代码结构
Chunk
ChunkFactory.py,通过decorator注册chunking method
* chunking_by_seperators
* 定义了一些default text separator(如果希望自定义应该怎么做?传入不同的参数?)
* chunking_by_token_size
有一个通用的DocChunk类,用来包装不同的chunking method。他会吃config中的chunk_method。
也负责做Chunk的存储和读取。
* build_chunks
* 输入为若干个doc
* 通过配置中的chunking method,切分chunk
* 这里可以拆一拆的是doc相关的处理可以再往前放一放。比如doc reader -> postprocesser(用来append一些元数据,比如插入时间,id什么的)-> chunk
* 还有一些get的接口,暂时先不看
Graph
graph这边没有通用的接口,就是用factory根据config构造的
BaseGraph中抽了一些通用的方法。比如merge_nodes/merge_edges。
还有一个augment_graph_by_similarity_search用来给相似的点连接相似边的
readme里有一些对不同graph方案的总结
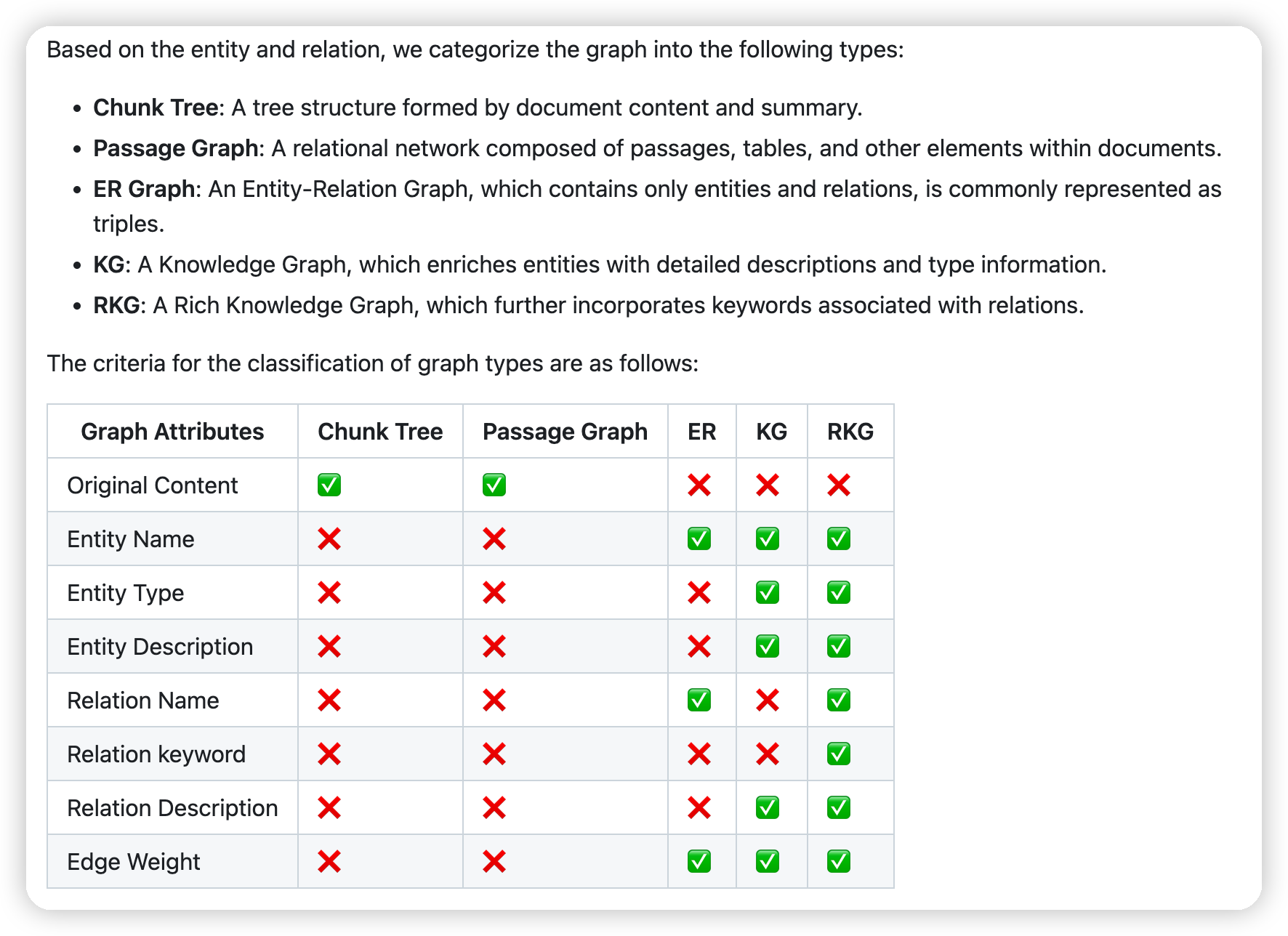
有一些可以关注的点:
* ER Graph
* 提取图有两种方式,类似hipporag的two step extraction,即先做NER,再做relation提取
* 第二种是一把提取,这里写是参考Medical-Graph-RAG的
* PassageGraph
* 节点是chunk,通过WAT去链接wiki title和chunk
* 对于同一个wiki title下的每一个chunk,连接边
* RKGGraph就是lightrag这些,带有entity/relation description的
* 这里和普通的KG区别就是,prompt里不仅会提取relation,也会提取relation的关键词
* 和ms一样,也有多轮提取提高抽取的质量的流程
* TreeGraph
* 据说是用GMM做效率太低了,并且算法原因有的结果跑不出来。所以改成了kmeans
* 主要区别就是kmeans里一个chunk只属于一个簇,GMM的话一个chunk属于多个簇。不过看起来效果也不差
* 实现细节:
* 有一个可配置的layer,会不断向上构建,直到layer中的节点数量过小
* 先通过kmeans做聚类,得到这一层的cluster
* summarize from cluster,总结信息,然后创建新的高层节点
* batch_embed_and_assign,对新的一层的节点做embedding,同时重新计算节点的index
- 额外的option
- enable_graph_augmentation
- 对相似的点进行连边,实体消歧
- use_entity_link_chunk
- 构建一个entity到relationship的矩阵
- 构建relationship到chunk的矩阵,这里是获取relationship的source id。后续hipporag中会用到
- enable_graph_augmentation
Retriever
使用的时候,这里是把config中定义的索引结构给retriever,比如graph/vdb
然后再把retriever丢给query。
retriever有type和method_name两种:
* 这里的type表示的是召回的内容,method表示的是召回的方式
* 比如ChunkRetriever,用来召回chunk,那么有通过ppr召回的,有通过entity召回的,有通过relation召回的
query中,通过retriever的retrieve_relevant_content就可以执行对应的召回方式了。
- chunk
- aug_ppr
- 这里传入就有seed entities,直接跑PPR
- 然后召回若干个点以及他们的重要性,乘上entity -> relationship的矩阵,得到边的强度矩阵。再乘上relation -> chunk的矩阵,就得到chunk的强度矩阵了。
- 根据这几个强度矩阵,可以排序chunk/entity/relationship,然后根据token做truncate即可
- ppr
- 有一个link entity的option,可以走vdb先召回一下seed entity
- 和上面aug的区别就是,这里只用了chunk,没有用entity/relation
- from_relation
- 给relation,获取relation对应的chunk,然后做truncate
- entity_occurrence
- 根据entity获取chunk,这里用了ms的根据entity计算chunk得分的算法。思路类似共现关系吧
- aug_ppr
- community
- from_level
- 根据config中的level做召回,会根据community中的occurrence做一下排序
- occurence是说,这个community包含的chunk越多,则越高
- from_entity
- 从entity获取对应的community,然后排序,根据token截断
- from_level
- entity
- vdb
- topk的向量搜索
- tf_df
- 把图上的点的description建立索引,用tf df来做查询。应该就是倒排+一些策略
- all/get_all
- 所有的点
- link_entity
- 和vdb的区别是就取top1
- from_relation_by_agent
- from_relation
- 通过边获取点
- by_neighbors
- 一跳邻居
- vdb
- mix
- 就是把其他类型的retriever放到一起了,因为需要有一个最上面的根结点的retriever来支持多路的retrieve
- relationship
- ppr
- 和上面entity的ppr类似,先通过seed entity跑ppr,然后用entity -> relation的矩阵,计算relation的概率,然后sort + topk
- vdb
- 和lightrag相同,用vdb直接召回相关的relation
- from_entity
- 获取entity关联的边,根据edge degree做排序
- edge degree是起点+终点的degree
- from_entity_by_agent
- 这里是ToG的做法,就是把一个点关联的relation给LLM,让他来判断哪些relation是和问题相关的,得到一个relation/score的list
- 这里有一个很变态的去重逻辑,不过感觉做的有点复杂,他这里不是直接的类似bfs那样去重,而是会考虑边的来源。而且只有一跳。所以估计如果出现循环,也是处理不了的

- 比如跳到普林斯顿大学的时候,不希望再回到爱因斯坦哪里了
- get_all
- 全查
- by_source&target
- 点查
- ppr
- subgraph
- concatenate_information_return_list
- 用subgraph vdb召回相关的subgraph
- 这里是chunk级别的,对应一个subgraph,会把他的边取出来,用文本形式表示图,写到vdb中(感觉应该没啥效果,这种结构化的数据语意应该是比较奇怪的)
- k_hop_return_set
- k hop子图
- induced_subgraph_return_networkx
- networkx提供的,给一个node list,获取子图
- paths_return_list
- 给定节点的list,探索这些节点之间的路径
- 为了避免开销过大会做bfs长度的限制
- neighbors_return_list
- 获取一跳邻居,当一跳邻居不足的时候,会获取与起始节点有交集的多跳邻居。
- 这里算法有点怪怪的,实际上如果邻居与起始节点有了交集,实际上相当于在起始节点上重新做多跳
- concatenate_information_return_list
Query
最外层的问答就是直接走的Query类的query接口。基本的query的方式:
* 通过retriever,获取上下文。retrieve_relevant_contexts
* 根据query的类别,把query和context传进去做问答,得到response
* 这里的context都是一个format好的string
* 这里有一些特殊的query方式,比如做COT的,就不是走的这个模板
- BasicQuery,LightRAG这一套
- 基于high level keywords去生成global context
- 基于low level keywords生成local context
- 也有走ms graphrag的,基于community生成global keywords
- RAPTOR式搜索,这里实际上是用向量召回相关的chunk
- DalkQuery
- 用NER提取query中的实体(和local search的关键词提取应该差不多)
- link_entity,用vdb提取高优的实体
- 用子图path的方式查询提取出来的实体对应的路径,然后会让LLM去做rerank,找到关键的路径
- neighbors_return_list查询邻居,然后让LLM做rerank
- 这里还会把上面得到的path/neighbors用LLM再去转化一下,把结构化信息转化成自然语言,最后再去问答
- GRQuery
- G-Retriever:
- 将检索建模为带权斯坦纳树问题(PCST),平衡相关性与子图规模,确保返回连通的解释性子图。
- 核心思路是:在图中选择一组连通的节点和边,使得它们的语义相关性(奖励)最大化,同时控制子图的规模(成本)
- 实现上比较复杂,而且看benchmark效果并不好,所以就先不看了
- G-Retriever:
- KGPQuery
- 用tf idf做的搜索,先搜索关联的chunk
- 然后针对每一个chunk,用llm问答,要回答这个query,可以利用到这个chunk中的什么信息。作为线索
- 对于每一个chunk来说,这里会搜索他的关联的chunk,然后根据上面llm给的线索,来计算关联的chunk的得分,排序截断后加入到context中
- MedQuery
- concatenate_information_return_list 搜索子图
- 再用vdb召回一些相关的实体
- 用上面得到的node list,做k hop子图的查询,继续扩充子图
- induced_subgraph_return_networkx,再把相关的边都拿出来。
- 然后整体作为context做问答,没什么特别的点
- PPRQuery
- 可以直接用aug_ppr,就是上面提到的不只是获取context,还可以把点边拿出来
- 另一种就是hippo rag的方法,用ppr获取相关的chunk
- 然后有一个多轮reason的步骤,给定query,之前的thought,以及召回的相关的文章,让LLM生成新的thought,用新的thought再去召回相关的文章
- ToGQuery
- NER提取实体,然后vdb link到实体上
- 然后做多轮,每一轮会根据当前的topic entity candicates去查询relation
- 然后根据relation查询实体
- 做问答,这里模型如果认为可以回答了,会主动stop,然后生成结果
- 如果无法继续问答,就会走下一轮,然后把上面刚刚召回的新的实体作为新一轮的topic entity candicates。
Index
- 抽象了召回类的索引,支持build/retrieval
- 支持ColBertIndex/FaissIndex
Community
这里就是实现了leiden的cluster + community report
是从nano graphrag中搞过来的
Provider
实现了openai相关的,通过供应商的名字做的支持。模型名字和url什么的都是通过配置来。
比如openai的就用openai sdk,zhipu的就用zhipu的sdk
然后这里就是用cost manager包了一下用量
以及一个限流的能力
Storage
- graph storage
- 存图相关的
- blob storage
- 这里是存hippo rag里用的矩阵,用来计算chunk得分的
- kv storage
- 存chunk/community report
- 其实还有一个vector db,只不过被放倒上面的index里了

文章评论