Recall Transaction in DBMS
整理一下DDIA中事务这一块
事务让我们可以为上层提供一个非常强大的抽象,而不需要将具体的细节暴露给上层
事务所提供的保证,即ACID,分别代表原子性,一致性,隔离性以及持久性
有的不符合ACID的系统有时被成为BASE,即基本可用性(Basic Available),软状态(Soft state),最终一致性(Eventual consistency)
原子性,指的是我们可以将事务内包含的一系列操作转化为原子操作,即要么所有的操作都发生了,要么一个也没发生。注意原子性并不关乎多个操作的并发性,因为这是隔离性所保证的
一致性,在不同场景中有着不同的含义,所以请不要把他和其他地方的一致性弄混,比如最终一致性,CAP中的C表示线性化。而ACID中,一致性指的是数据库处于应用程序所期待的预期状态。比如银行中,我们希望总共的钱是不变的。如果一个事务从一个有效的状态开始,并且途中的操作都没有违反约束,那么最后的结果也就是有效的状态。本质上来说一致性是应用层的任务,因为他们需要正确的定义事务来保证一致性。原子性,隔离性和持久性是数据库自身的属性,而一致性则更多是应用层的属性(提出ACID的作者本人也说过C只是为了让ACID更加顺口,当时并非认为这是很重要的一件事)
隔离性,即并发的多个事务相互隔离,他们不能相互交叉。就好像是这个事务是数据库上运行的唯一一个事务一样。
持久性,即保证事务一旦提交成功,即使数据库崩溃或存在硬件故障,事务所写入的数据也不会丢失。对于单节点的数据库,持久性意味着数据已被写入非易失性存储设备,如硬盘和SSD。对于支持远程复制的数据库,持久性则意味着数据已经成功复制到多个节点。
后面的问题就主要是关于原子性和隔离性的东西了
利用日志来保证原子性和持久性,并用并发控制的手段来保证隔离性
弱隔离级别
读-提交
1.读数据库的时候,只能看到已经成功提交的数据(防止脏读)
2.写数据库的时候,只会覆盖已经成功提交的数据(防止脏写)
如果我们看到了一些未提交的数据,之后这些数据的事务中止了,那么我们就看到了一些稍后将被回滚的数据
脏写则是可能导致更新丢失,或者是由于覆盖了未提交的数据导致了不可恢复的状态
实现读-提交
通过行级锁来防止脏写,修改对象的时候,要或的对象上的锁,并持有锁到事务提交
我们也可以通过相同的锁来防止脏读,但是会影响效率
大多数数据库的策略是:对于每个待更新的对象,数据库都会维护其旧值和当前持锁事务将要设置的新值两个版本。在事务提交之前,所有其他读操作都读取旧值; 仅当写事务提交后,才会切换到读取新值
快照级别隔离
读提交有一个确认就是他会导致不可重复读,虽然两次读到的数据都是提交的,但是还是可能导致出现问题,比如我们常用的read-modify-write
快照隔离的思路就是每个事务都从数据库的一个一致性快照中读取。事务最开始读取的就是最近的一个版本的数据,即便是之后数据有改动,事务也只能读到特定时间点的旧数据
实现快照级别隔离
和读提交类似,同样是使用写锁来防止脏写。这意味着正在进行写操作的事务会阻止同一对象上的其他事务。但是读操作则不需要加锁。
考虑到多个正在进行的事务可能会在不同的时间点查看数据库状态,所以数据库保留了对象多个不同的提交版本,这种技术因此也被成为多版本并发控制(MVCC)
在快照级别隔离的存储引擎中往往使用MVCC实现读-提交。对于每一个不同的查询单独创建一个快照。而快照级别隔离则是用一个快照运行整个事务
来一个例子
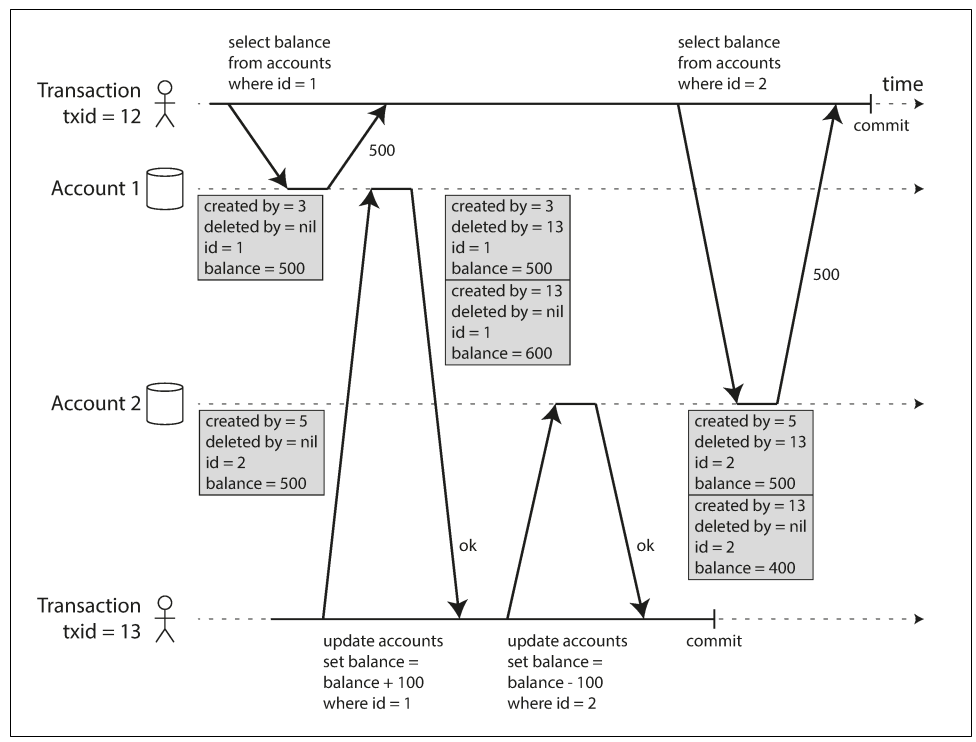
一致性快照的可见性规则
- 每笔事务开始的时候,数据库列出所有当时尚在进行中的其他事务(即尚未提交或终止),然后忽略这些事务完成的部分写入,即不可见
- 所有中止事务所做的修改全部不可见
- 较晚事务ID所做的任何修改不可见,不管这些事务是否完成了提交
- 除此之外,其他所有的写入对应用查询可见
写倾斜
当两个事务读取相同的一组对象,然后更新其中的一部分,不同的事务可能更新不同的对象。则此时可能发生写倾斜
产生写倾斜的例子遵循这样的范式:
- 首先输入一些匹配条件,即采用select查询所有满足条件的行
- 根据查询的结果,应用层代码决定下一步操作
- 如果应用程序继续执行,他会发起数据库写入并提交事务
而这个写操作会改变第二个步骤作出决定的前提条件。如果提交写入后在重复执行之前的select,就会返回完全不同的结果
在一个事务中的写入改变了另一个事务查询结果的现象成为幻读(这里我认为是更广义的幻读)
普遍意义上的幻读则是一些插入或删除操作,到是我们无法用锁来锁住某个元组,从而导致两次读之间出现了偏差。
但是当我们用MVCC去解决这种问题的时候,虽然两次读是相同的,但是由于另一个事务的修改影响了当前事务的决策,导致他作出了错误的决策。
解决问题的方法可以是实体化冲突,因为出现这个问题的根本原因是我们没能处理潜在的冲突,所以将冲突实体化为一组具体的行冲突就可以。但是一般不推荐这种方法
幻读和不可重复读
在stackoverflow中有这么一个回答
幻读指的是重复的查询,他们返回了不同的结果。而不可重复读指的是相同的一行,他们返回了不同的结果。
在2PL的实现中,不可重复读可以简单的在两次读之间加锁进行解决。而幻读则需要涉及到意图锁等手段。
对于MVCC来说,由于我们读的永远都是快照,所以这两种情况都不可能出现。
基于过期的值做出决策/修改的情况有两种,分别是写倾斜和更新丢失。不可重复读和幻读都会导致我们读的值是过期的值,从而影响读写事务的异常
对于更新丢失来说,指得是两个事务修改相同的一个值。这种情况下我们是有办法追踪到异常并中止的。比如Postgres在更新的时候,如果发现有并发的更新的时候,就会abort掉后写的那个事务。
更新丢失貌似不局限于read-modify-write,比如盲写的情况。这时候可以这么考虑,对于两个盲写的事务,更新丢失是无法避免的。对于一个盲写一个read-modify-write的事务来说,则有可能出现更新丢失。那么这时候的成因仍然是读到了过期的值。所以可以这么认为——即更新丢失是由于基于过期值的决策导致的。
但是对于写偏斜来说,两个事务修改的是不同的值,这时候冲突不发生在写上,我们就不能只通过写写冲突来判断,这就要求我们同时跟踪读集和写集,进而防止依据过期的值来作出决策。
串行化
最简单的就是实际真正的串行执行来得到串行化
2PL
两阶段加锁可以带来串行化
- 如果事务A已经读取了某个对象,此时事务B想要写入该对象,那么B必须等到A提交或中止后才能继续。以确保B不会在事务A执行的过程中间去修改对象
- 如果事务A已经修改了某个对象,此时事务B想要读取该对象,那么B必须等到A提交或中止之后才能继续。从而防止我们读到旧值
这么多锁可能引起死锁,所以我们还需要一个管理器来管理等待关系
或者用TO来对事务排序,在出现等待的时候,根据顺序主动abort一些事务来防止死锁
上面有提到,对于幻读或者写偏斜问题,我们可能没有具体的行来让我们锁住,从而防止冲突。
所以引入谓词锁,即锁住满足搜索条件内的所有对象。这样当出现新的插入或者删除的时候,这些操作也会被阻塞
但是谓词锁性能不佳。所以大多数2PL的数据库是使用索引区间锁,在索引上把一块区域都锁上。这样新的事务尝试更新的时候,就会尝试更新索引,从而引发冲突。
可串行化快照隔离(SSI)
SSI基于快照隔离,事务中的所有操作都是基于数据库的一致性快照(这是和OCC的主要区别,OCC则是作用于相同的副本)
主要就是为了解决写倾斜,也就是基于过期的条件做决定的问题。为了提供可串行化的隔离,数据库必须检测事务是否会修改其他事务的查询结果,并在此情况下中止写事务
两种情况会导致查询结果改变
- 读取是否作用于一个过期的MVCC对象
- 写入是否影响即将完成的读取
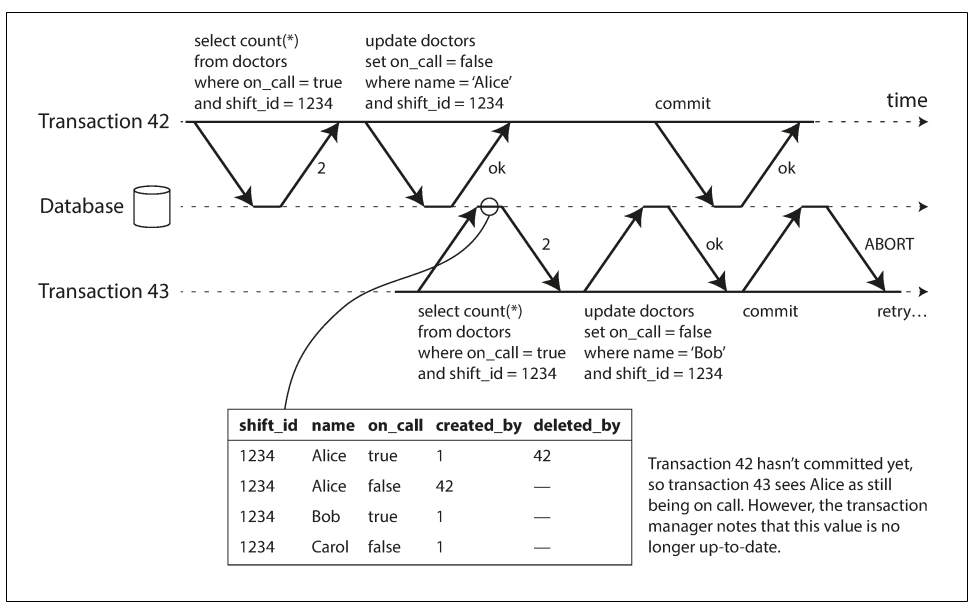
这里就是43号事务读取了一个过期的MVCC对象,并根据此作出了决策。所以我们需要abort他
数据库需要跟踪那些由于MVCC可见性规则而被忽略的写操作,当事务提交的时候,数据库就会检查是否存在一些当初被忽略的操作现在已经完成了提交
之所以不是读的时候就abort,是因为可能42号事务有可能abort掉。所以我们提交的时候再去检查
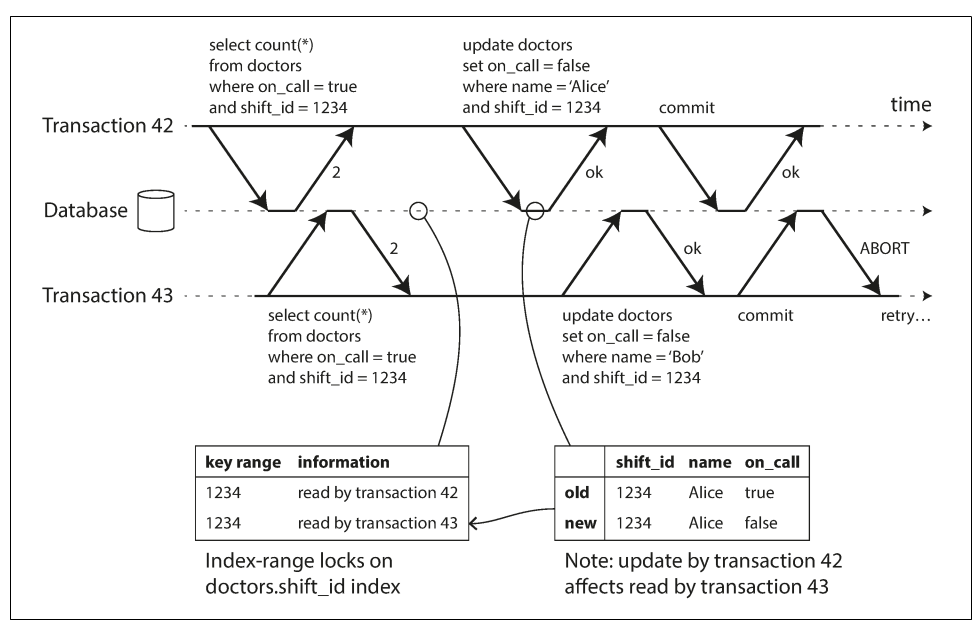
在索引上记录了事务的读写操作,这里发现42的写入影响了43的读。所以当43提交的时候,就会abort。
当一个事务尝试修改时,他就会检查索引,从而确定是否最近存在一些读目标数据的其他事务。并且在读事务提交的时候通知他们,数据已经发生了变化
这样看过来,可重复读并不是一种很好的隔离的解决思路。因为即便是我们读到了以前读到的值,但是真正的改变可能已经发生了。这里就有种读快照骗自己的感觉。那么就可能导致后续的决策不再是有效的。所以我们在SSI中追踪这种关系,并解决。从而达成可串行化。

文章评论