IO
dispatcher在event_dispatcher.h中
当新的连接出现的时候,dispatcher就负责将fd分发给bthread
epoll out在我们可以向对端写入数据的时候会触发
epoll in则是在对端有数据写入时会触发。触发一次后需要不断的读取所有数据直到EAGAIN为止。
EPOLLIN connection arrives; data is coming; The associated file is available for read operations
EPOLLOUT has data to write. The associated file is available for write operations
当收到epoll in的时候,我们就调用Socket::StartInputEvent
当收到epoll out的时候,我们就调用Socket::HandleEpollOut
int Socket::StartInputEvent(SocketId id, uint32_t events,
const bthread_attr_t& thread_attr) {
SocketUniquePtr s;
if (Address(id, &s) < 0) {
return -1;
}
if (NULL == s->_on_edge_triggered_events) {
// Callback can be NULL when receiving error epoll events
// (Added into epoll by `WaitConnected')
return 0;
}
if (s->fd() < 0) {
CHECK(!(events & EPOLLIN)) << "epoll_events=" << events;
return -1;
}
// if (events & has_epollrdhup) {
// s->_eof = 1;
// }
// Passing e[i].events causes complex visibility issues and
// requires stronger memory fences, since reading the fd returns
// error as well, we don't pass the events.
if (s->_nevent.fetch_add(1, butil::memory_order_acq_rel) == 0) {
// According to the stats, above fetch_add is very effective. In a
// server processing 1 million requests per second, this counter
// is just 1500~1700/s
g_vars->neventthread << 1;
bthread_t tid;
// transfer ownership as well, don't use s anymore!
Socket* const p = s.release();
bthread_attr_t attr = thread_attr;
attr.keytable_pool = p->_keytable_pool;
if (bthread_start_urgent(&tid, &attr, ProcessEvent, p) != 0) {
LOG(FATAL) << "Fail to start ProcessEvent";
ProcessEvent(p);
}
}
return 0;
}
当一个epoll in事件发生时,我们会通过socket id获得socket。如果没有触发事件的话直接返回就行。
由于一个socket对应的fd会不断的发生事件,我们需要保证一个socket的fd在同一时间只能被一个bthread处理。这里是在socket内部记录了_nevent,只有当从0跳到1的时候才会开一个新的bthread处理事件,其他情况下说明已经有bthread在处理了,我们直接返回就好。
这里的启动用的是bthread_start_urgent,即快速启动,他会让当前的pthread直接开始运行这个bthread,后续的部分(即dispatcher的后面的处理)则会被放到调度器中被其他的bthread偷走执行。即continuation stealing,对缓存更友好。
但是如果启动新的bthread失败的话,我们就直接在本地线程执行。
我们这里会将socket的所有权转移给新的bthread。并调用对应的回调
在Acceptor中有对应的设置。我们在这里使用的是Acceptor::OnNewConnections
void Acceptor::OnNewConnections(Socket* acception) {
int progress = Socket::PROGRESS_INIT;
do {
OnNewConnectionsUntilEAGAIN(acception);
if (acception->Failed()) {
return;
}
} while (acception->MoreReadEvents(&progress));
可以看到思路就是不断读取数据直到EAGAIN,对应应该是读取结束。然后再去查看是否有更多的读取事件
在OnNewConnectionUntilEAGAIN内部,首先通过accept建立连接
对于这个新的fd,我们会创建一个新的Socket来代表这个连接。并注册新的回调函数
SocketId socket_id;
SocketOptions options;
options.keytable_pool = am->_keytable_pool;
options.fd = in_fd;
butil::sockaddr2endpoint(&in_addr, in_len, &options.remote_side);
options.user = acception->user();
options.on_edge_triggered_events = InputMessenger::OnNewMessages;
options.initial_ssl_ctx = am->_ssl_ctx;
if (Socket::Create(options, &socket_id) != 0) {
LOG(ERROR) << "Fail to create Socket";
continue;
}
in_fd.release(); // transfer ownership to socket_id
新的回调函数是InputMessenger::OnNewMessages
从这里可以大概看出来,我们对于一个server fd来说,会有一个bthread在这里不断的accept,创建新的socket。
然后后续的读入则会在InputMessenger中处理。则是由其他的bthread负责。
来到OnNewMessage这里,是消息处理的主要地方。他负责从fd上切割并处理消息。
每个协议有自己对应的parse和process。Parse是把消息从二进制流上切割下来。Process则是进一步解析消息。
当一次切出来一个消息的时候,就会原地处理。当一次切出若干个消息的时候,他就会开启n - 1个bthread去处理,最后一个消息贝原地处理。
QueueMessage的作用就是开启一个新的bthread去处理消息
他这里的实现就是通过一个last_msg来记录上一个消息,然后每次循环处理的是上一个消息。
ParseResult pr = messenger->CutInputMessage(m, &index, read_eof);
从这里尝试切割消息,并得到对应协议的index
DestroyingPtr<InputMessageBase> msg(pr.message());
QueueMessage(last_msg.release(), &num_bthread_created, m->_keytable_pool);
创建本次的消息,并把上一个message放到bthread中处理
msg->_process = handlers[index].process;
msg->_arg = handlers[index].arg;
根据协议设置对应的process方法
last_msg.reset(msg.release());
循环的最后会把当前的msg放到下个循环处理。
那么对于最后一个msg,他会被保存在last_msg中
std::unique_ptr<InputMessageBase, RunLastMessage> last_msg;
last_msg是一个具有自定义析构函数的unique_ptr。所以他会调用RunLastMessage
即原地调用ProcessInputMessage来处理消息。
在代码的policy中有各种协议的处理逻辑。
brpc中注册handler的时候,会把arg设置成server的指针
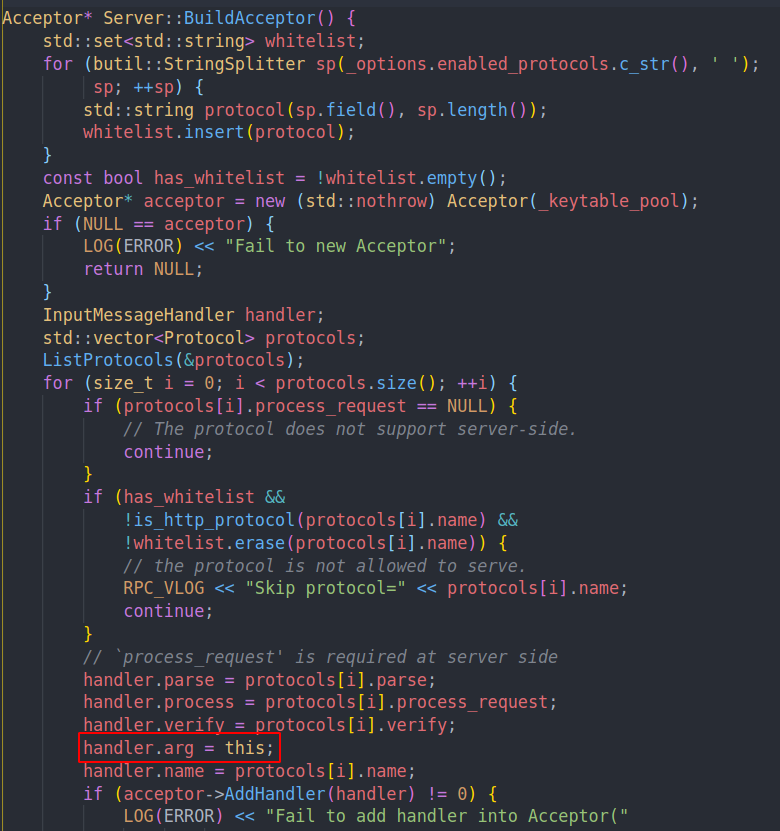
以及对应的parse,process函数。
所以在具体的process回调内部会使用这个server的指针
const Server::MethodProperty* const sp =
FindMethodPropertyByURI(path, server, &req_header._unresolved_path);
google::protobuf::Service* svc = sp->service;
const google::protobuf::MethodDescriptor* method = sp->method;
google::protobuf::Message* req = svc->GetRequestPrototype(method).New();
google::protobuf::Message* res = svc->GetResponsePrototype(method).New();
这个是HTTP的例子,根据URI找到我们希望调用的服务以及方法,然后根据方法获取对应的request以及response的消息。
最后的发送消息是通过done->Run()完成的。在我们调用方法结束后,就会通过RAII来调用这个callback,从而实现回复客户端。
google::protobuf::Closure* done = new HttpResponseSenderAsDone(&resp_sender);
if (BeginRunningUserCode()) {
svc->CallMethod(method, cntl, req, res, done);
return EndRunningUserCodeInPlace();
} else {
return EndRunningCallMethodInPool(svc, method, cntl, req, res, done);
}
具体则是在这里,done就是一个用来发送Response的RAII对象。我们根据不同的模式去调用用户代码。上面两种模式,第一种就是原地执行user code,所以他会直接调用service->CallMethod调用我们需要的方法。第二种则是开启后台线程,在后台调用。不过总归还是需要通过service->CallMethod来调用用户代码的。
总的来说,可以想一想brpc的做法。主要就是让分发任务给bthread。
EventDispatcher会用continuation stealing的方法来保证缓存友好性。
可以看到同一个socket上的读取是一个bthread负责的,他会不断的分割消息,然后创建新的bthread去处理消息。新的bthread则会调用用户代码。
对于listen—fd来说,则是不断的创建新的socket,并注册消息处理的函数。
不会出现IO阻塞的问题,因为每个fd都有自己负责的线程,fd与fd之间不相关。不会出现IO线程慢导致影响其他线程。

文章评论