行同步。brpc这里的做法就是通过原子变量来原子的申请task control(原子变量里存的就是一个指针,是不变的,所以不会受到缓存一致性协议的影响)
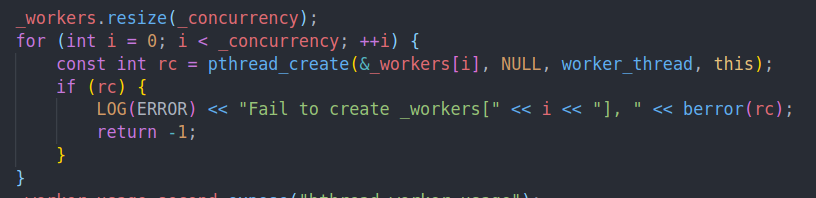
初始化task control内部,我们会创建_concurrency个pthread worker
然后我们会随机选择一个task group,并在该task group中开启后台线程。
他这里有一个额外的判断就是如果我们开启的属性为NOSIGNAL的话,就要记住该task group
然后回到开始的函数看start foreground,开启前台线程。
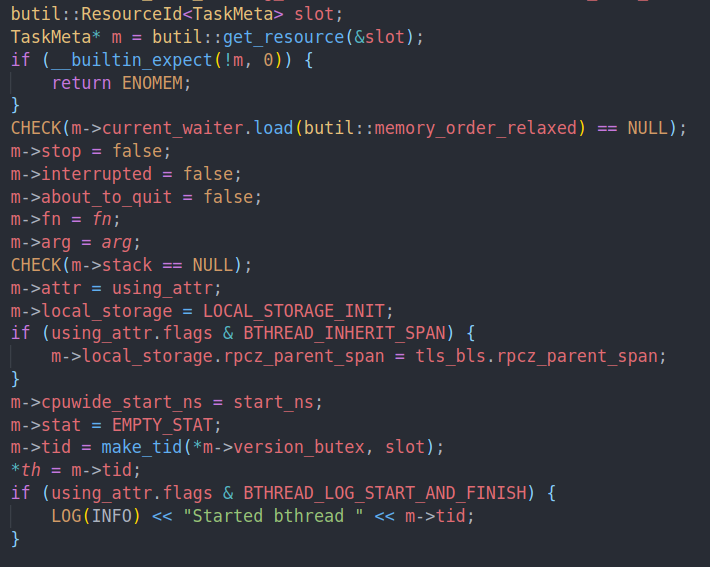
从resource pool中拿一个task meta,然后初始化task meta
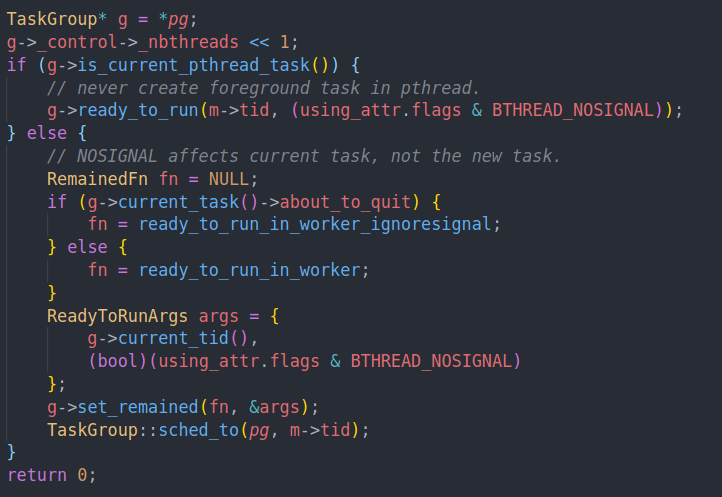
这里就是具体的调度。对于pthread来说的话,我们就直接把它放入rq(running queue)
如果是bthread的话,设置他的RemainedFN,RemainedFN的作用在这里
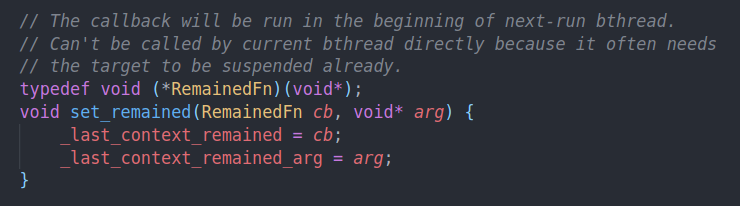
就是设置当前bthread结束时调用的回调。因为我们会抢占当前的bthread,所以需要把它重新插入到rq中。
最后通过sched_to切换bthread
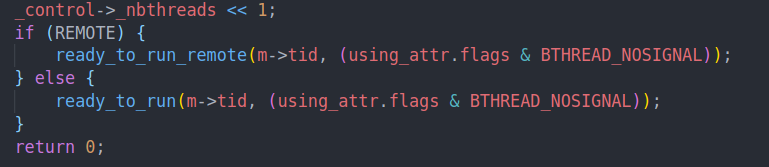
start foreground和start background的区别就是是否切换bthread
这里ready to run就是直接在rq插入任务,由于我们是一个pthread对应一个task group,所以这里不会出现竞争。但是当插入remote queue的时候,就需要考虑同步问题了。
一个task group内有两个queue,一个是本地的work stealing queue,还有一个是remote queue(目前不太清楚为什么要分开,可能是为了防止竞争,以及保护缓存局部性)
然后回去看pthread worker的worker thread在干什么

创建task group。task group会分配一个task meta作为main task
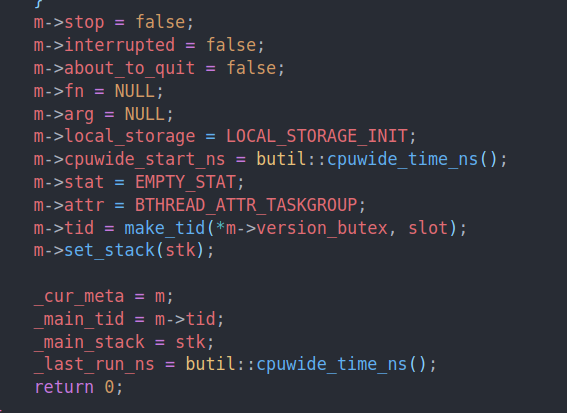
然后我们就开始执行run_main_task
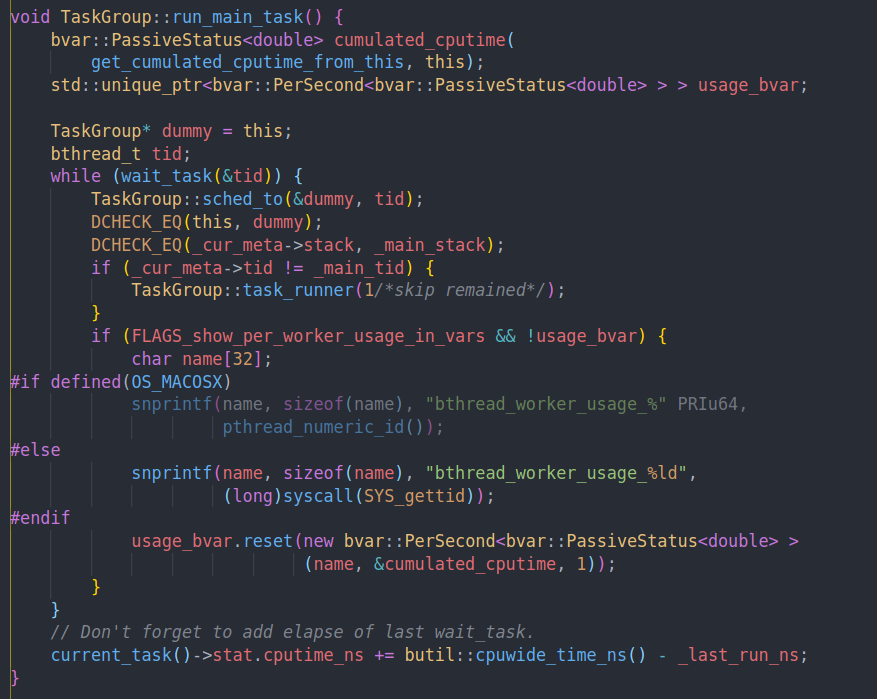
可以看到基本的逻辑就是通过wait_task获取一个task,然后通过sched_to切换到这个bthread
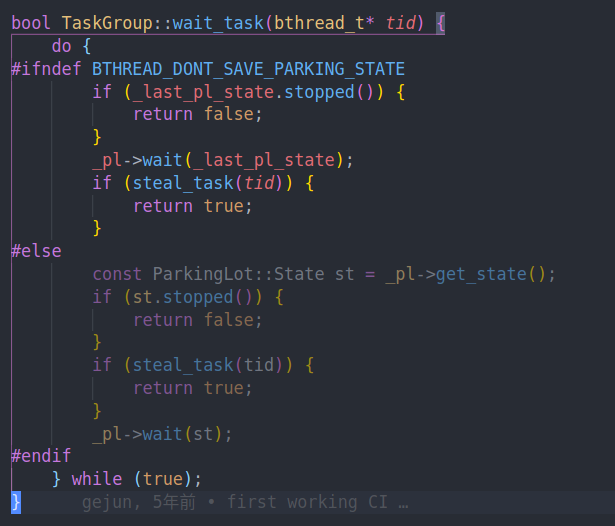
可以看到是从steal task中获取任务
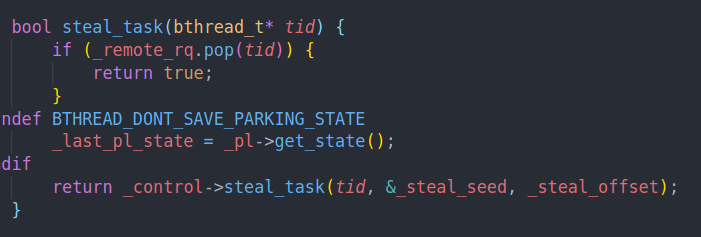
他会首先从remote rq中取一个任务
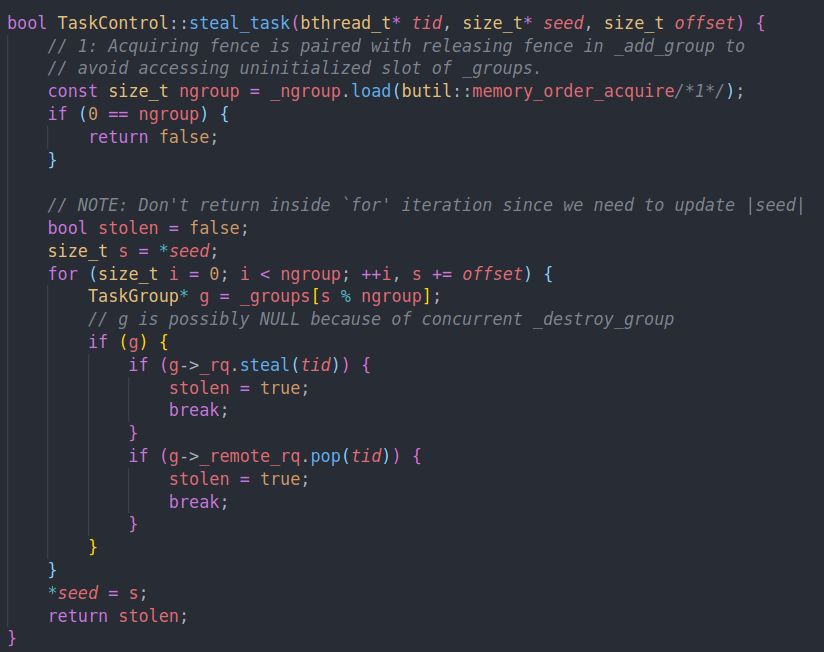
否则他就会从全局的task control中偷一个任务
优先偷_rq,其次是remote rq
(这么看是不是remote rq的优先级更高呢?毕竟我们会有限偷走rq)
然后在sched_to中调度
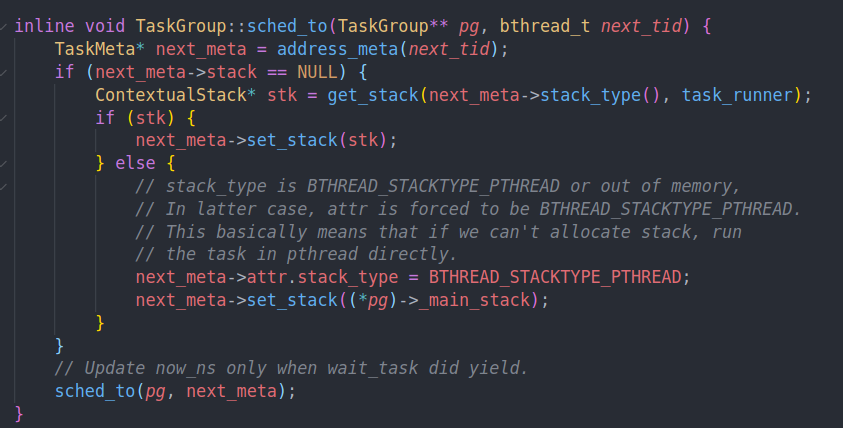
这里的逻辑是为新的task创建栈
创建的栈会跳到task_runner中
我们可以进到get_stack中看看他具体是怎么实现的
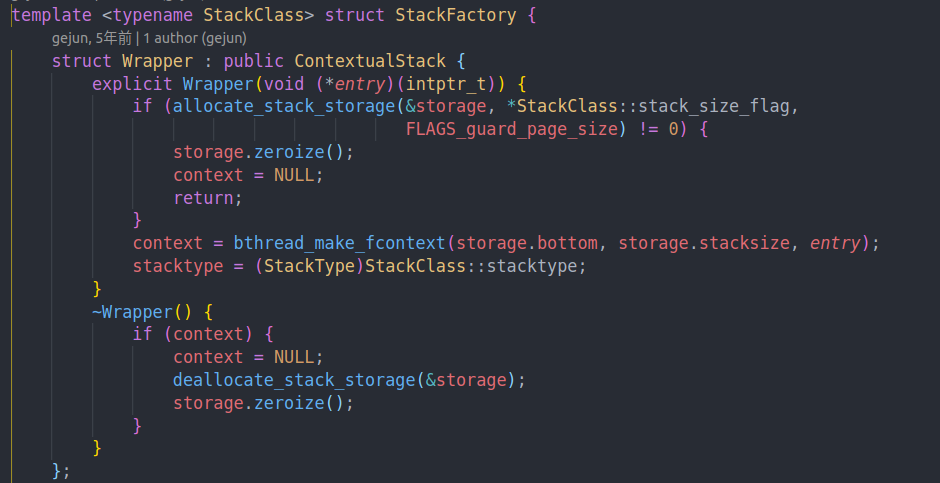
可以看到创建的函数就是这个Wrapper。他会申请栈空间,然后make context

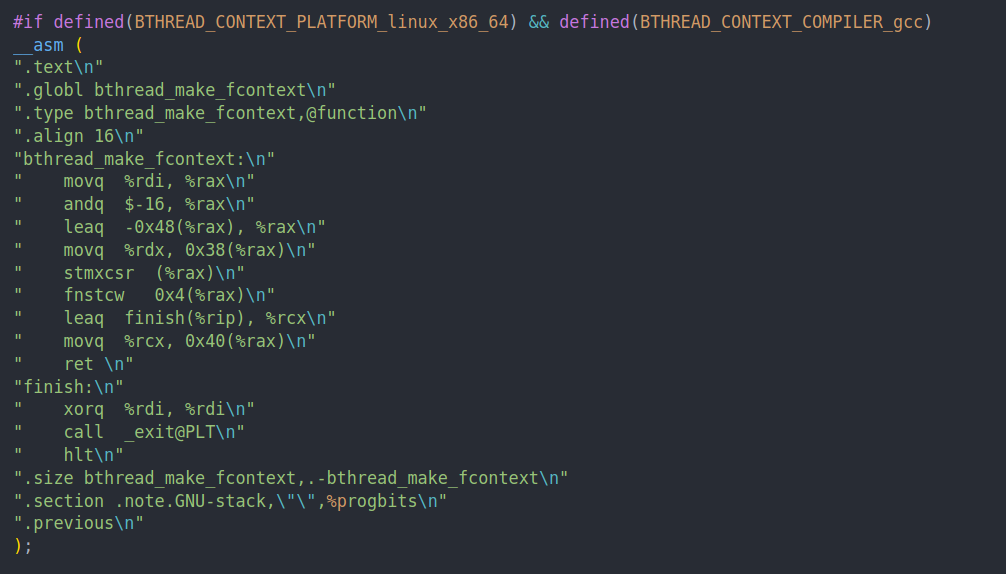
这一段就是创建context,配合参数看
context = bthread_make_fcontext(storage.bottom, storage.stacksize, entry);
这个用法和linux的ucontext非常相似。
rdi是第一个参数,我们首先传给rax,然后and -16,这个应该是为了对齐。
通过lea让rax向下移动,移动了9个寄存器的位置。然后把rdx放到0x38这个位置,rdx对应的是第三个寄存器,也就是entry,我们希望进入的入口地址。
然后他把rip + finish存到了0x40这个位置。rip表示的是pc,即instruction pointer
回去看task runner,核心如下

即调用用户代码以及用户参数
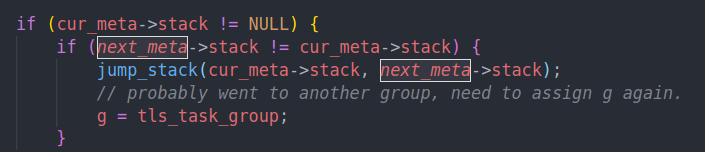
在sched_into内部,会调用jump stack

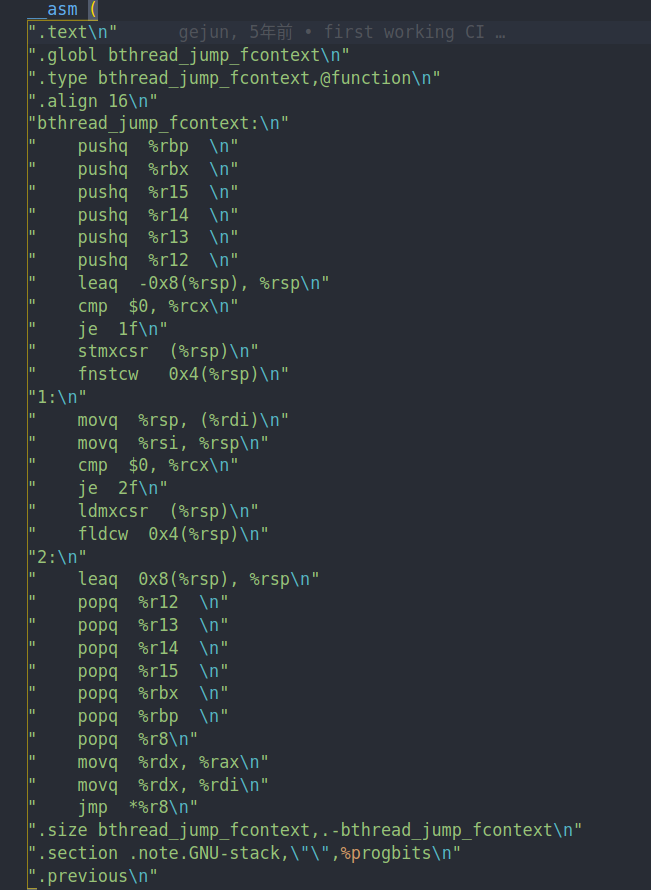
就会调用这段汇编。首先把当前的context保存起来到栈里。
他会最后把rsp,也就是当前的栈指针存入到rdi指向的位置。也就是我们传入的stack
然后把rsi的值作为新的栈指针。并从中将之前保存的寄存器都恢复出来。最后应该是跳入到我们之前保存的pc中开始执行代码。
这样我们就完成了用户态线程的切换。
这么看的话和我之前实现的TinyThread是类似的。就是每个worker有任务队列。内部任务的切换要靠主动的sched_to,也就是yield来实现上下文切换。bthread应该是独立的栈,但是貌似也可以通过main stack实现共享栈。
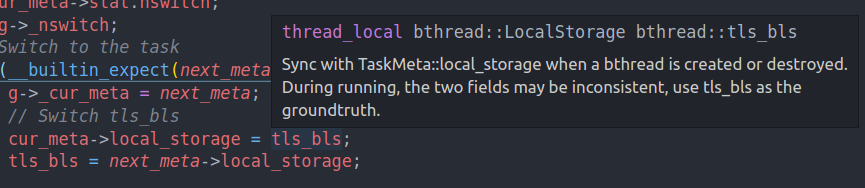
并且由于同一时间只有一个bthread运行在pthread上,所以会把bls保存到tls中。这样我们就可以通过tls_bls访问到bthread的局部变量。即像pthread的thread local一样去访问bthread local的变量,从而增强了易用性。
最后补充一下栈的切换,这里推荐大家看一下这个博客
他有一个图画的很好
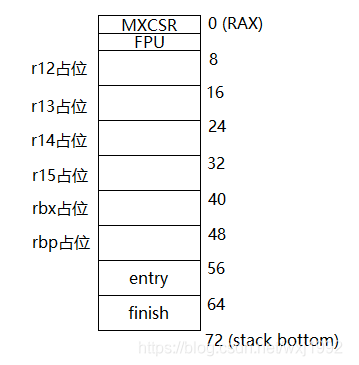
这里构造了栈以后,目前不用在意MXCSR和FPU
在x86下调用call的时候,我们就会自动把当前的pc压入到栈中。然后压入被调用者保留的寄存器。
下面这个entry就是我们伪造的返回地址。
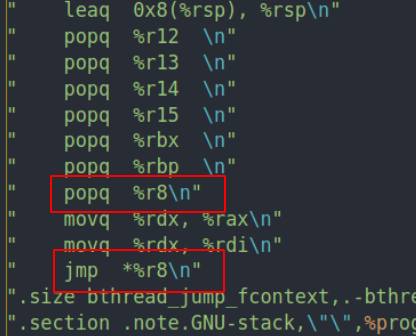
在我们切换栈的时候就会通过pop r8把entry放到rip中。然后调用jmp就可以跳转到新的pc上开始执行代码了。
而对于被中断执行的bthread,栈的结构是完全相同的。只不过这时候的entry不是由我们手动构造的,他的值是在调用jump stack的时候通过call指令压入的pc。这样我们切换回来的时候就可以通过之前压入的pc恢复执行。
(个人认为这里的jmp改成ret应该也没什么问题)
那最下面的finish的作用呢?当我们跳转到新的bthread的时候,他的栈起始就只有一个finish,就是这个bthread的返回地址。也就是说如果我们的task runner返回了,他就会调用这个finish,停掉这个线程。

实际上能够从task runner返回的只有pthread类型的bthread。也就是用main stack执行的worker。这时候他会返回到这里
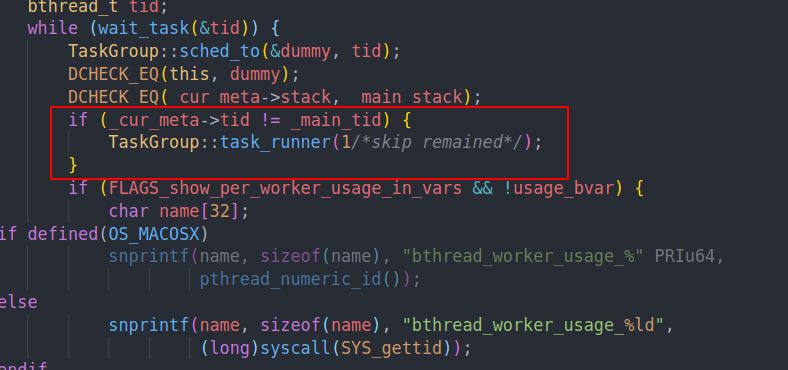
从而继续执行。
这是因为一般的bthread结束后,会通过jump stack跳转到上面的sched to中。只有和main stack相同栈的bthread才不会跳转。从而回退到task runner中。

文章评论