整体架构
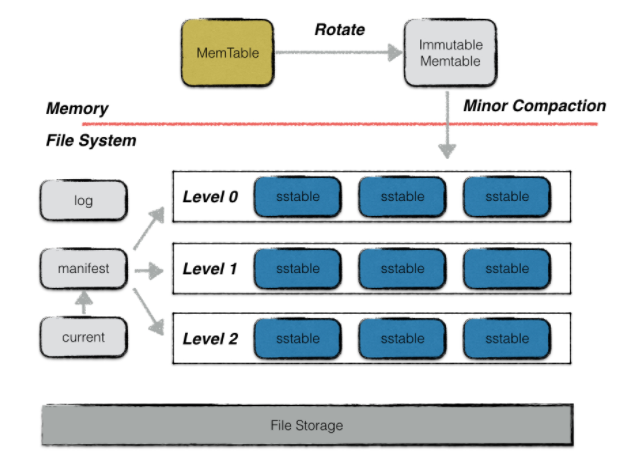
貌似和bigtable完全相同
level由这几个组建组成
memtable
是一个主存中的跳表。按序存储。当容量到达阈值的时候就转换成一个不可修改的memtable
immutable memtable
不可修改的memtable。当他被创建的时候,leveldb的后台压缩进程会利用其中的内容创建一个sstable。持久化到磁盘中
log
WAL,每次写操作要先顺序写日志。从而保证我们可以从异常状态下恢复。
写操作的原子性也由日志来保证,当日志成功写入的时候,写操作成功。当写日志异常的时候,后续的恢复会丢掉这个日志。写操作被视为失败
sstable
leveldb的数据主要通过sstable来存储。leveldb后台会定期进行compaction,随着compaction的进行,sstable文件在逻辑上被分为若干层。
内存数据dump出来的文件为level 0层。compaction出来的文件为level i层
sstable文件不可修改
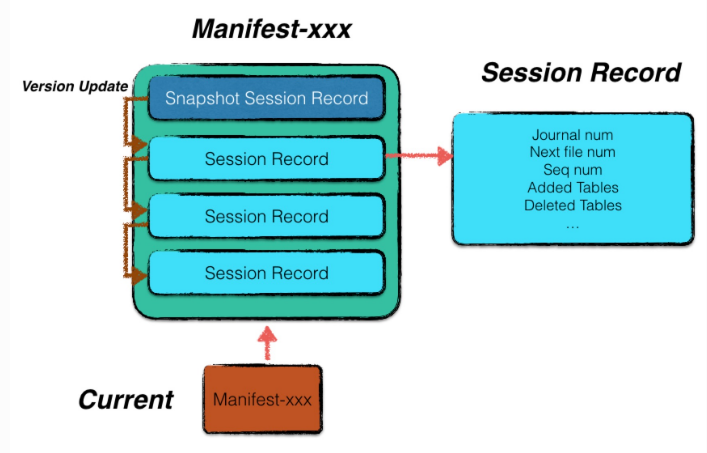
manifest
leveldb记录了每一层中所有文件的元数据,包括文件大小,最大key值,最小key值。通过维护这些元数据我们可以加快查找,以及控制compaction进行。
这些元信息被存储在level的版本信息中
leveldb每次compaction完成都会创建一个新的version。而manifest文件记录了每次version的变化。
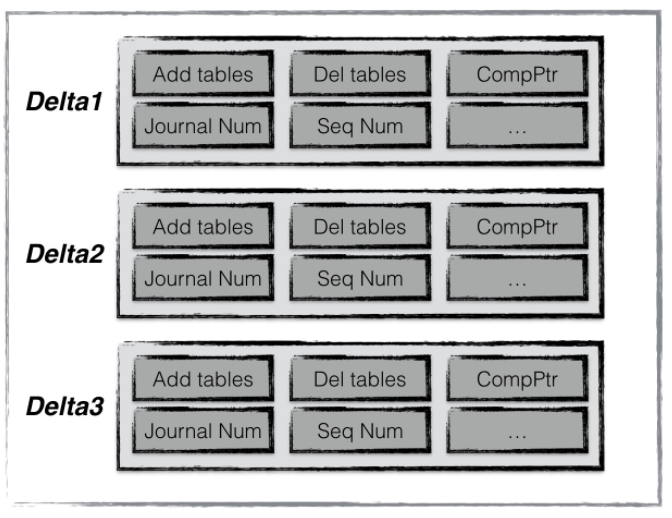
每个manifest记录了每次版本变更(1)添加了那些sst文件,(2)删除了那些sst文件,(3)当前compaction下标,(4)日志文件编号,(5)操作seqNumber等信息。
我们通过不断apply这些记录最后得到level上一次运行结束的版本信息
current
current记录了当前manifest文件名
读写操作
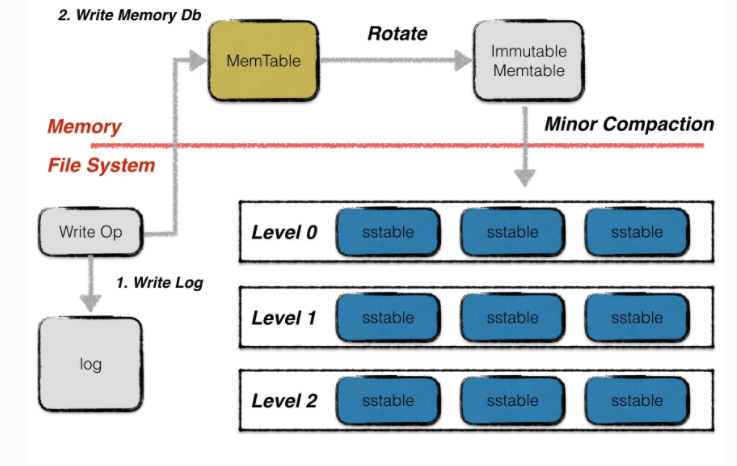
leveldb的写入有两部分,先写日志。然后在把写操作应用到内存中
leveldb提供两种写操作,put和delete
此外leveldb提供了一个批处理工具Batch。我们可以通过Batch来完成批量的原子操作
Batch

无论是正常操作还是批量操作底层都会创建一个batch作为数据库操作的最小单元
batch中每个数据都按照上面的格式编码。type表示是更新还是删除
数据从batch写入到内存中的时候,需要一个key值的转换,这种格式成为internalKey

尾部追加了sequence number,每次操作都会递增这个数。在leveldb中的操作采用的是append的方式,所以对于一个key会有多个版本的记录,使用最大的sequence number就是最新的数据
每一个sequence number就代表了数据库的一个版本
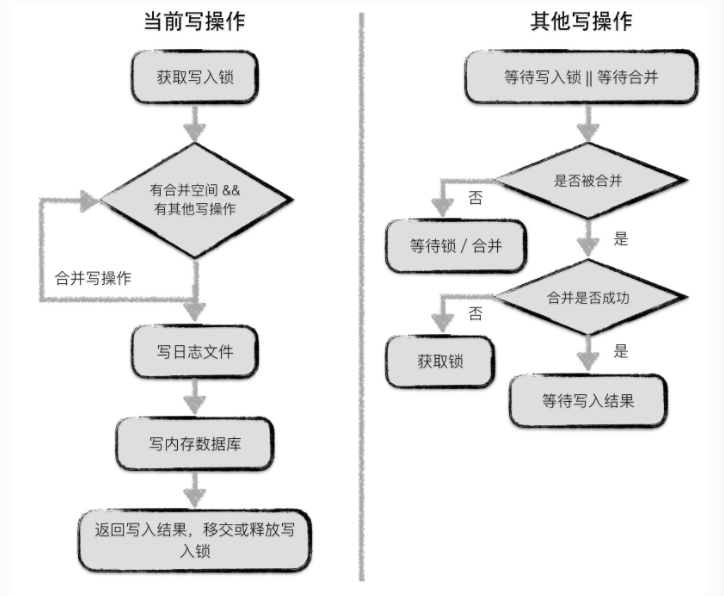
合并写
leveldb中对于并发写入的时候,同一时刻只允许一个写入操作将内容写入到主存以及日志中。为了增加日志的写入性能,leveldb将一些小写入合并成一个大写入。
对于第一个获取到写锁的写操作
* 第一个写入操作获取到写入锁
* 当前写操作的数据量未超过合并上线,并且有其他写操作等待的情况下,就将其他写操作的内容合并到自身
* 若本次写操作的数据量超过上线,或者没有其他写操作等待了,就将所有内容统一写入到日志文件,并写入到内存中
* 通知每一个被合并的写操作的最终写入结果,释放或移交写锁
其他写操作
* 等待写锁或者被合并
* 若被合并判断是否成功,成功则等待最终写入结果,否则则接过写锁并写入
* 未被合并则等待写锁或者等待被合并
读操作
用户可以通过Get直接读数据,或者创建一个snapshot然后基于该snapshot用Get读数据
本质上第一种方法是基于当前状态的快照的读,所以两种都是基于快照进行读
leveldb中,通过一个整数来代表数据库的状态。
上面提到的每一个sequence号都可以作为leveldb的一个状态快照
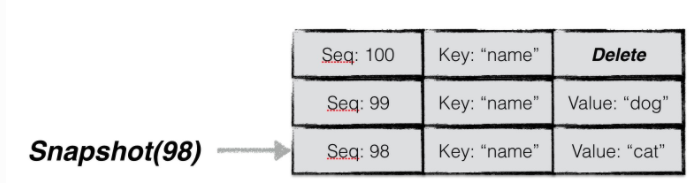
通过快照来保证数据库进行并发的读写。
获取到一个快照后,leveldb会为本次查询的key构建一个internalKey,其中seq字段使用的就是快照的seq,从而过滤掉所有seq大于快照号的数据项
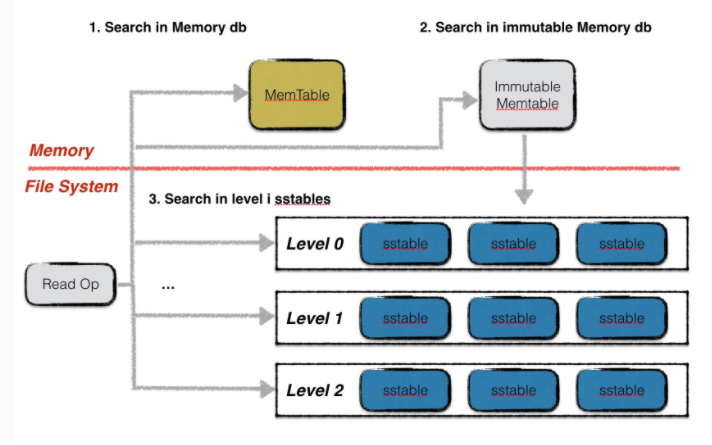
leveldb的读取分为三步
- 在memory db中查找指定的key,如果成功则结束查找
- 在冻结的memory db中查找指定的key,如果成功则结束查找
- 按从低到高的顺序在level i层中查找key,若找到则结束。否则返回NotFound
注意在leveldb中第0层,可能出现key重合的情况,所以要优先找文件号大的sstable。而在非0层中,所有文件之间的key不重合,所以可以借助sstable的元数据来快速定位。所以每一层只要读一次。
日志
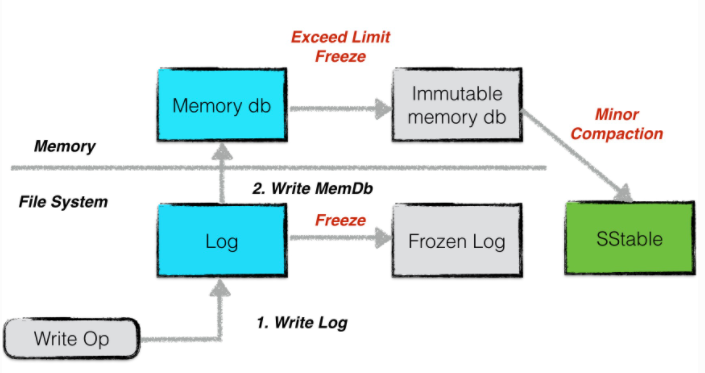
leveldb中,有两个memory db,对应了两份日志文件。当一个memory db被冻结的时候,与之对应的log也会变成frozen log
当后台的minor compaction进程将其转换成一个sstable文件持久化以后,对应的frozen log就会被删除
日志结构
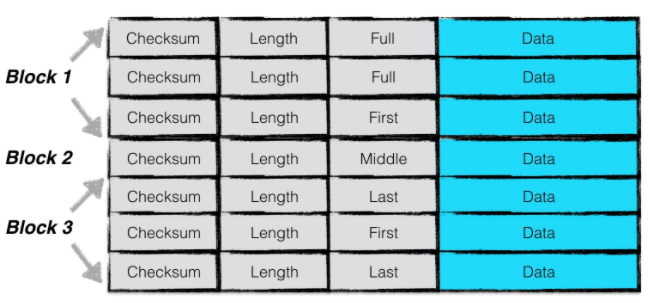
日志按照block划分,每个block大小为32kb
一个日志记录包含一个或多个chunk,每个chunk包含一个7字节大小的header,前4字节是checksum,2字节是数据长度,最后一个字节是chunk类型
chunk有四种类型,full,first,middle,last。一条日志记录只包含一个chunk,则chunk为full。如果包含多个chunk,那么第一个是first,最后一个是last,中间则是middle。
因为一个block大小为32kb,所以当日志过大的时候,我们就会拆分数据,并把chunk划分成first,middle,last的格式
日志内容
日志为写入的batch编码后的信息

header中包含了sequence number,以及本次日志中包含的put/del操作的个数
后面则是所有batch编码后的内容
日志写

写入的时候不断判断buffer的大小,如果超过32kb就作为一个完整的chunk写入文件。写完数据注意要计算对应的header
日志读
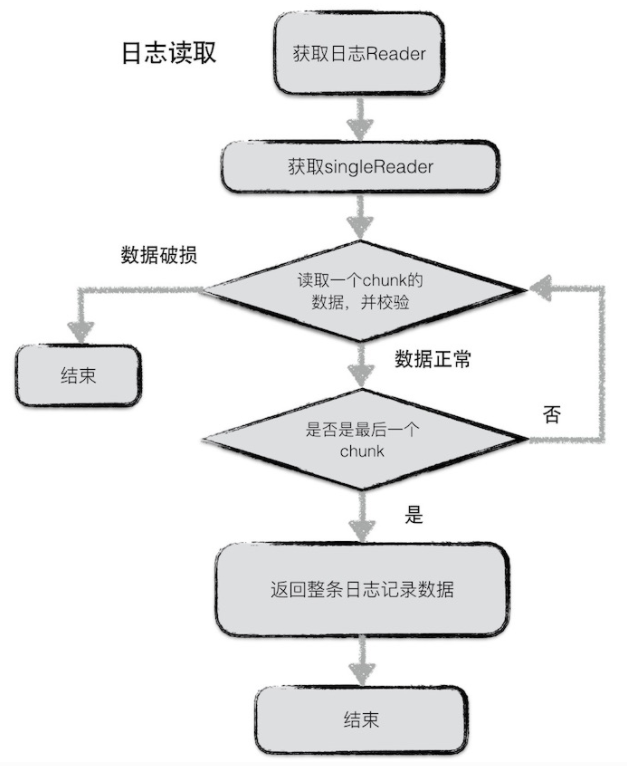
一次读一个block,每次读一个chunk,并校验数据,直到读到最后一个chunk,返回整个日志记录
内存数据库
memory db用来维护有序的key-value对,底层是用跳表实现
跳表
跳表利用了概率均衡的技术,从而加快并且简化操作。

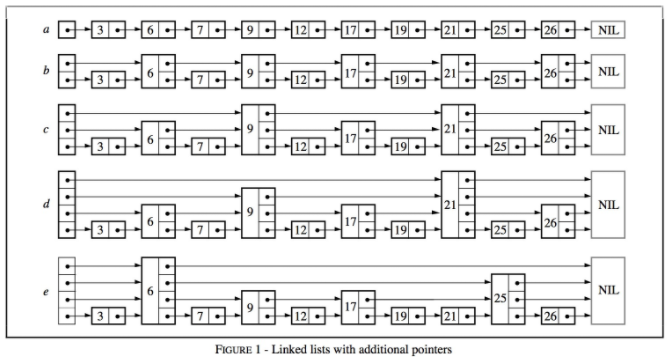
从链表起一步一步引出跳表的结构
在a中,所有元素按序排列,存储在一个链表中
在b中,每隔两个节点,新增一个额外的指针,指向距离为2的下一个节点
在c中,在b的基础上,每隔四个节点新增一个指针
不断类推我们就可以得到查询效率为logn的结构,但是这样的结构使得每次插入和删除都会异常的复杂
一个拥有k个指针的结点称为一个k层节点,按照上面的逻辑,50%的节点为1层节点,25%的节点为2层节点....。如果我们保证每层分布的节点如上面的概率所述,那么我们仍然可以达到相同的查询效率。e图就是一个示例。
结构
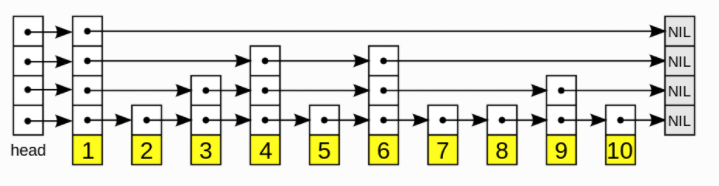
跳表是按照层来构造的。底层是一个普通的有序链表。每个更高层都充当下面链表的快速通道,这里在层i中的元素按某个固定的概率p出现在层i+1中。平均起来,每个元素都在1/(1-p)的概率在这一层中出现,而最高层的元素在O(log1/p n)个节点中出现
查找
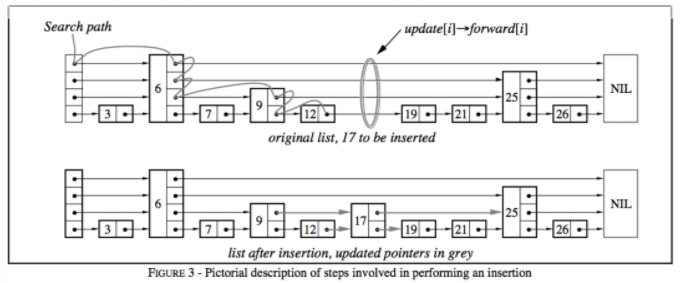
图中,我们要查找一个值为17的链表节点,过程为:
* 首先根据条表的高度选择最高层的头节点
* 如果该节点的值小于查找节点的值,就用该层的下一个节点继续比较
* 如果值相同则直接返回
* 如果该节点的值大于要查找的值,且层高不为0,降低层高并且从前一个节点开始重新查找。如果层高为0则返回当前节点
这里其实原文的说法怪怪的,因为他的视角来说所谓的当前节点就是已经跳过去的节点
插入
插入是借助于查找实现的
在查找的过程中,不断记录每一层的前任节点
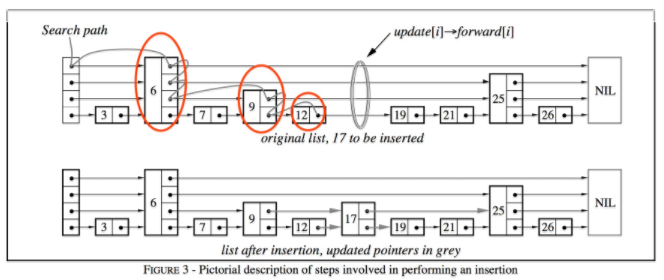
然后为新插入的节点随机选择层高。然后在合适的位置插入新的节点。并且根据之前记录的前任节点的信息,以链表插入的方式插入到每一层的链接中
删除
删除则较为简单,依赖查找过程找到该节点在跳表中的位置后,直接链表删除就可以
迭代
向后遍历
- 若迭代器刚被创建,则根据用户指定的查找范围[Start, limit)在链表中找到第一个符合条件的跳表节点
- 若迭代器处于中部,则取出上一次访问的跳表节点的后继节点,作为本次访问的跳表节点
- 利用跳表节点信息获得数据
向前遍历
- 若迭代器刚被创建,则根据用户指定的查找范围[Start, limit)在跳表中找到最后一个符合条件的跳表节点
- 若迭代器处于中部,则利用上一次访问的节点的key值,查找比该key值更小的跳表节点
- 利用跳表节点信息,获取数据
数据组织
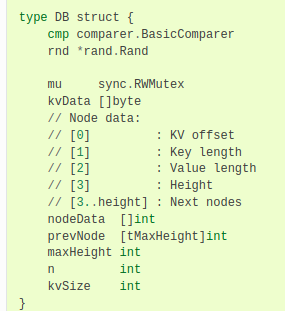
以go为例
其中kvData存储每一条数据项的kv数据,nodeData用来存储每个跳表节点的链接信息
nodeData中,每个跳表节点占用一段连续的空间,每一个字节分别用来存储特定的信息
- 第一个字节用来存储本节点kv数据在kvData中对应的偏移量
- 第二个字节用来存储本结点key值长度
- 第三个字节存储本节点value值长度
- 第四个字节用来存储本节点层高
- 第五个字节开始,用来存储每一层对应的下一个节点的索引值
(有点奇怪的是如果这样存储节点,我们怎么回收内存呢?)
答案是不回收,我们只添加不删除。删除操作其实是添加一个空的节点
SSTable
当memtable中的数据超过了预设的阈值的时候,我们会将当前的memtable冻结成一个不可更改的内存数据库,然后将memtable持久化到磁盘中
设计minor compaction的目的是为了降低内存的使用率,同时避免文件日志过大,系统恢复时间过长。
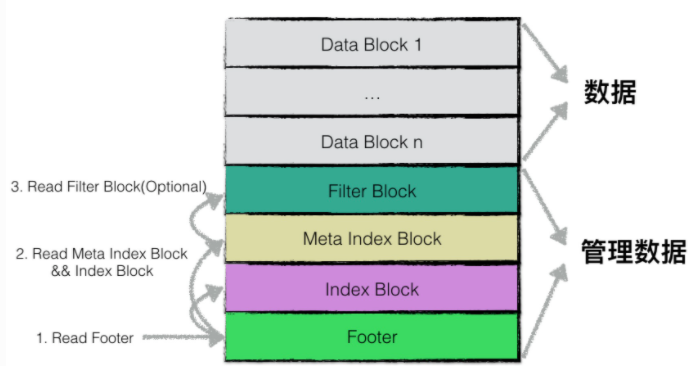
物理结构

一个sstable文件按照固定大小进行块划分,默认每个块的大小为4KB。每个block中除了数据以外还有两个额外的字段。分别是压缩类型和CRC校验码
逻辑结构
逻辑上,根据功能不同,leveldb在逻辑上将sstable分为
1. data block, 用于存储kv对
2. filter block,用来存储过滤器相关的结构
3. meta index block,用来存储filter block的索引信息
4. index block,用来存储每个data block的索引信息
5. footer,用来存储meta index block和index block的索引信息
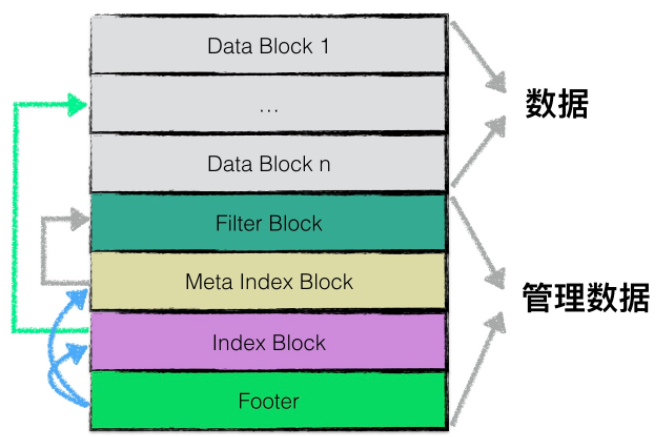
data block结构
data block中存储的数据是leveldb中的kv对。一个data block中的数据部分(不包括CRC,压缩类型)按逻辑以下图划分
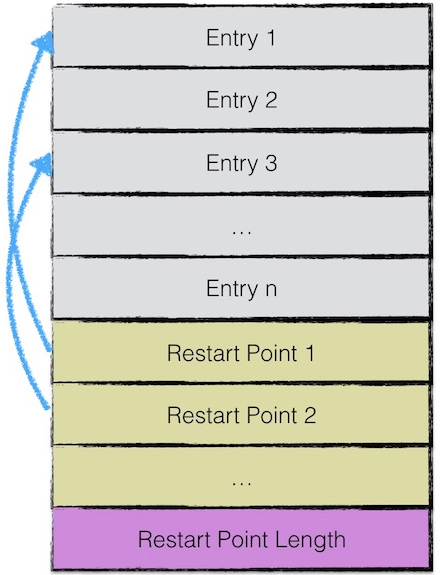
由于sstable中所有的kv对是按序存储的,所以为了节省空间leveldb只会存储当前key与上一个key非共享的部分
每间隔若干个keyvalue对将该条记录重新存储为一个完整的key。成为Restart point
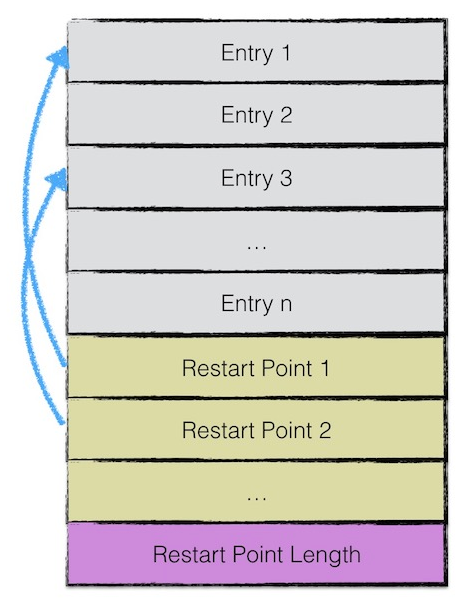
在读取的时候,可以先利用restart point的数据进行比较,从而快速定位目标数据所在的区域。然后再依次对区间内所有数据项比较。
每个数据项的格式如图:

- 与前一条key共享部分的长度
- 与前一条key不共享部分的长度
- value长度
- 与前一条key不共享的内容
- value内容
filter block结构
为了加快查询效率,在直接查询data block中内容之前,首先根据filter block中的过滤数据判断指定的datablock中是否有需要查询的数据。
fliter block存储的是一般是布隆过滤器的数据
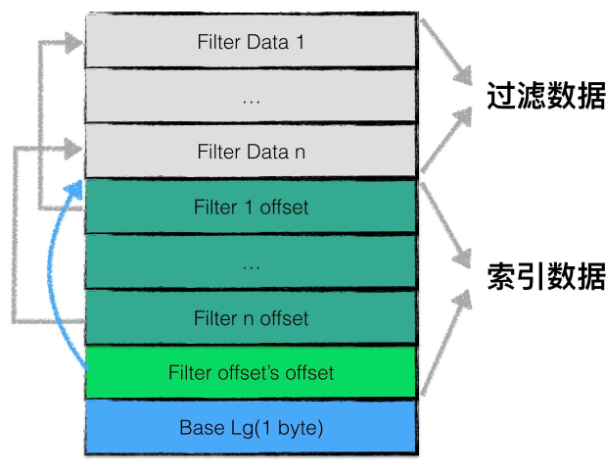
filter block存储主要为两部分,过滤数据和索引数据
在读取filter block中的内容时,首先读出filter offset's offset,然后读取filter i offset,根据这个offset再读出filter data
BaseLg的默认值为11,表示每2KB的数据创建一个新的过滤器来存放过滤数据
一个sstable只有一个filter block,存储了所有block的filter数据。具体的,filter_data_k包含了所有起始位置处于base * k到base * (k + 1)内的block的filter数据
meta index block结构
meta index block只存储一条记录
key为filter与过滤器名字组成的常量字符串
value为filter block在sstable中的索引信息,索引信息包含(1)在sstable中的偏移量,(2)数据长度
(有点奇怪的设计,目的是让footer定长么?)
index block结构
index block存储若干条记录,每一条记录代表一个data block的索引信息
一条索引包含:
1. data block i最大的key值
2. 该data block起始地址在sstable中的偏移量
3. 该data block的大小
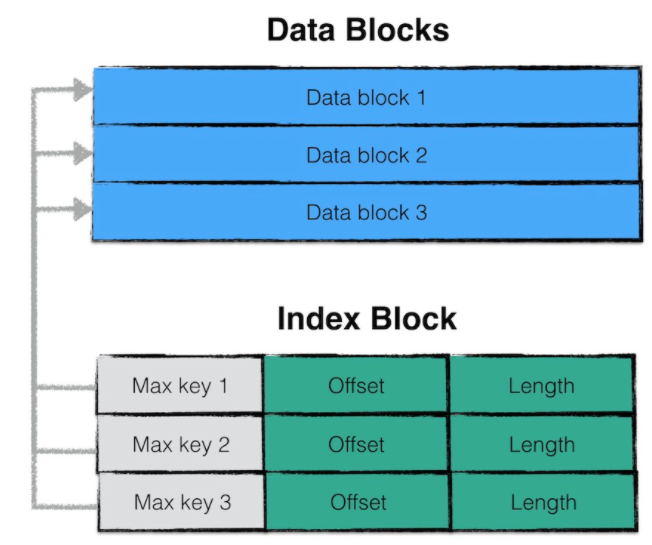
这样看上去data block不是定长的
footer结构
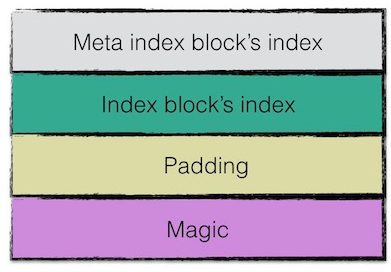
果然footer大小是固定的。48字节。用来存储meta index block以及index block的索引信息。尾部还会存储一个magic word
写操作
sstable的写操作发生在
* memory db将内容持久化到磁盘中时
* leveldb后台进行compaction时
一次sstable的写入为不断调用迭代器获取需要写入的数据,并不断调用tableWriter的Append函数,最后为sstable附上文件元数据的过程。
迭代器可以是一个memory db的迭代器,也可以是一个sstable文件的迭代器。
sstable内部会存储他的元数据吗?(存储文件大小,最大最小key值等),貌似不会,这些值是通过读取已有的元数据块导出来的
tableWriter的结构
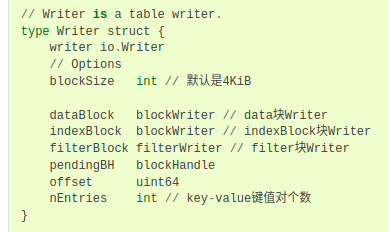
pendingBH记录了上一个datablock的索引信息,当下一个datablock开始写入的时候,将该索引信息写入indexblock中
一次Append的逻辑:
1. 若本次写入为新datablock的第一次写入,则将上一个datablock的索引写入
2. 将keyvalue数据写入datablock
3. 将filter信息写入filterblock
4. 若datablock中的数据超过上限,则将内容刷新到磁盘文件中
在将data block写入磁盘时,需要以下工作:
1. 封装datablock,记录restart point的个数
2. 若datablock的数据需要进行压缩,则压缩
3. 计算checksum(这里说的是checksum还是CRC?)
4. 封装datablock的索引信息
5. 将datablock的buffer中的数据写入磁盘文件
6. 将过滤信息生成过滤数据,写到filterblock的buffer中
最后关闭文件的时候:
1. 如果buffer中有未写入的数据,封装成一个datablock写入
2. 将filterblock的内容写入磁盘
3. 将filterblock的索引信息写入到metaindexblock中
4. 写入indexblock
5. 写入footer
读操作
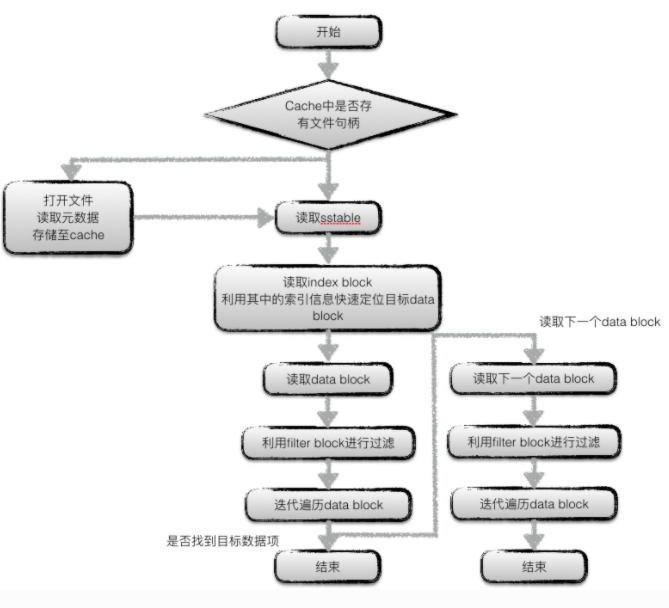
有个疑问是为什么会存在两个可能的datablock,不是因为可能有相同的值(因为sequence number的原因不会出现相同的值),而是索引的原因,看下面
leveldb中,使用cache缓存两类数据:
* sstable文件句柄以及元数据
* datablock中的数据
读取元数据的过程
要注意的是index block中的索引同样进行了key的截取。但是截取的粒度是2,所以连续的两个索引信息是作为一个最小的比较单元。从而导致最终的区间为两个datablock(难道不能重放一下,这不比新读一个datablock快么?)
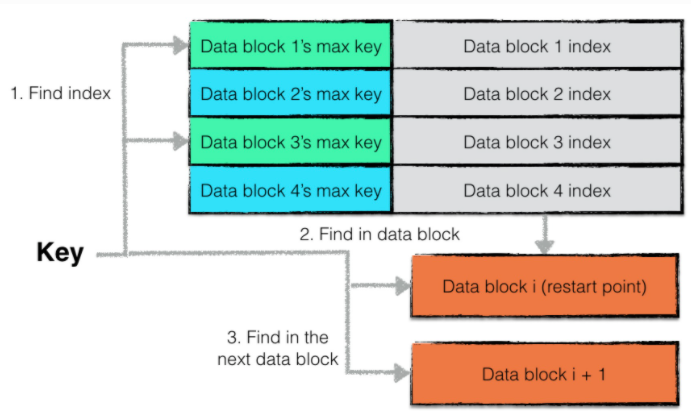
在查找datablock的时候,虽然是有序的,但是没有使用二分,而是使用了更大的查找单元(即restart point)来进行顺序遍历
缓存系统
leveldb使用了一种基于LRU的缓存,用于缓存:
* 已经打开的sstable文件对象和元数据
* sstable中的datablock的内容
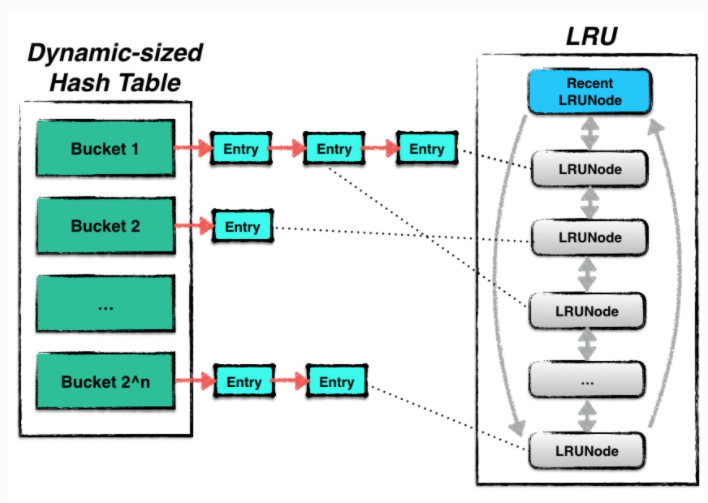
leveldb的hashtable可以实现resize过程中不阻塞其他并发的读写请求
哈希表中的每一个bucket的容量是有限的,当超过阈值的时候就会进行扩张
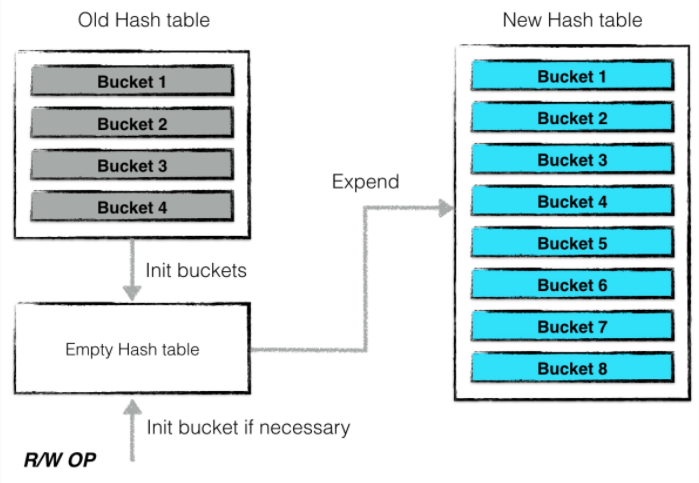
一次扩张的过程为:
1. 扩大一倍哈希桶的个数
2. 创建一个空的哈希表,然后将旧的哈希表冻结
3. 后台利用旧哈希表中的信息对新的哈希表进行构建
当有新的读写请求的时候,如果发现对应的哈希桶未构建完成,则主动进行构建,并将构建后的哈希桶填入新的哈希表中
(看起来这个冻结的思路很棒,sstable也是这样生成的)
收缩的时候也是类似的
LRU中的双向链表存储了哈希表中的指针,可以在我们从LRU中驱逐数据的时候安全的删除数据。由于哈希表中的数据可能正在被其他线程使用,所以需要通过引用计数来防止数据被不安全的删除
leveldb有两种缓存:
* cache: 缓存sstable文件句柄以及元数据
* bcache: 缓存sstable中datablock的数据
布隆过滤器

这里他的手册里我感觉写的怪怪的,我直接看源码然后写一下要注意的点
bloom filter在utils/bloom.cc中
bits_per_key就是上面的m/n,即每个key可以分配多少位。代码中通过计算ln2 * bits_per_key来得到最佳的哈希函数的个数
然后CreateFilter中,首先计算我们要用到多少byte来存储bloom filter。bloom filter在leveldb中是一个字符串,最后一个数字是hash函数的数量
keys中存储了需要添加进去的key。而对于k个哈希函数来说,我们并不是真的有k个,而是一个k次的循环,每次更改得到的哈希的值。我有点奇怪,这样的话如果BloomHash相同那么两个key不就相同了么。
对于检查来说,重新应用一次hash的过程,然后判断对应的位是否存在即可。
对于double hash的问题,因为leveldb使用的bloom hash不会取余,而是直接得到一个uint的整数,这样两个字符串能得到相同hash值的概率就很小。用这个值再去放到bloom filter中冲突就会少很多
Compaction
一些基础概念前面已经说过了
因为major compaction是一个多路归并的过程,会导致大量的磁盘读写。所以为了防止写入速度超过major compaction的速度。leveldb规定:
* 当0层文件数量超过SlowdownTrigger时,写入速度减慢
* 当0层文件数量超过PauseTrigger时,写入暂停,直至major compaction完成
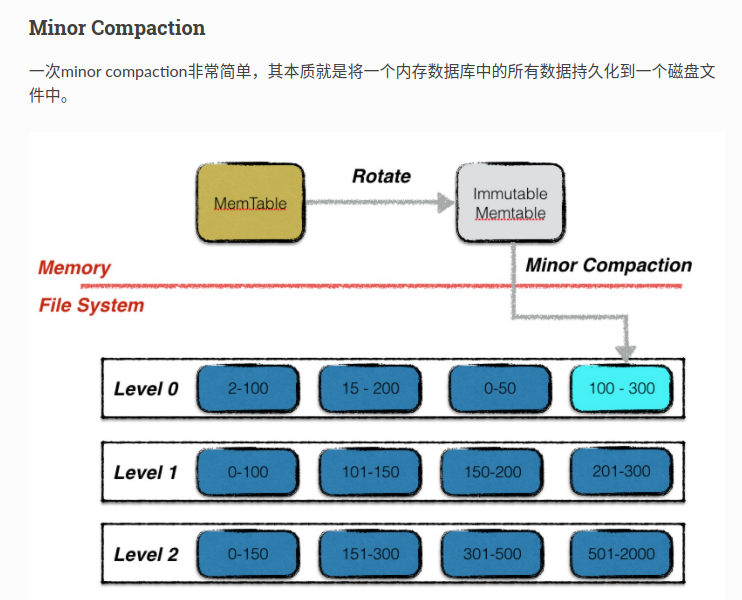
文章中说minor compaction会阻塞写入,这个我不太明白为什么会阻塞。按理说冻结memtable,创建新的memtable就可以
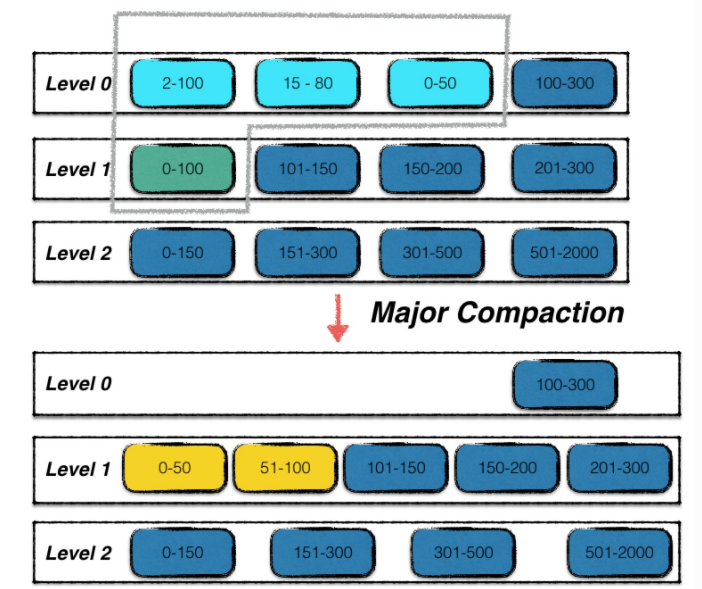
当以下几个条件触发时,会进行major compaction:
* 0层文件数量超过预订的上限
* level i层文件的总大小超过了10^i MB
* 某个文件无效读取的次数过多
因为0层有overlap,所以0层文件过多会影响效率,所以要限制0层文件的数量
对于非0层文件来说,因为0层文件的key取值范围很大,所以会导致每次合并时一层文件的输入量也很大,因为你要覆盖0层文件的key range。所以我们也要控制非0层文件的个数。
对于无效读取的情况,是因为leveldb希望进行错峰合并,因为有可能同一时刻有多个层达成了major compaction的条件,所以我们需要大量的资源进行合并

所以在sstable的元数据中,有一个额外的字段seekLeft,默认为文件大小除以16KB
我们记录每次用户访问的第一个sstable文件,如果文件命中,则不做任何处理,否则让seekLeft减一,当seekLeft等于0的时候,进行错峰合并
过程
compaction分为以下几步:
1. 寻找合适的输入文件
2. 根据key重叠情况扩大输入文件集合
3. 多路合并
4. 积分计算
寻找输入文件
对于level 0层文件数过多或者level i层总量过大的场景来说,采用轮转的方法。我们记录上一次该层合并文件的最大key,下一次选择在此key之后的首个文件
对于错峰合并,起始文件就是查询次数过多的文件
扩大输入文件集合
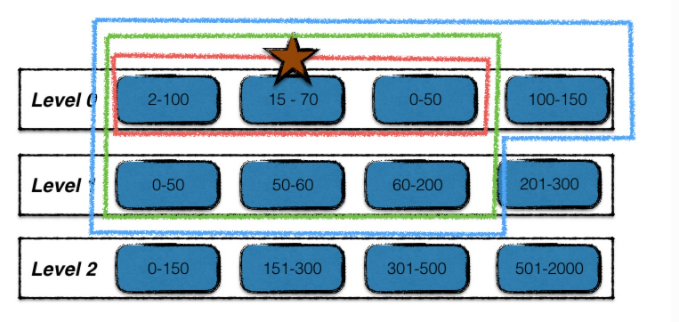
如下:
1. 红星标注的为起始输入文件
2. 在level i层中,查找与起始输入文件有重叠的文件,如图中红线
3. 利用level i层的输入文件,在level i + 1层中找重叠的文件,为图中绿线
4. 在不扩大level i + 1层文件的前提下,找level i层中有重叠的文件,如图中蓝线
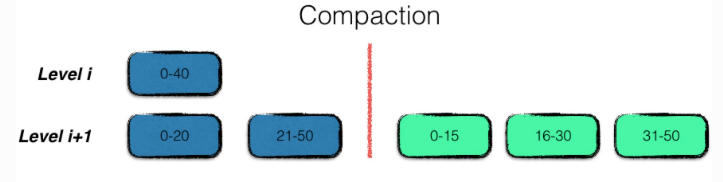
多路合并
多路合并即将输入文件按序归并,输出到level i+1层
积分计算
即重新计算文件个数以及大小,从而挑选出下一次需要合并的层数
- 对于0层文件,该层的分数为文件总数/4
- 对于非0层文件,该层的分数为文件数据总量/数据总量上限
分数超过1就会作为下一次合并的层数
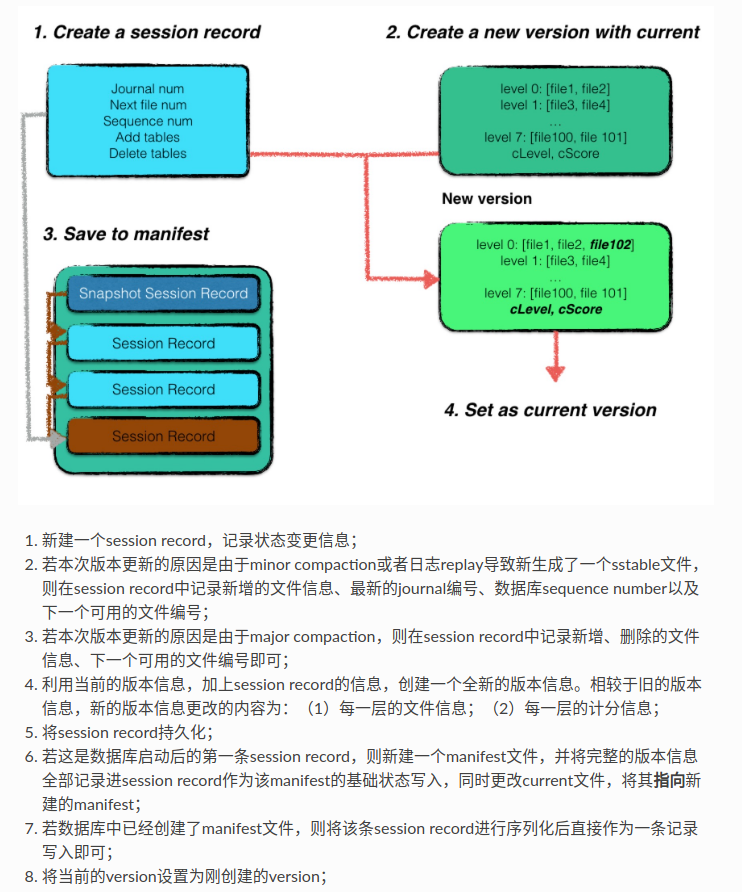
我突然想到一个问题,他没有说压缩时候的一致性。我猜测应该是通过原子的rename来进行的。并不是,是通过版本
版本控制
manifest文件专用于记录版本信息。一个manifest文件中有多个session record,一个session record记录了从上一个版本到该版本的变化情况。包括:(1)新增了那些sstable,(2)删除了那些sstable,(3)最新的journal日志文件标号
(所以看起来是通过版本信息来实现一致性的)
每次leveldb完成了compaction等修改sstable的时候,就会进行版本升级

Recover
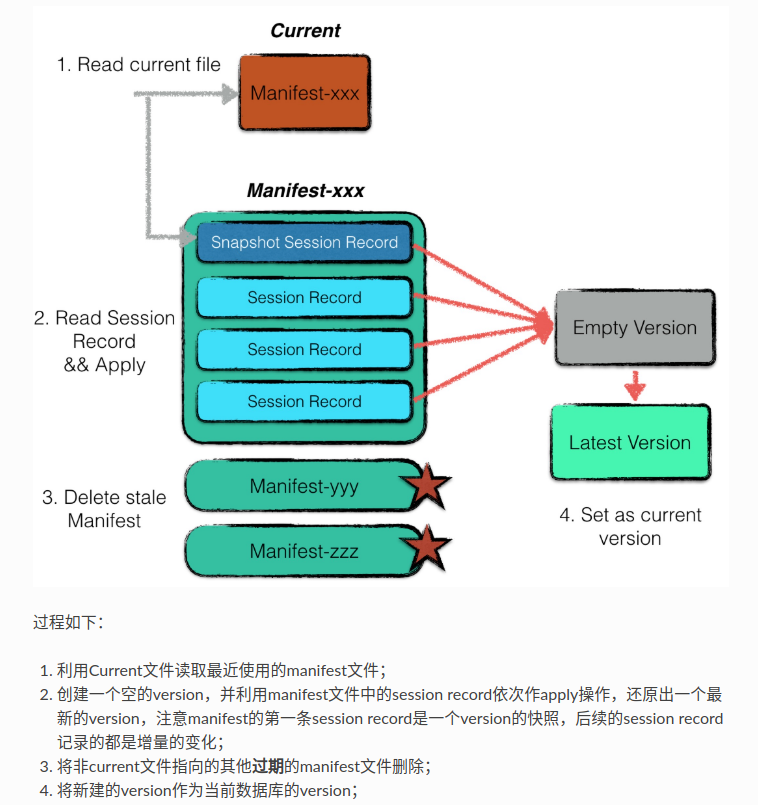
异常处理

多版本并发控制
当我们用迭代器读取某个sstable的时候,如果后台的major compaction完成了合并,就会试图删除sstable文件。最简单的方式就是加锁,但是这样会阻塞后台的写操作
leveldb使用了MVCC,体现在:
1. sstable是只读的,所以每次compaction不会影响现有的读操作
2. sstable具有版本信息,所以可以保证读写操作是针对于相应的版本文件
3. compaction生成的文件会在合并完成后才写入元数据,所以读操作不会看到他的写
4. 通过引用计数来控制删除

文章评论