通过functional model和用户指定的map和reduce操作,我们可以很容易的将这些计算并行化。
通过re-execution作为主要的fault tolerance的手段
2 programming model
map接受input pair,并生成一组中间键值对。MapReduce Library会把相同key的键值对的所有value组合在一起,并把他们传给reduce
reduce接受一个key以及对应的一组value,他将这一组值合并到一起,并返回给用户
一个计算每个document的单词数的例子
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
更多的例子:
distributed grep: map对于每一行,如果他match pattern就放到输出中,reduce是直接输出
count of url access frequency: map对于每一个网页请求生成(URL,1),reduce进行求和
reverse web-link graph:对于每一个从source页面引出的URL target,生成(target, source),然后reduce组合他们生成(target, list(source))
term-vector per Host:term-vector是一个文档的一个(word, frequency)列表,即计算每个词出现的频率。对于一个host的下的每个document来说,都生成对应的(hostname, term-vector),然后reduce将这些term-vector加起来,并丢弃掉低频的词,就可以得到每个host的热点词
inverted index: map对于每一个document中的word,生成一个(word, document ID)的序列,然后reduce用来合并并输出(word, list(document ID))。我们可以很容易的来增强这个计算来得到每个单词的位置
distributed sort:map对于每个record生成(key, record),key就是用来排序的key,然后reduce直接输出即可。因为mapreduce的库会根据key进行排序
3 implementation
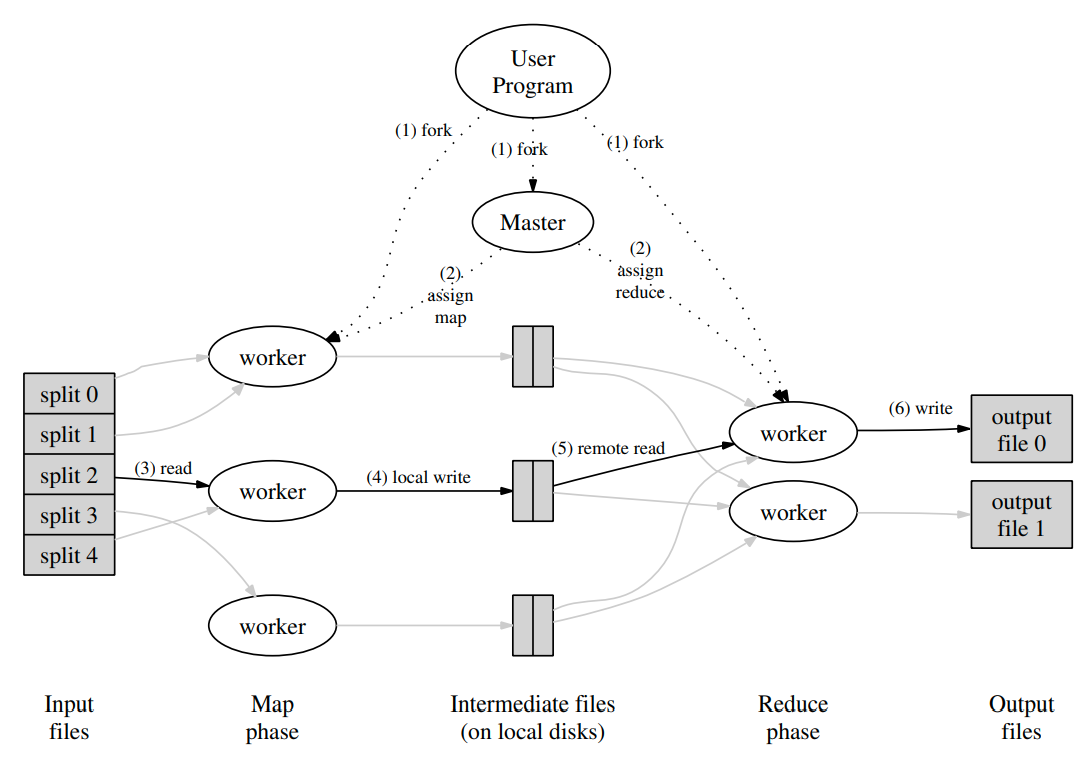
输入数据会被自动partition成M份,放到不同的机器中并行的处理
通过用户指定的partition function和partition number R,所有的中间结果会被分成R份,然后再应用reduce
figure 1是一个overall flow
- MapReduce Library会首先将数据分成M份,然后在集群中启动程序
- 这些程序中有一个是master,其余的都是worker。master会将M个map task和R个reduce task分发给worker
- 拥有map任务的worker会读取输入,从输入中解析键值对,并传给map函数。中间结果会被存储到内存中
- 缓存的中间结果会周期性的写入到本地的磁盘中,并根据用户指定的分区函数分成R个区域。这些本地磁盘中的键值对的位置会被发送到master中,并由master转发给reduce worker
- reduce worker会通过RPC来读取map worker本地磁盘中的结果。当所有的数据的都读取完的时候,他会根据key进行排序,从而将相同键的所有值group到一起。之所以需要排序是因为可能中间结果很大,我们不能把数据放到内存中
- reduce worker会读取所有的中间数据,并将key和对应的一组value传给reduce function。最终结果会被追加到这个reduce分区中的final output file
- 当所有的map和reduce task都完成了,master会唤醒user program,最终回到user的代码中
最后的结果会在R个output file中,文件名由user指定。通常user不需要去组合这些output file,因为这些文件通常作为下一个MapReduce的输入文件,或者传给其他的分布式应用
3.2 Master Data Structures
master保存了每一个task的状态,以及对应的worker machine的标识
master还是一个用来将map输出的中间结果文件位置转发给reduce worker的通道。所以对于每一个完成了的map task,master就会保存结果文件的size和location。这个信息会被逐步发送给reduce worker(原文中写的是incrementally,但是我不确定这里增量的含义是什么)
3.3 Fault tolerance
master会定期的ping worker,如果没有回复则认定worker failed。所有的在failed的worker上完成的或者进行中的map任务都会被重置为idle,并会被调度器重新调度
因为中间结果是存储在本地磁盘上,所以在failed worker上完成的map任务也需要重新执行,因为我们无法访问这些结果。但是对于reduce来说,完成的任务不需要重新执行,因为reduce的结果存储在global file system中(GFS),提供了容错
当map任务切换机器的时候,所有的reduce task都会接到重新执行的通知。没有读取完数据的会从新的机器上重新读取数据(不太明白为什么要重新执行)
对于master failure,我们可以周期性的进行checkpoint。但是论文中提到我们只有一个master,不太会失效。但是如果master失效了,我们会终止MapReduce计算
3.4 Locality
为了节省网络带宽,master会考虑输入文件的位置信息,并尝试在包含相应输入数据副本的机器上安排map任务。如果失败的话,他也会享受将任务安排在副本附近(同一个交换机上)
3.5 Task Granularity
理想情况下,我们希望task的数量远大于worker的数量,因为这样我们可以实现动态的负载均衡,当一个worker失效的时候,我们可以将他的任务分发到其他的worker上
选择M的时候希望输入的数据是16MB到64MB之间,这样可以利用locality(配合GFS),而对于R来说一般是worker数量的一个小的倍数
3.6 backup tasks
延长计算总时间的通常是因为有机器掉队,我们需要很久才能计算出最后的几个map或者reduce task
掉队的原因有很多,比如原本机器上有任务,资源竞争,机器损坏等
当MapReduce操作接近完成时,master就会调度backup execution来执行剩下的task。只要primary或者backup一个完成了执行就完成了task。
4 Refinements
用户指定了reduce的数量R,默认情况下用hash分区,但是用户也可以自己提供分区函数来达到更好的效果
MapReduce保证在给定的分区中,KV pair是按顺序处理的。所以我们也就可以得到一个sorted的输出文件。对于后续需要进行高效查找等操作是非常有用的
一般来说,每个map输出得到的kv pair很多时候都是重复的。比如word count的例子,我们会得到大量的值为1的记录。我们可以让用户指定一个combiner function,可以在跨网络传输之前对数据进行部分的合并,从而减少网络带宽的需求
一般使用相同的代码来实现reduce和combiner。combiner会在每个执行map task的机器上执行。
有的时候由于用户代码存在错误,导致在某些record上会出现确定性的crash。我们可以选择忽略一些record并继续前进
每一个worker都有signal handler用来捕捉错误。MapReduce库会将一个序列号存储到全局变量中,如果user code出现错误,signal handler会给master发送一个包含这个序列号的信息。如果master发现在某个record上出现多次错误,他就会指示在下次re-execution的时候跳过这个记录
counter,MapReduce提供了一个counter object,可以放到user code中用来计数。worker会定期的将counter的值发送给master(放在ping的回复中),master聚合这些值并当MapReduce结束的时候返回给用户。这些值也会显示在MapReduce的主状态页上,用来查看实时计算的进度。
6 experience
MapReduce的实现依赖于负责分发并运行用户task的集群管理系统
MapReduce通过受限制的编程模型来把问题划分为大量细粒度的任务,从而让我们可以进行动态调度,以便让更快的worker处理更多的任务。同时还允许我们在接近结束的时候去执行那些比较慢的任务,从而加速执行时间
MapReduce通过自动并行execution以及提供透明的容错机制来提高开发效率
8 conclusion
- MapReduce模型容易使用,隐藏了并行化,容错机制,局部性优化以及负载均衡的细节
- 大量的问题都可以通过MapReduce来表达
Learned
- 通过限制编程模型可以让并行和分布计计算,以及容错变得更简单
- 网络带宽是缺乏的资源,大量的优化都是为了减少网络带宽
- 通过redundant execution来减少较慢的机器带来的效应(木桶效应),同时进行容错

文章评论