背景
隔离的定义(为了清晰我就贴原文而不是自己翻译了)
Database isolation refers to the ability of a database to allow a transaction to execute as if there are no other concurrently running transactions
隔离的目的就是我们在并发执行事务的时候不希望一个事务的读写操作作用于一些临时的,错误的,或者不完整的数据
最强的隔离级别被成为可串行化(serializability),即并发执行事务的最终状态等价于某种串行执行顺序所得到的状态。
一致性(不是ACID中的一致性)这个词来源于共享内存的多核处理器中。他的目的在于指定在并发的执行中,一个线程是否可以感知到其他线程的写操作。(其原因是现代处理器的访存优化,以及编译器和处理器对于指令的重排序所导致的)
在分布式数据库中的原因则是我们在异步的复制副本,所以在读值的时候就可能读到的不是这一时刻最新的值。

这个例子中,P3的读虽然读x的值是0,但是仍然满足了顺序一致性。因为我们可以认为P1中的W(X=5)发生在P3的读之后,而发生在P4的读之前。这时候所有的线程都可以对于这些操作的一个全局执行顺序达成一致
当我们把一致性的概念拓展到事务模型的时候,我们就需要把隔离级别和一致性级别一起考虑。因为隔离级别定义了一个事务能够读到那些值,而一致性级别同样定义了读操作可以读到那些值。这种概念上的重叠导致了很多的困惑。
Understand the difference between isolation and consistency
两个事务,都是做read-modify-write操作。在提供了线性化一致性的情况下,每个操作的读写都作用于最新的副本。但是仍然出现了错误。

因为consistency level是用来描述单一操作的,而不是作用于一组需要被原子提交或者中止的操作中。所以当我们引入了事务的概念的时候,就需要引入隔离的保证。单独的consistency是不可行的
反过来,如果我们只保证隔离而不保证一致性呢?
一个time travel的例子,T3发生在T2后,但是读到的是T2前的值

在极端的情况下,我们只保证可串行化而没有一致性的保证的情况下,数据库的任何读操作都可以返回一个空集,代表这个操作被排序在了任何一个写操作的前面。本质上来说是因为可串行化允许了事务可以go back in time
隔离级别指定了对于并发的事务来说,他们应该怎么操作。如果两个事务没有同时运行,那么他们自己本身就是完全隔离的。这就是为什么在最高级别的隔离状态下,仍然可能发生time travel
很多的一致性级别都提供了实时的保证,比如线性化保证了非并发的操作是根据real-time排序的。而sequential consistency和causal consistency也保证了单线程下的实时性。
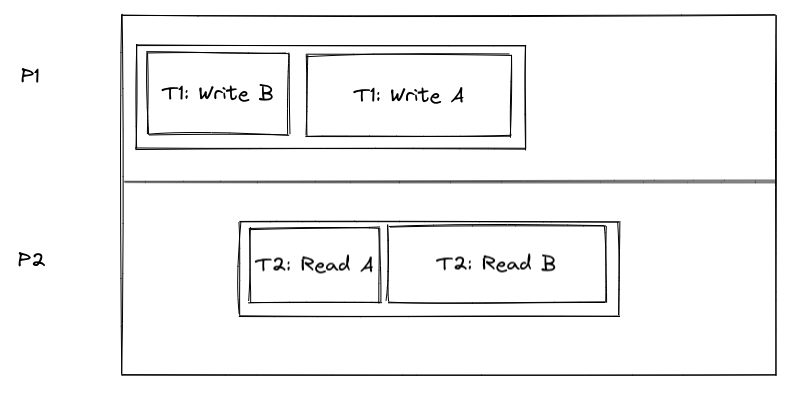
举一个将isolation和consistency结合起来的例子。在这个例子中,T2的读B在不考虑隔离级别的情况下应该是可以读到T1的写B的,但是如果这样的话T1就要排在T2前面,从而需要T2的读A也要成功读到T1的写A。
对于CRDB来说,通过clock来构造一个全序关系,比如读B的时候读到的是最新的版本,那么在提交的时候就可以感知到A的写入,从而也读到最新的A。否则如果clock认为T2在T1之前,那么就读之前的快照即可。
Mix of Isolation and Consistency
serializability是最高级别的隔离保证,但是这里还有很多他的变种,one-copy serializability, strong session serializability, strong write serializability, strong partition serializability, strict serializability
这里解释一下后面这三个,strong write对应了写操作的线性化,但是只读事务则是sequential consistency(Replicated PostgreSQL)。strong partition则保证了分区内部是线性化的,而跨分区的事务则是sequential consistency的(CockroachDB)。strict则是表示全局的可线性化(Spanner),他保证了如果一个事务X在Y发生前就结束了,那么在total order中X要被放到Y前面
Anomalies are possible under serializability
immortal write
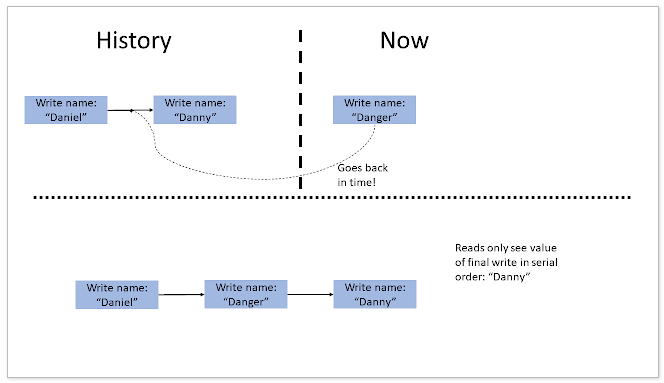
新加入的写发生在了一个过去的版本,从而导致观测不到最新的写
stale read
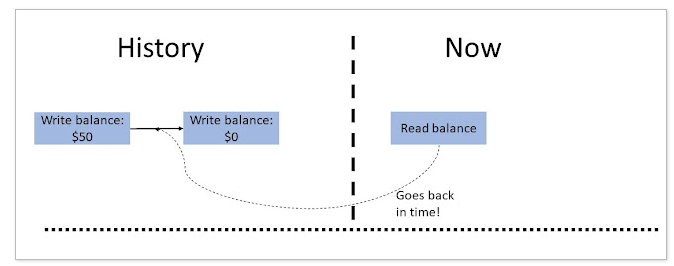
即读到的不是最新的值,在异步复制的系统中极为常见。
causal reverse
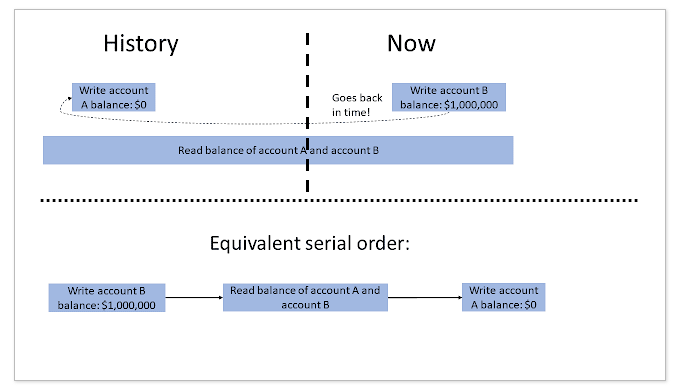
因果颠倒。这里的例子是一个事务写A的值,一个事务写B的值,然后一个事务去读取A和B的值。
CRDB不会去等待时钟是最大偏移时间来提交一个事务
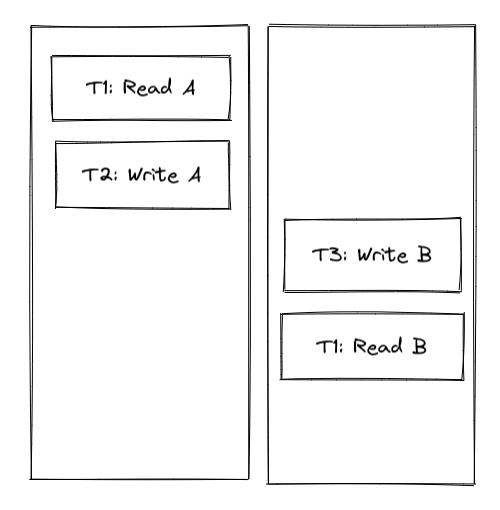
对于这种情况来说,事务2在现实中发生在事务3之前,但是由于时钟的偏差(或者逻辑时钟跟踪不到),导致系统中事务2的时间戳比事务3还大。那么在1的观测角度来看就出现了causal reverse的情况
对于结合Isolation的一个表
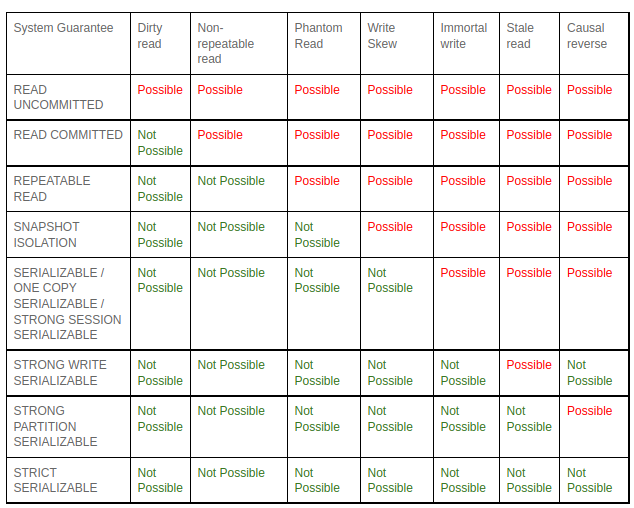
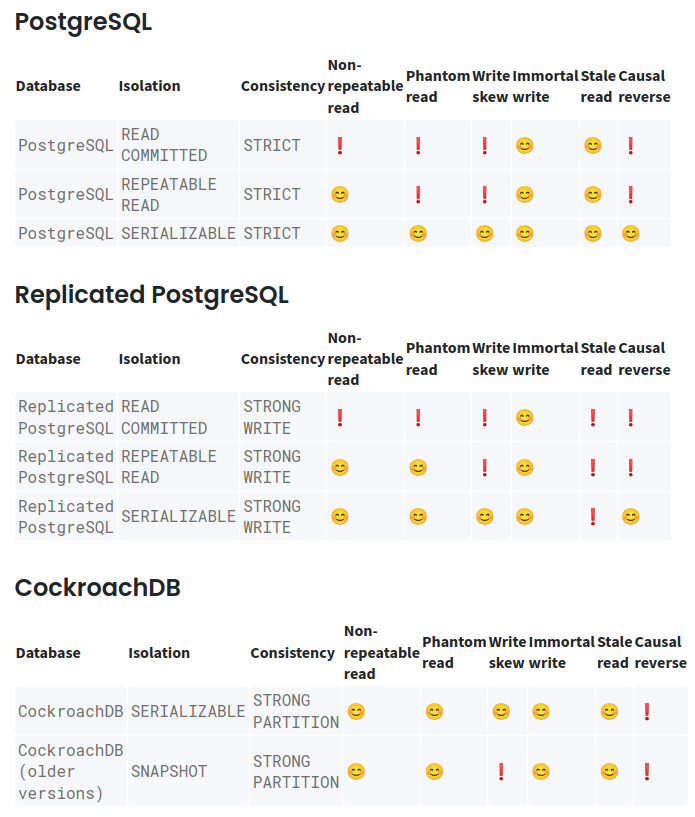
根据这个表可以去验证一下刚才说的一些东西
比如Replicated PostgreSQL,是主从的数据库,提供的是strong write,那么他们就有可能出现stale read,但是由于他们不会分片(以及一些其他措施),所以他们不会出现Causal reverse。而Strong write保证了immortal write不会出现
对于CRDB来说由于是分片的,并且由于时钟偏移的原因,他们可能出现causal reverse(causal reverse肯定发生在不同分片中,因为跨分区的事务由于时钟原因不能保证线性化)

文章评论