Motivation
虽然最先进的共享内存处理系统可以高效的处理图。但是缺乏可拓展性使得他们无法处理那些单台机器无法承载的图。而分布式解决方案虽然可以将图拓展到更大的规模。但是他们的性能和成本效率往往不是很好
一个对于前沿系统的比较
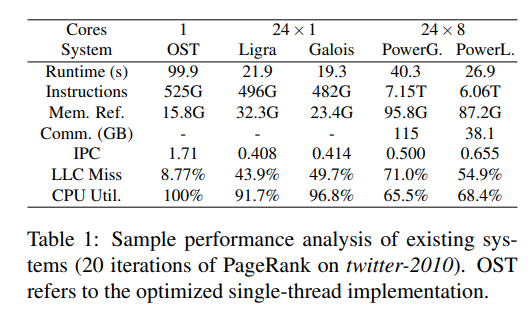
可以发现分布式系统的网络没有饱和。限制他的主要因素是计算而非通信
与共享内存系统相比,他们执行了更多的额指令,更多的内存引用,更差的局部性以及多核利用率低。这种低效性有多个来源:(1)通过hashmap来在全局和局部状态间转换vertexID,(2)维护顶点的副本,(3)在GAS中的communication-bound apply phase,(4)动态调度
Gemini Graph Processing Abstraction
graph processing problem updates information stores in vertices, while edges are viewed as immutable objects.
undirected edges could be replaced with a pair of directed edges.
For a common graph hprocessing application, the processing is done by propagating vertex updates along the edges, until the graph state converges or a given number of iterations are completed.
正在更新的顶点叫活跃顶点,他们的出边构成了活跃边集
Dual Update Propagation Model
图处理的时候,活动边集的可能是密集的或者稀疏的。通常由活动顶点传出边的总数决定。
比如CC(connected components)在最开始的时候活动边集是密集的,但是会随着顶点接收到其最终标签变得越来越稀疏。SSSP(单元最短路)从一个稀疏的边集开始的,当更多的顶点被其邻居激活的时候,他会变的更加密集,当算法收敛时他会再次变得稀疏
稀疏情况下,更适合用push模型(每个点通过其出边来更新对应的点),因为我们只需要遍历活动顶点传出来的边
密集的情况下,则更适合用pull模型(每个顶点的更新通过入边来收集相邻顶点的信息),因为这样可以减少通过锁或者原子操作更新顶点时的争用
在gemini系统中,graph会被partition在多个不同的节点上,信息的传递和更新是通过显示的message passing。
gemini使用master mirror的概念,每一个节点被分配给一个分区,在该分区中他是master vertex,作为维护顶点状态数据的主副本。同一个顶点会有多个副本,称为mirror,每一个mirror对应的分区上都至少拥有一个他的邻居。每个master-mirror pair之间有一条双向边,但是在任意一个传播模式下只使用一条。同时gemini的mirror不存储真实数据,只是占位符。
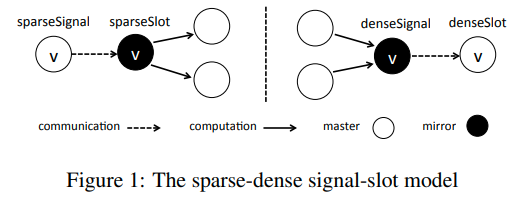
signals和slots用来表示user-defined vertex-centric function,用来描述发送和接受信息的行为
figure1中是两种模式下的操作

论文中这块有点怪怪的,我没太看懂为什么复杂度降低到了vertex数量
Distributed Graph Representation
在部署gemini的时候,graph必须进行partition
比如vertex-centric,即将顶点和相关数据均匀的分配到每个节点上
或者edge-centric,即将边均匀分配,并复制对应的点
Chunk-Based Partitioning
inspiration就是现实世界中很多的graph都是具有天然的locality的,因为我们一般是用爬虫去获得这些图
所以相邻的顶点就更有可能被存储到一起
即便是输入的数据的局部性丢失了,我们也可以通过其拓扑结构来恢复局部性
gemini将图划分成p个连续的顶点块(v0, v1, ....,vp - 1)
其中vi表示的是分区i拥有的顶点(master顶点)
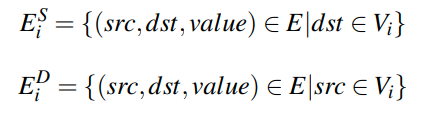
比较反直觉的一点是出边集指的是终点在vi的边集,入边集则是起点在vi的边集
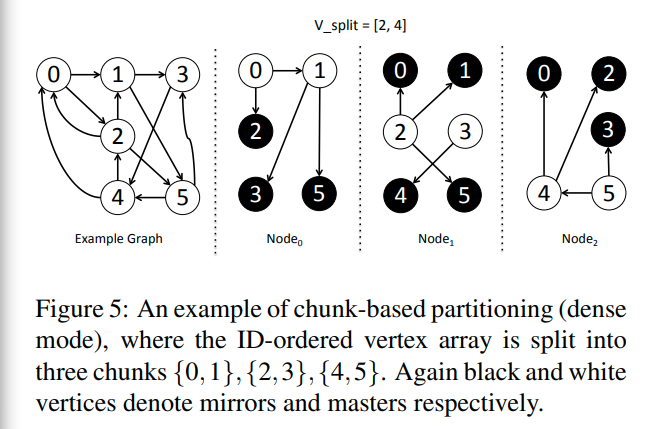
figure5是一个dense mode的划分,可以看到边都是从master指向mirror的。每一个mirror都会在本地收集数据,并发送给master节点
比如2号点,在p0和p2就会分别收集来自0和4的信息,并发送给在p1的master
这种连续的分区还简化了顶点数据的表示,每个node上的内存中只分配了他拥有的那部分顶点数组。我们不需要额外的进行顶点ID转化来压缩顶点状态的空间消耗
chunk-based partition可以保存顶点访问的局部性
他原文里有一句这么写Gemini can then benefit from chunk-based partitioning when the system scales out, where random accesses could be handled more efficiently as the chunk size decreases,我的猜测是当chunk size变小的时候,我们的random access的范围就会变小,从而增强了局部性。(但是缺点是需要更多的master-mirror进行通信了,很直观,因为信息沿边传输是必须的,当每个机器内部负责的沿边传输少了,我们自然需要更多的网络通信)
Dual-Mode Edge Representation
gemini对于入边集使用的是CSR(Compressed Sparse Row)来存储
对于出边集则是CSC(Compressed Sparse Column)
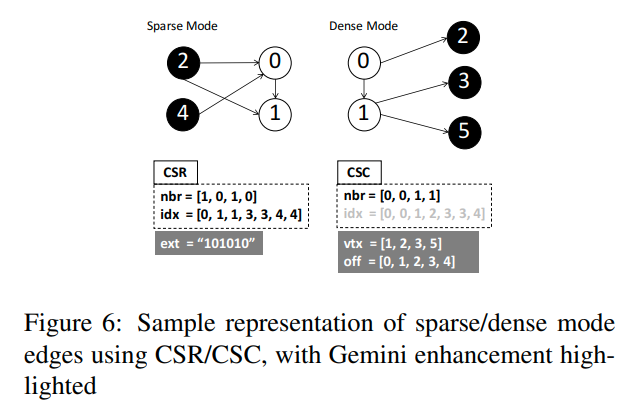
这里是对于上面figure5的一个表示
idx数组记录了每一个vertex的边的分布。对于vertex[i]来说,idx[i]和idx[i+1]构成了这个节点在这个分区中的边。
nbr数组表示这些边的邻居(对于入边就是source,出边就是destination)
可以看到,当提高分区数的时候,我们的nbr会减少,因为我们只存了这个分区对应的边。但是对于vertex来说,他是不变的,仍然是O(V)的
引入两种优化的策略
- Bitmap Assisted Compressed Sparse Row: 引入bitmap ext作为检查,表示当前的这个节点是否有出边
- Doubly Compressed Sparse Column: 对于dense mode,只存储有入边的vertex(vtx),以及他们对应的offset(off)
我好奇为什么sparse模式下不用Doubly Compressed这种方法来压缩呢?是因为push这个操作是异步的吗?如果v很大的情况下用一个hashmap也比这样存好一些吧
Locality-Aware Chunking
gemini的chunk-based partition是vertex-centric,但是由于现实世界图数据的幂律分布,会导致load balance比较差的情况
然而在chunk-based partition中,即便是我们均分edge,也会导致显著的负载不均衡。因为顶点访问的局部性在不同的分区中有着显著的差异,这是由于顶点数量的差异较大导致的。
gemini使用了一种locality-aware的分区方法。每一个partition都有一个均衡的数值 α · |Vi| + |EDi|。a是一个可以配置的数。所以我们希望a * 顶点数 + 出边数尽量均衡
intuition就是对于计算的复杂度,我们对于顶点和边都要考虑。E会影响我们的工作量,而V则会影响局部性
Question:V的数量导致的局部性影响这么大吗?
NUMA-Aware Sub-Partitioning
gemini通过recursively apply sub-partitioning来进行NUMA-Aware的子分区
对于一个拥有s个socket的node,我们可以继续分区为s个sub-chunk。而edge则会分配到对应的socket中,通过和inter-node一样的方法。
通过sub-partition,顺序的边访问和随机的点访问都很可能是在本地memory中进行,从而提高了LLC的利用率以及加快了访存的速度。
Task Scheduling
Bulk Synchronous Parallel的示例
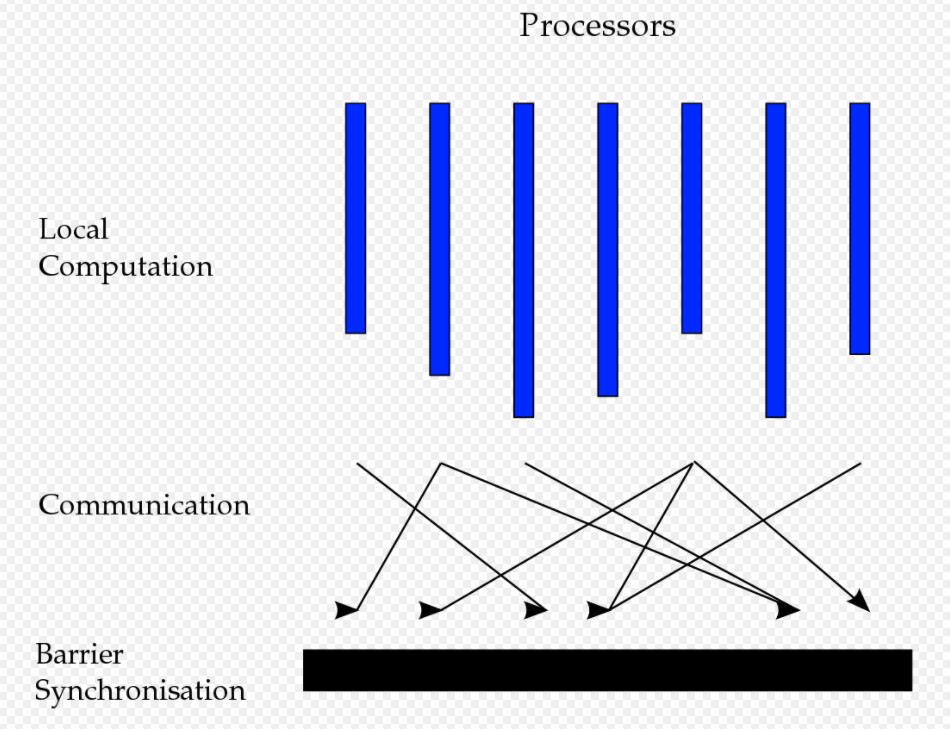
即Computation, Communication,以及Synchronous
gemini使用了BSP这种模型。对于每次迭代来说,gemini通过cyclic ring order来重叠计算和通信。在节点内部,gemini使用细粒度的work-stealing scheduler来达到动态的负载均衡
Co-Scheduling of Computation and Communication Tasks
对于拥有c个core的节点,gemini维护一个有c个thread的OpenMP pool,用来进行edge processing
2个额外的thread用来进行inter-node message sending/receiving
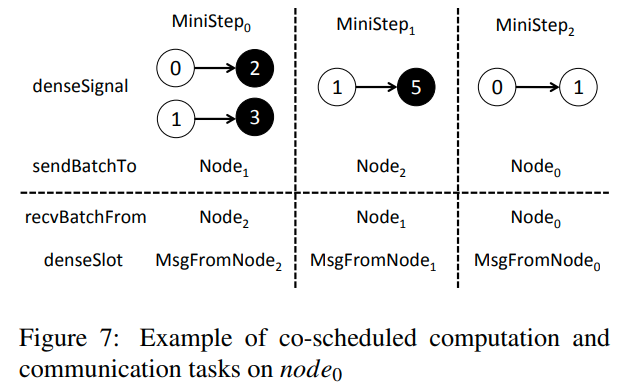
每一个iteration会被划分为p个mini-step
在figure7中,是node0的例子。他会与node0, 1, 2进行communicate
在每一个mini-step中,节点都会进行本地的denseSignal,message send/receive, denseSlot
在第一个mini-step中,本地的2和3做pull updates,从节点0和1获得信息(signal)。然后创建一个batch的消息发送给node1。然后node0会等待来自node2的信息,并执行denseSlot,更新本地的节点
计算和通信重叠的意思指的是,当一个节点计算完毕传输给下一个节点的时候,他是可以开始下一步计算的。这样可以充分利用网络和CPU资源
Fine-Grained Work-Stealing
当partition越来越小的时候,我们就很难通过调整a来保证负载均衡了
所以gemini为节点内部的任务实现了细粒度的work-stealing
最开始在socket之间进行locality-aware的划分。每一个线程每次只拿一个小chunk进行处理。每个线程都会首先完成他对应的per-core task,然后开始从其他的线程上偷mini-chunk
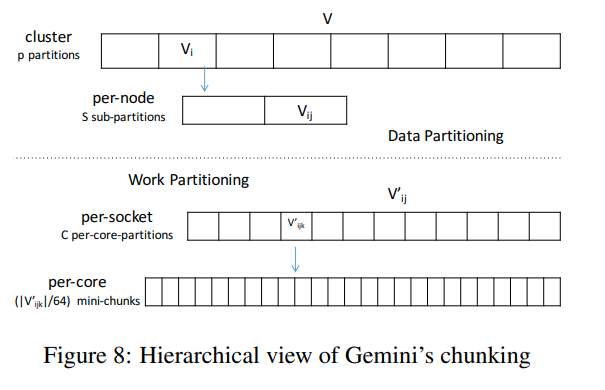
每个socket上有若干个core,每个core有若干个mini-chunk,当一个core执行完以后就可以尝试去其他人哪里steal task
之所以用steal-work而不是交错划分mini-chunk,是因为steal-work具有更好的局部性,并且缓解了原子加的争用

文章评论