有一篇不错的知乎文章:https://zhuanlan.zhihu.com/p/688133363
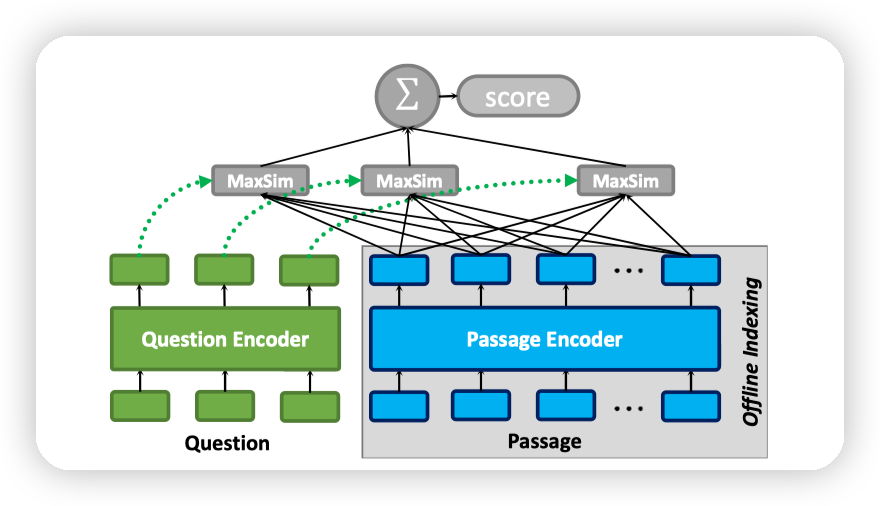
colbert的核心在于,为文档和query分别做编码。并且是token级别的编码
直观来讲是一种tradeoff,token级别的编码肯定存储空间会上升,带来的好处是细粒度的检索。
如果用过vector rag的人可能知道,vector rag的检索能力是非常弱的,文档长一点,很容易就召回一堆奇奇怪怪的东西。
这里让DS帮忙总结了一下colbert的优缺点,比较全面:
ColBERT的Late Interaction架构在信息检索中具有独特的优势和局限性,以下是详细分析:
优点
1. 细粒度语义匹配
- Token级交互:每个查询和文档的token独立编码为向量,通过逐token的最大相似度(MaxSim)计算相关性,捕捉局部语义匹配(如关键词、短语对齐)。
- 示例:
查询“如何训练深度神经网络?”与文档中的“深度学习模型训练步骤”可能通过“训练”和“模型”的token对齐获得高分,即使整体语义不完全匹配。
2. 离线索引加速检索
- 文档预编码:文档的token向量可提前离线计算并存储,搜索时仅需编码查询,显著降低实时计算开销。
- 适用性:适合大规模文档库(如Wikipedia、企业知识库)的快速检索。
3. 对噪声和部分匹配的鲁棒性
- 局部匹配主导:即使部分token不相关,其他token的高相似度仍可提升整体得分,避免单向量模型因全局平均而丢失关键信号。
4. 灵活性
- 支持长文本:通过截断或分块处理长文档,避免单向量模型因输入长度限制导致的语义稀释。
5. 与交叉编码器的互补性
- 两阶段检索:常用于“召回-精排”流程,先用ColBERT高效召回候选文档,再用交叉编码器精排,兼顾速度与精度。
缺点
1. 存储开销大
- 多向量存储:每个文档需存储所有token的向量(如128维),导致存储成本比单向量模型高1-2个数量级。
示例:
10亿token的文档库,单向量模型需约500GB,而ColBERT可能需要5TB+。
2. 计算复杂度较高
- MaxSim计算:查询与文档的token需两两计算相似度,时间复杂度为 O(N \times M)(N为查询token数,M为文档token数),长文档检索时延迟较高。
3. 信息冗余
- 局部匹配的局限性:过度依赖局部匹配可能忽略全局语义(如否定关系、长距离依赖)。
示例:
查询“不推荐使用的方法”可能与文档“推荐使用的方法”因“推荐”token相似度高而误判。
4. 对预训练模型的依赖
- BERT编码瓶颈:依赖预训练模型(如BERT)的质量,若领域差异大(如医学、法律),需额外微调。
5. 长尾词处理
- 低频token泛化差:罕见词或领域专有名词的向量表示可能不够准确,影响匹配效果。
总结
- 选择ColBERT当:
需要高精度检索、资源充足(存储/计算)、且查询与文档的局部语义对齐关键(如QA、长尾主题)。 - 避免ColBERT当:
资源严格受限、需极低延迟(如实时流式处理),或任务强调整体语义一致性(如文本分类)。
MaxSim

Encoder解耦
知乎文章里有提到,这种架构的另一个优势就是query/doc encoder可以是不一样的。
比如可以微调查询模型,针对不同领域的查询,只针对查询模型做微调。不需要动文档模型

其实这里并没有感觉和其他做法的区别,因为其他模型做了微调,应该也不至于把embedding模型搞烂。
所以我这里对知乎文章里的说法是持怀疑态度的
Rerank
这里还有一个好处,就是token级别的查询,相当于把关键词查询和语义查询都做了。在没有其他链路引入的情况下,就可以省略rerank的步骤。
个人感觉,这种精确的搜索在一些对性能要求没那么高的领域还是不错的。HippoRAG中有针对colbert做的实验,效果是有挺多提升的。
并且有比较好用的开源库colbert-ai,有时间的话可以考虑集成一下

文章评论