linux/list.h 简单解析
linux/list.h是linux内核中实现的链表部分
由于最近在看操作系统概念,第二章的编程练习是叫我们去写一个很简单的内核模块,其中涉及到了list.h的内容,书中也有推荐大家去看一看再完成项目
内核中的代码,至少list.h这里的代码写的还是十分易懂的,而且由于篇幅原因,这里只会介绍项目中会用到的简单的几个函数和宏
阅读本篇文章最好是自己也打开这个文件,跟着一起看效果才好
首先看链表结构的定义
struct list_head {
struct list_head *next, *prev;
};
我们发现和平常的链表有点区别,他没有储存数据的地方
看注释可以发现,这是一个循环双向链表
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
然后是最开始的三个函数
LIST_HEAD_INIT和LIST_HEAD配合使用,目的是定义一个节点,他的前驱节点和后继节点都是他自己
这个就是我们用来定义表头使用的东西了
下面一个INIT_LIST_HEAD,可以看到函数中有一个WRITE_ONCE,这个是linux内核安全读写的一个宏,这里我们只需要知道他的作用相当于list->next = list
那么这个函数的功能也比较清楚了,就是传入一个list_head的指针,将他的前驱和后继都设为自己
再往下看,可以发现有一个#ifdef CONFIG_DEBUG_LIST
这个是用来debug的,我们也不看他
再向下
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
这三个函数就涉及到了添加链表节点
无视掉那个__list_add_valid
可以发现,第一个add的功能就是把new节点插入到prev和next两个节点之间
第二个的功能是在表头插入一个节点
而第三个的功能就是在表的末尾插入一个节点,因为我们是循环链表,所以可以这样写
再向下看就是链表节点的删除
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
static inline void __list_del_clearprev(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = NULL;
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
第一个函数,传入的是要删除节点的前驱和后继,然后叫他们相互赋值,就相当于把中间的节点从链表中抹除了
第二个函数传入的是要删除的节点,同时他会将该节点的前驱设为NULL
第三个是加上了检查的删除
第四个的删除是不仅将这个节点从当前的链表中抹除了,还同时将当前节点的指针设置成了两个特殊的宏定义,目的应该是为了防止误访问到其他地方
那么说完了链表的增添和删除,我们最常用的就剩下链表的遍历了
这个也是最关键的一点,因为我们的节点中是没有数据的,那要怎么储存数据呢
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
看这个宏定义
然后我们再给出一个使用这个节点的例子
struct node {
int data;
struct list_head list;
}
node就是我们的节点,其中data就是数据,而list就是刚才讲的内核中的双向链表
通过看到这个container_of,以及list_entry的描述,我们大概就可以猜到要怎么做了
我们可以通过list_entry(ptr, node, list)来获得ptr对应的node指针,其中ptr是指向list_head的指针
有兴趣的同学也可以看看container_of的实现,就是通过指针的偏移获得了这个节点的指针
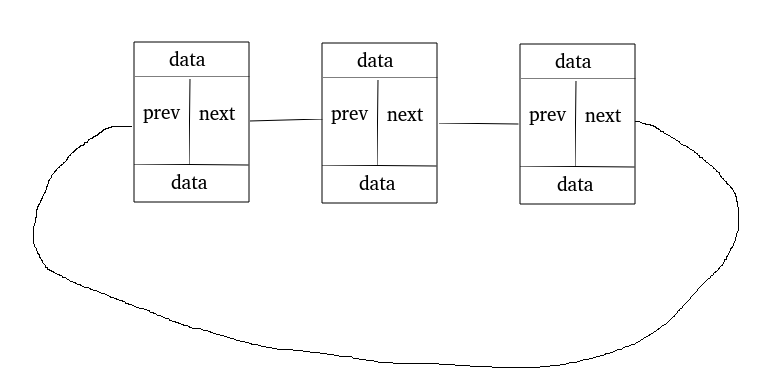
大概结构就是这样的
那么知道了这个以后,我们可以看遍历链表
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
其中list_first_entry和list_next_entry是获得链表的第一个节点,和获得当前节点的下一个节点,这里就不给出定义了,有兴趣的同学可以去看一下他们的实现,也相当简单
就是一个简单的for循环,从第一个节点开始,每次获取到下一个节点,直到回到头结点
值得一提的是,这个遍历有一个安全的版本
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member), \
n = list_next_entry(pos, member); \
&pos->member != (head); \
pos = n, n = list_next_entry(n, member))
类型安全版本的遍历,他需要我们多提供一个指针,用于提前保存下一个节点的位置,这样我们就可以在这个类型安全的遍历中删除所有的元素
基本的介绍就是这些了,有希望看到这些代码的用例的同学可以来我的github中看

文章评论