First pass
The design of GFS has been driven by key observations of google application workloads and technological environment
在分布式系统的环境中,component failures are the norm rather than the exception.
当数据快速增长,去管理billions级别的kb大小的文件是unwise的(因为我们需要管理大量的inode,并且读写文件以及对应的block size也要重新考虑)
accessing pattern, 大多数文件都是通过append来添加数据的,同时读取也是顺序的。这个特性成为优化性能和保证原子性的重点
通过co-design applications and file system API来增加系统的灵活性。通过relaxed GFS`s consistency model来简化文件系统。引入atomic append operation来避免额外的同步手段
通过constant monitoring, replicating curcial data, and fast automatic recovery来提供fault tolerance. 用checksumming来检测data corruption
分离file system的control和data transfer。通过租借chunk以及提高chunk size来减少master server的操作,从而让simple centralized master不成为瓶颈
Second pass
2.1 assumptions.
- system is built from inexpensive commodity
- system stores a modest number of large files
- workloads consist of large streaming reads and small random reads
- workloads have many large sequential writes that append data to files. Once written, files are seldom modified again
- well-defined semantics for concurrent append operations. Atomicity with minimal synchronization overhead is essential
- focus on high bandwidth(throughput) than low latency.
2.2 interface
GFS support usual file operations. Moreover, GFS has snapshot and record append operations. Snapshot creates a copy of a file or a directory tree at low cost. Record append allows concurrently appending the files while guarantee the atomicity.
2.3 architecture
single master and multiple chunkservers
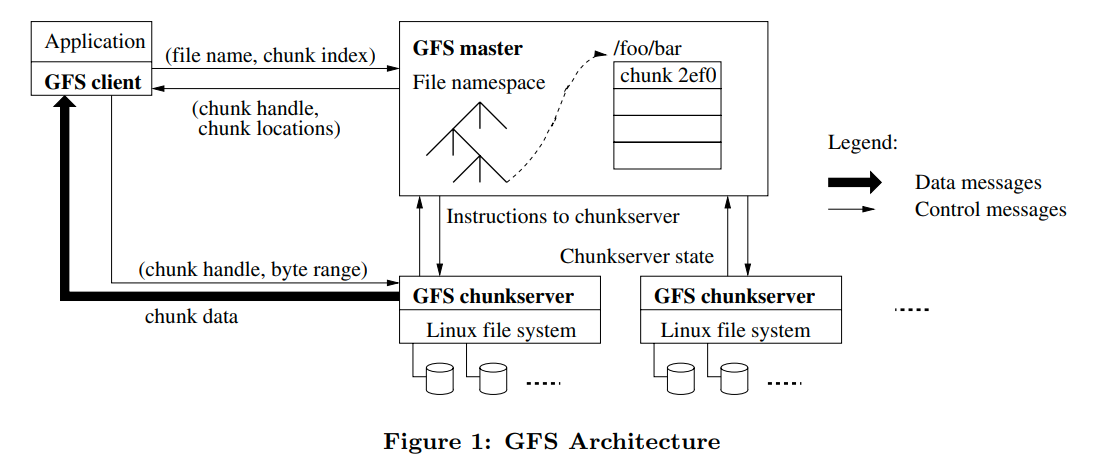
files are divided into fixed-size chunks. Each chunk is identified by an immutable and globally unique 64bit chunk handle assigned by the master at the time of chunk creation.
For reliability, each chunk is replicated on multiple chunkservers. By default, we store three replicas. User can designate different replication level for different regions for the file namespace.
Master maintains all file system metadata. This includes the namespace, access control information, the mapping from files to chunks, and the current location of chunks. It also controls system-wide activities such as chunk lease management, garbage collection of orphaned chunks, and chunk migration between chunkservers. Mast periodically communicates with each chunkserver in HeartBeat messages to give it instructions and collect its state.
Clients interact with the master for metadata operations, but all data-bearing communication goes directly to the chunkservers.
这里原文有一句:We do not provide the POSIX API and therefore need not hook into the Linux vnode layer. Linux中的vnode是对不同文件系统的一个抽象,比如NFS中不存在inode,这里通过vnode的抽象层来为上层提供一个更加简洁的封装。而GFS没有提供POSIX的API,所以他也就不能作为一个单独的文件系统用vnode来抽象。
Neither the client nor the chunkserver caches file data. 因为cache这样的大文件对并不会有太高的收益,并且文件太大也不容易去cache。不使用cache还可以让我们不去考虑cache coherence问题来简化系统。(Client还是会cache metadata的)。对于chunkserver来说,因为chunk本身存储在linux之上,所以linux的buffer cache就会帮我们进行cache
2.4 single master
single master的好处, simplifies design, enable master to make sophisticated chunk placement and replication decisions using global knowledge.
client never read and write file data through master. It asks the master which chunkserver it should contact. It caches this information for a limited time and interacts with the chunkservers directly for many subsequent operations.
通过上面Figure 1的一个解释
- 通过fixed chunk size, client可以将filename和byte offset转化成一个chunk index
- 发送file name和chunk index
- master会把对应的chunk handle和replicas的位置发回给client
- 然后client就会以filename和chunk index为键来缓存master返回的信息
- client向replicas发送request(most likely the closest one),这个request包含了chunk handle和byte range
之后读取相同位置的操作就不需要在让client和master交互了,直到cache的信息过期,或者file被重新打开了(这个我不太清楚是为什么)
client在向master请求的时候可以请求多个块,master回复的时候也可以返回多个信息。从而更多的减少client与master的交互(将request进行batch)
2.5 chunk size
选择一个大的chunk size(64mb)有几个优点
- 减少client-master的通信
- 在大数据块上,client可能要执行许多操作,通过与chunkserver保持持久的tcp连接来避免网络开销(比如chunk size小,那么我们就需要更多次的去查找新的chunk,从而需要更多次的tcp连接)
- 减少metadata的大小,允许我们将metadata放到memory中
大块的缺点就是对于小型的文件,可能只有一个chunk,如果许多client都去访问相同的文件,就会导致文件成为hot spot。但是对GFS的workload来说,这不是一个问题
然后是一个hot spot的例子和解决办法,这个我感觉还挺有意思的,所以记录下来
However, hot spots did develop when GFS was first used by a batch-queue system: an executable was written to GFS as a single-chunk file and then started on hundreds of machines at the same time. The few chunkservers storing this executable were overloaded by hundreds of simultaneous requests. We fixed this problem by storing such executables with a higher replication factor and by making the batchqueue system stagger application start times. A potential long-term solution is to allow clients to read data from other clients in such situations.
通过增加replication factor来分散读取压力,然后错开batch-queue system启动这个application的时间。更好的解决方法是允许client read from other client(P2P?)
2.6 metadata
metadata存储namespaces,file to chunk的映射以及每个replicas的位置
metadata都存储在master的memory中
对于namespaces和mapping通过operation log来记录他们的变化到disk中,并且复制到remote machines,从而保证他们的持久性
master不会存储chunk replicas的位置,而是当master启动的时候或者chunkserver加入cluster的时候去询问chunkserver他存储有关chunk的信息
将metadata存到master的memory中有两个好处,一是加速了master operation,二是方便master在后台周期性的去扫描master的状态,从而用来实现chunk的GC,re-replication(当chunkserver fail的时候),以及chunk migration(用于负载均衡)
master通过HeartBeat messages来监测chunkserver的状态,并且控制着chunk的placement。通过让master去监测chunkserver,而不是让master去存储chunk的位置信息,我们可以不用考虑有关chunkserver和master信息的同步
论文中有提到,要认识到是chunkserver对其拥有那些块有最终话语权,而不是master。所以尝试在master上去维护一个对chunk location的consistent view是没意义的
operation log记录了对GFS中的metadata的改变历史。他不仅是对metadata的一个persistent record,同时还定义了并发operation的顺序
对于用户的操作,我们会把对应的operation log存储到本地和远端来防止master失效。master会batch这些log的flush和replication操作,从而提高整体的系统吞吐量(和log based的file system一样)
同样,为了防止log的数量过多导致的重启时间过长,master在log超过一定数量的时候就会进行checkpoint
论文中提到checkpoint是一种B-tree的形式,可以直接映射到内存中,从而加速恢复。这里还不太清楚,看后面会不会细说一下
和fs一样,checkpoint不会阻塞后续的operation。当checkpoint的时候,master会切换到新的log file并且在新的thread中创建checkpoint(个人猜测应该会shadow一些页来保证操作的原子性,或者保证operation的幂等性)
2.7 consistency model
file namespace的修改是atomic的
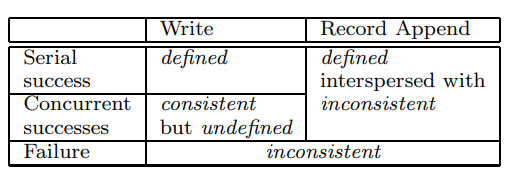
A file region is consistent if all clients will always see the same data, regardless of which replicas they read from.
A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety
When a mutation succeeds without interference from concurrent writers, the affected region is defined (and by implication consistent): all clients will always see what the mutation has written
当并发的同时写一个文件的时候,就有可能导致数据出现混合的情况,但是所有的writer都看到的是相同的数据。所以这是consistent,但是非defined的,因为我们不确定到底能看到是什么
GFS通过(a)在所有的replicas上以相同的顺序应用mutation,(b)使用version number检测stale的replica,来保证file是defined
在append的时候,如果当前chunk的空间不够了,GFS会选择在新的chunk上进行append,并返回对应的offset,而对于中间的一部分无效数据,GFS会插入padding或者重复的records
在写入的时候,每一个record都包含着额外的信息,比如校验和。在读取的时候,我们可以通过校验和来识别并丢弃这些padding和重复的records
3.1 Leases and Mutation Order
master将租约授权给某一个replica,称之为primary,然后primary来为所有的变更选择一个序列化的顺序,其他所有的replicas都根据primary选择的顺序进行变更
所以全局的变更顺序首先由master授权的租约顺序决定,然后再由primary指定的变更顺序决定
租约有一个初始的60秒的超时时间。只要有数据mutation,primary就可以无限的从master那里请求延长租约。请求和授权的操作是在HeartBeat message上进行的
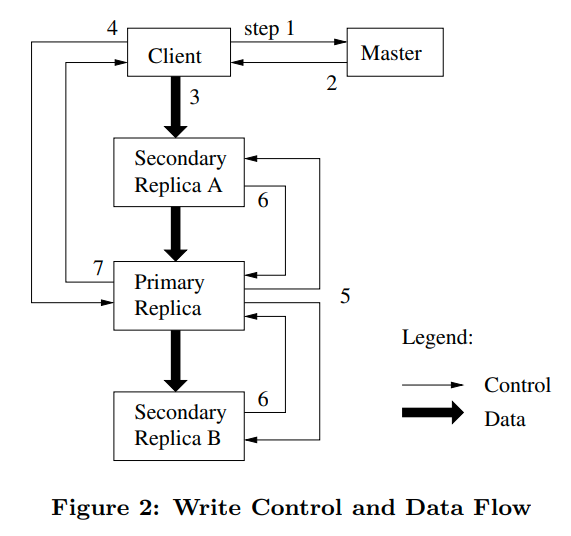
- client首先问master那个chunkserver是primary,以及其他副本的位置
- master回复primary以及其他副本的位置。client缓存这些信息
- client将数据发送给所有的副本。(而不是发给primary,再让primary发给别人)通过decouple数据和控制flow,我们可以根据网络拓扑结构来schedule数据流,从而提高性能
- 一旦所有副本都确认收到数据,client就会向primary发送写请求。primary将连续的序列号分配给他收到的mutation operation,并按照序列号顺序应用这些operation,从而保证序列化
- primary将这个请求转发给所有的从副本,从副本也按照序列号来应用operation
- 所有的从副本回复primary表示操作完成
- primary回复给client,如果出现了错误,则写入可能在主副本和部分从副本写入成功,则client认为写入失败,并且修改的区域处于inconsistent的状态。client会先重试几次3到7步,然后再回到开始进行重试(个人认为这块是防止primary过期或者其他问题,从而让master选择一个新的primary来领导修改)
3.2 data flow
control flow从client到primary,再到所有的replica
data flow则是以流水线的方式沿着特殊的(原文是carefully picked)chunkserver chain进行流动,从而最大化利用率
发送数据时,每一个机器都选择离自己最近的没有接受到数据的机器进行转发。只要一开始接受数据,就开始转发,从而减少延迟
论文中提到network topology is simple enough that distances can be accurately estimated from IP address
3.3 atomic record appends
append和上面的流程相同,但是有一点额外的逻辑处理。primary检查如果record append会导致当前chunk超过max size,那么他就会进行填充,然后叫所有的从副本也进行填充。并返回给client让他在下一个chunk上重试。
每次record append的最大限制是max size的四分之一,这样可以保证我们的无效数据在一个可接受的范围内
GFS不能保证所有的副本都是完全相同的,他只能保证数据会被原子的写入至少一次。所以为了让我们的append operation成功,数据必须是以相同的offset写入所有副本的,同时所有副本的长度也至少和添加后的record末尾相同。从而保证后续的append操作的offset会被分配到更高的offset或者不同的数据块
3.4 snapshot
通过COW来实现snapshot
当master接收到snapshot的操作的时候,他会首先回收有关chunk的租约,从而防止相关chunk的更改
然后他会log这次operation,并且将相关文件的metadata进行复制,所以新创建的文件也会指向相同的chunk
当client想要写chunk C的时候,master会发现chunk C的reference count是大于1的。然后master会找一个新的chunk handle C1。接着master会让所有拥有chunk C的server去创建一个新的chunk C1。GFS保证让data是在本地进行copy的,从而防止跨越网络的复制
之后master正常回复client,就和正常的写操作一样了
4.1 namespace management and locking
和传统的文件系统不同, GFS没有列出该目录所有文件的数据结构。GFS在逻辑上将其namespace表示为一个lookup table,他将完整的路径名映射到metadata。
加锁的方式就是从根目录向下加锁,从而保证操作的串行化
比如创建文件/home/user/foo,GFS会在/home和/home/user上获取读锁,并且在/home/user/foo上获取写锁。因为我们不需要修改parent directory的数据,所以不需要在父目录上获取写锁。在创建的文件上获取写锁可以防止同时创建相同名字的文件。(所以感觉lock更像是对一个字符串进行lock,因为这里没有实质的目录对象?)
为了防止死锁,获取锁的顺序要根据namespace tree上的level排序,同level下,用字典序排序
4.2 replica placement
GFS的节点具有多个级别,机器之间的communication可能跨越多个机架
我们要最大化数据的可用性,以及网络利用率。只在同一个机架上放置replica是不够的,因为可能出现交换机或者电源上面的问题,导致整个机架脱机。所以我们也需要跨机架放置副本
并且读取的情况下,我们可以利用多个机架的总带宽。但是同样的,写入也需要跨越多个机架。减缓了写的速度,但是提高了读取速度以及数据的可用性
4.3 creation re-replication, rebalancing
当master创建新的chunk时,他要考虑几点来选择放置chunk的位置
- 我们希望选择一个磁盘空间利用率低于平均水平的server
- 我们希望限制每个server最近创建chunk的数量,因为chunk的创建代表着后续会进行写操作
- 同时我们还希望在机架上分布这些副本
当副本的数量低于指定的目标的时候,GFS就会去重新复制这个块。每个需要重新复制的chunk都会根据一些因素来进行排序。比如缺失了两个副本的块会优先于缺失了一个副本的块。
master会选择优先级最高的块去复制他。新的副本放置的位置的选择和上面创建新chunk的要求是相似的。同时每个chunkserver会限制他用来进行复制操作的带宽(为了不阻碍用户的读取)
master会定期的对副本进行rebalances,他会检查副本的分布,以load balance和better disck space为目的移动副本。通过这个操作,master可以逐渐的fill一个新的chunkserver,而不是将很多新chunk放进去从而引发heavy write traffic。同时,master也要选择已有的副本去清除,为了平均free-space,他会优先选择free disk space低于平均水平的chunkserver
4.4 GC
当删除一个文件时,master会log这个操作,然后将文件重命名为隐藏的文件名
master定期扫描文件系统的时候,如果发现隐藏文件已经存在了三天以上,他就会删除他们。
master还会在扫描的时候识别出孤儿chunk,并删除这些chunk的metadata
在master和chunkserver的HeartBeat message中,chunkserver会汇报他有那些chunk,然后master会找到那些在metadata中不存在的chunk并回复给chunkserver,chunkserver就可以去删除这些chunk
这种垃圾回收的办法比起即时删除有几个优点。比如副本删除的消息可能会丢失,创建chunk失败的时候可能创建了master不知道的副本。
上面的方法提供了一种可靠的方法来清理无用的副本。并且他将垃圾回收合并到了master的后台活动中。他是分批进行的,所以成本是均摊的。master可以更迅速的回复client的请求。最后延迟回收可以防止出现意外,为不可逆转的删除提供了安全网
主要的缺点就是延迟删除可能会方案用户在存储空间紧张的时候对使用空间进行微调
4.5 stale replica detection
副本有可能变得过时。master为每个chunk维护了一个chunk version number来区分最新的和过时的副本
当master授权给一个chunk租约的时候,他会增加他的chunk version number并通知其他的副本(而不是每次写都增加版本号,因为如果有从副本失效的话,新的写入操作会失败)
master会通过GC来回收过时的副本
还有一种保护机制是当master通知客户端那个是primary时,或者在复制副本操作的时候,master会包含chunk的版本号。这样在客户端执行操作的时候,或者chunkserver从另一个chunkserver读取chunk的时候就可以验证这个版本号来保证访问的是最新的数据
5 fault tolerance and diagnosis
master有自己的副本,同时我们还有只读的shadow master用来保证可用性
由于GFS不能保证每个副本都是完全相同的,所以每个副本必须通过checksum独立的去验证数据的完整性
一个chunk会被拆分成64KB的blocks,每个block都有32位的checksum,checksum与用户数据分开存储
读取数据的时候,我们要验证与读取范围重叠的数据快的完整性。所以data corruption不会传播到其他的机器上
优化计算校验和,在append的时候增量的计算校验和
空闲的时候,chunkserver可以扫描和验证inactive chunks。这可以让我们检测到一些很少读到的数据中的损坏
6 Measurement
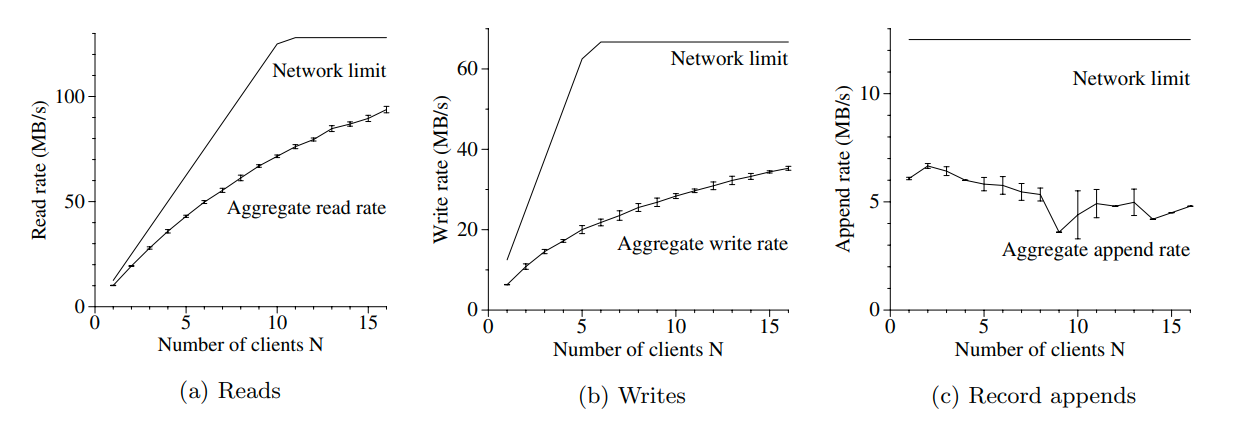
并发读,随着client增多我们的efficiency会降低,因为会出现冲突
并发写,之所以利用率较低是因为他没有很好的用pipeline的技术(个人猜测可能是因为他每次都写1MB,所以pipeline效果不好)
append,client增多的时候会出现冲突,所以效果不好
但是在实践中这不是一个大问题,因为当一个文件被占用的时候,其他的操作可以make progress
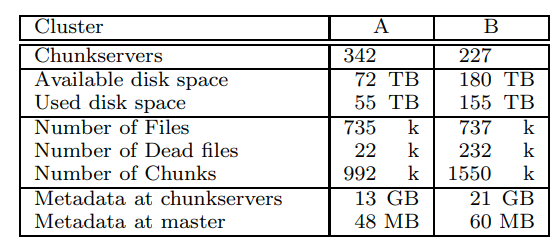
real world的数据
可以看到在chunkserver上面的metadata还是很多的,这些metadata就是64KB block的checksum,以及chunk的版本号
master上面的metadata还是很小的。大多数文件的metadata就是以前缀压缩形式的file name。其他metadata还有owership和permissions,从file到chunk的映射,chunk的版本号。还有chunk的副本的位置,和chunk的reference count(COW)
每个server的metadata相对较小,所以我们只需要很短的时间就可以将metadata读到内存中完成恢复。master会慢一些,他需要30到60秒来接收来自其他chunkserver的chunk位置信息
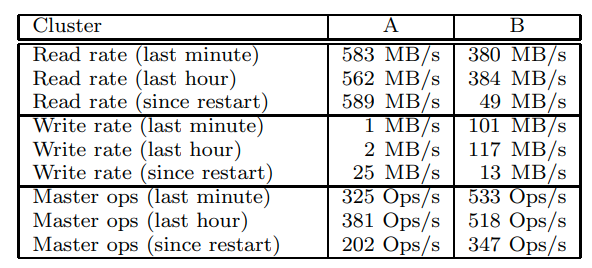
可以看到workload中读比写多很多
master的Ops只有几百,所以不会成为瓶颈
之前的master会顺序扫描查找特定文件,所以会导致bottleneck
现在的master会用二分搜索(应该是维护一个平衡树之类的东西)保证高效查找
如果需要进一步的优化,还可以添加查找缓存

可以看到master的workload主要是find location和find lease holder,对应了读和写两个操作
7 experiences
linux中的读写锁,在disk paging(读disk或者换页到disk)的时候,需要获取这个地址空间的读锁。当修改地址空间的时候,我们需要写锁,比如在用mmap的时候
论文中写到他们发现主网络线程会被阻塞住,当之前有磁盘换页的时候,所以他们选择用pread替换mmap来解决这个问题

文章评论