Daily C/C++ 随机数生成
今天这篇文章主要讲一下新版本中C++的随机数生成
那具体有关理论部分这里就不细说了,主要说平常我们怎么用
参考文章自然就是cppreference了,大家可以自行查阅,在cppreference中搜random就行
那么可以看到,C++中的随机数库提供了两种东西,分别为均匀随机位生成器和随机数分布
那么随机位生成器就是用来生成一个随机数的,而随机数分布则是用给定的生成器生成对应的分布
根据介绍我们可以发现,随机位生成器是函数对象,那么也就是说我们用的是其作为函数的性质,即关注operator()。
他返回的是一个无符号整数值,就是我们的随机数
随机位生成器包含随机数引擎,这些引擎就会以一定的算法来生成随机数。以及随机数引擎适配器,这个貌似用的不多,在这里就不说了
库中还提供了一系列的预定义的随机数生成器,比如我们常见的mt19937等,他们是以一定的参数特化了随机数引擎得到的。
那么最后还有非确定随机数,这个其实就是真-随机数,即random_device
其实上面的随机位生成器也只是一些特定的算法,也就是说如果你给他固定的参数,那么他就会给出相同的输出,即伪随机的。所以需要我们有一个真随机的数来作为种子帮助引擎生成随机数,这就是random_device的作用
当然,random_device作为一个随机位生成器,自然也是用来得到随机数的,如果硬件设备是支持随机数源的,那么我们就可以得到真的随机数,否则的话我们也只会得到伪随机序列
这里也会涉及到linux熵池的概念,就是说random_device会使用linux的熵池来得到随机数,当我们调用次数过多的时候,熵池耗尽,那么随机数质量也会下降。
所以他的作用一般是用来播种随机数引擎,再用随机数引擎来生成随机数。
而对于熵池,貌似是linux会记录一些随机的信息储存在熵池中,比如鼠标两次点击间隔等,这样就可以让我们得到一些真随机的信息
说完随机数生成,接着就是随机数分布了,其实就是定义了我们常见的一些分布,最常用的有均匀分布,正态分布等
我们只需要给定这个分布的参数,然后将随机数引擎传进入就可以得到对应分布的随机数
看cppreference给出的一段代码示例
int main()
{
// 以随机值播种,若可能
std::random_device r;
// 选择 1 与 6 间的随机数
std::default_random_engine e1(r());
std::uniform_int_distribution<int> uniform_dist(1, 6);
int mean = uniform_dist(e1);
std::cout << "Randomly-chosen mean: " << mean << '\n';
// 生成围绕平均值的正态分布
std::seed_seq seed2{r(), r(), r(), r(), r(), r(), r(), r()};
std::mt19937 e2(seed2);
std::normal_distribution<> normal_dist(mean, 2);
std::map<int, int> hist;
for (int n = 0; n < 10000; ++n) {
++hist[std::round(normal_dist(e2))];
}
std::cout << "Normal distribution around " << mean << ":\n";
for (auto p : hist) {
std::cout << std::fixed << std::setprecision(1) << std::setw(2)
<< p.first << ' ' << std::string(p.second/200, '*') << '\n';
}
}
可能的输出:
可以看到第一个例子就是用random_device来播种引擎,然后再给随机数分布来生成随机数
下面第二个则是random库中的一个工具,消耗整数值序列并生成给定数量的随机数
而可以看到我们常用的mt19937就使用了这个种子序列来初始化
但是我们也可以用一个随机数来初始化这个引擎,看到他的构造函数
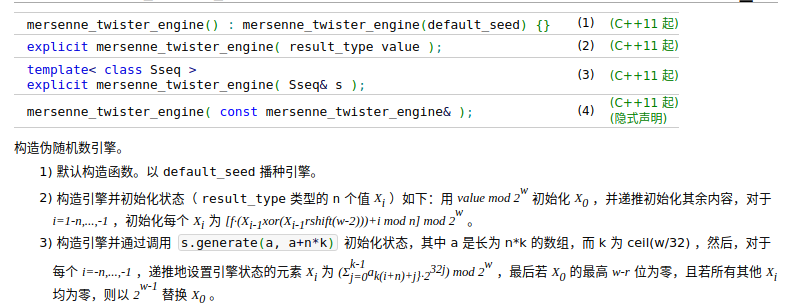
可以看到第三个构造函数是使用种子序列,而第二个构造函数就是使用随机数来构造,同时也可以看到具体的算法。
所以学完这一章大家就可以抛弃掉之前的rand()库函数了,来使用更加强大的随机数吧。
最后一个小tip,构造随机数引擎是一个十分耗费时间的举动,所以我们需要大量使用的时候最好不要现用现构造,可以声明为静态变量或者成员变量。具体可以看我计算机图形学中path tracing的实现

文章评论